基于SolrCloud的内容搜索和热点推送
版权声明:此文章如需转载请联系听云College团队成员阮小乙,邮箱:ruanqy#tingyun.com
什么是热点
我认为热点有时效性和受众面
用户关注从低到高再到低的内容 。有公共热点和分类热点。例如医辽养老全民关注,科技汽车等只有特定的人群关注。
推送的条件
搜索频次达到一定数量
单位时间内搜索频次上升一定倍数。例如1000一周内达到100万,这样就达到推送标准了。
问题背景
自动提示功能是所有搜索应用的标准配置,目的主要有两个
1.提供更好的用户体验,降低输入的复杂度。
2.避免用户输入错误的词,将用户的输入引导向正确的词。弱化同义词处理的重要性
需求分析
-
海量数据的快速搜索
-
支持自动提示功能
-
支持自动纠错
-
在输入舌尖时,要自动提示舌尖上的中国,舌尖上的小吃等
-
支持拼音和缩写笔错拼例如shejian sjsdzg shenjianshang shejiashang
-
查询记录,按照用户的搜索历史优先上排查询频率最高的。
-
分类热点进行推送
解决方案
索引
Solr的全文件检索有两步
1、创建索引
2、搜索索引
索引是如何创建的又是如何查找的?
Solr采用的一种策略是倒排索引,什么是倒排索引。Solr的倒排索引是如何实现的
大家参考以下三篇文章写的很全。
http://www.cnblogs.com/
forfuture1978/p/3940965.html
http://www.cnblogs.com/
forfuture1978/p/3944583.html
http://www.cnblogs.com/
forfuture1978/p/3945755.html
汉字转拼音
用户输入的关键字可能是汉字、数字,英文,拼音,特殊字符等等,由于需要实现拼音提示,我们需要把汉字转换成拼音,java中考虑使用pinyin4j组件实现转换。
拼音缩写提取
考虑到需要支持拼音缩写,汉字转换拼音的过程中,顺便提取出拼音缩写,如“shejian”,--->"sj”。
自动提示功能
方案一:
在solr中内置了智能提示功能,叫做Suggest模块,该模块可选择基于提示词文本做智能提示,还支持通过针对索引的某个字段建立索引词库做智能提示。使用说明http://wiki.apache.org/solr/Suggester
Suggest存在一些问题,它完全使用freq排序算法,返回的结果完全基于索引中出现的次数,没有兼容搜索的频率,但是我们必须要得到搜索的频率。
我们可以定制SuggestWordScoreComparator重写compare(SuggestWord first, SuggestWord second)方法来实现自己的排序算法。笔者使用了搜索频率和freq权重7:3的方式
方案二:
我们考虑专门为关键字建立一个索引collection,利用solr前缀查询实现。solr中的copyField能很好解决我们同时索引多个字段(汉字、pinyin, abbre)的需求,且field的multiValued属性设置为true时能解决同一个关键字的多音字组合问题。配置如下:
schema.xml:
<field name="keyword" type="string" indexed="true" stored="true" /> <field name="pinyin" type="string" indexed="true" stored="false" multiValued="true"/> <field name="abbre" type="string" indexed="true" stored="false" multiValued="true"/> <field name="kwfreq" type="int" indexed="true" stored="true" /> <field name="_version_" type="long" indexed="true" stored="true"/> <field name="suggest" type="suggest_text" indexed="true" stored="false" multiValued="true" /> <!--multiValued表示字段是多值的--> <uniqueKey>keyword</uniqueKey> <defaultSearchField>suggest</defaultSearchField> <copyField source="kw" dest="suggest" /> <copyField source="pinyin" dest="suggest" /> <copyField source="abbre" dest="suggest" /> <!--suggest_text--> <fieldType name="suggest_text" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true"> <analyzer type="index"> <tokenizer class="solr.KeywordTokenizerFactory" /> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true" /> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" /> <filter class="solr.LowerCaseFilterFactory" /> <filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt" /> </analyzer> <analyzer type="query"> <tokenizer class="solr.KeywordTokenizerFactory" /> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" /> <filter class="solr.LowerCaseFilterFactory" /> <filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt" /> </analyzer> </fieldType>
SpellCheckComponent拼写纠错
拼写检查的核心是求相似度
两个给定字符串S1和S2的Jaro Distance为:
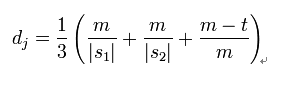
-
m是匹配的字符数;
-
t是换位的数目。
两个分别来自S1和S2的字符如果相距不超过 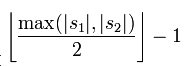 时,我们就认为这两个字符串是匹配的;而这些相互匹配的字符则决定了换位的数目t,简单来说就是不同顺序的匹配字符的数目的一半即为换位的数目t,举例来说,MARTHA与MARHTA的字符都是匹配的,但是这些匹配的字符中,T和H要换位才能把MARTHA变为MARHTA,那么T和H就是不同的顺序的匹配字符,t=2/2=1.
时,我们就认为这两个字符串是匹配的;而这些相互匹配的字符则决定了换位的数目t,简单来说就是不同顺序的匹配字符的数目的一半即为换位的数目t,举例来说,MARTHA与MARHTA的字符都是匹配的,但是这些匹配的字符中,T和H要换位才能把MARTHA变为MARHTA,那么T和H就是不同的顺序的匹配字符,t=2/2=1.
那么这两个字符串的Jaro Distance即为:
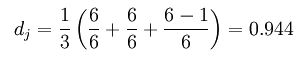
而Jaro-Winkler则给予了起始部分就相同的字符串更高的分数,他定义了一个前缀p,给予两个字符串,如果前缀部分有长度为 的部分相同,则Jaro-Winkler Distance为:
-
dj是两个字符串的Jaro Distance
-
 是前缀的相同的长度,但是规定最大为4
是前缀的相同的长度,但是规定最大为4 -
p则是调整分数的常数,规定不能超过0.25,不然可能出现dw大于1的情况,Winkler将这个常数定义为0.1
这样,上面提及的MARTHA和MARHTA的Jaro-Winkler Distance为:
dw = 0.944 + (3 * 0.1(1 − 0.944)) = 0.961
以上资料来源于维基百科:
http://en.wikipedia.org/wiki/Jaro-Winkler_distance
solr内置了自动纠错的实现spellchecker
我们来分析一下spellchecker的源码
package org.apache.lucene.search.spell; import java.io.Closeable; import java.io.IOException; import java.util.ArrayList; import java.util.Comparator; import java.util.Iterator; import java.util.List; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.document.Field.Store; import org.apache.lucene.document.FieldType; import org.apache.lucene.document.StringField; import org.apache.lucene.index.AtomicReader; import org.apache.lucene.index.AtomicReaderContext; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.FieldInfo.IndexOptions; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.index.IndexWriterConfig.OpenMode; import org.apache.lucene.index.Term; import org.apache.lucene.index.Terms; import org.apache.lucene.index.TermsEnum; import org.apache.lucene.search.BooleanClause; import org.apache.lucene.search.BooleanClause.Occur; import org.apache.lucene.search.BooleanQuery; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TermQuery; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.AlreadyClosedException; import org.apache.lucene.store.Directory; import org.apache.lucene.util.BytesRef; import org.apache.lucene.util.BytesRefIterator; import org.apache.lucene.util.Version; public class SpellChecker implements Closeable { /* * DEFAULT_ACCURACY表示默认的最小分数 * SpellCheck会对字典里的每个词与用户输入的搜索关键字进行一个相似度打分 * 默认该值是0.5,相似度分值范围是0到1之间,数字越大表示越相似。 */ public static final float DEFAULT_ACCURACY = 0.5F; public static final String F_WORD = "word"; //拼写索引目录 Directory spellIndex; //前缀ngram权重 private float bStart = 2.0F; //后缀ngram的权重 private float bEnd = 1.0F; //ngram算法:该算法基于这样一种假设,第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。 //简单说ngram就是按定长来分割字符串成多个Term 例如 abcde 3ngram分会得到 abc bcd cde ,4ngram会得到abcd bcde //索引的查询器对象 private IndexSearcher searcher; private final Object searcherLock = new Object(); private final Object modifyCurrentIndexLock = new Object(); private volatile boolean closed = false; private float accuracy = 0.5F; private StringDistance sd; private Comparator<SuggestWord> comparator; public SpellChecker(Directory spellIndex, StringDistance sd) throws IOException { this(spellIndex, sd, SuggestWordQueue.DEFAULT_COMPARATOR); } public SpellChecker(Directory spellIndex) throws IOException { this(spellIndex, new LevensteinDistance()); } public SpellChecker(Directory spellIndex, StringDistance sd, Comparator<SuggestWord> comparator) throws IOException { setSpellIndex(spellIndex); setStringDistance(sd); this.comparator = comparator; } public void setSpellIndex(Directory spellIndexDir) throws IOException { synchronized (this.modifyCurrentIndexLock) { ensureOpen(); if (!DirectoryReader.indexExists(spellIndexDir)) { IndexWriter writer = new IndexWriter(spellIndexDir, new IndexWriterConfig(Version.LUCENE_CURRENT, null)); writer.close(); } swapSearcher(spellIndexDir); } } public void setComparator(Comparator<SuggestWord> comparator) { this.comparator = comparator; } public Comparator<SuggestWord> getComparator() { return this.comparator; } public void setStringDistance(StringDistance sd) { this.sd = sd; } public StringDistance getStringDistance() { return this.sd; } public void setAccuracy(float acc) { this.accuracy = acc; } public float getAccuracy() { return this.accuracy; } public String[] suggestSimilar(String word, int numSug) throws IOException { return suggestSimilar(word, numSug, null, null, SuggestMode.SUGGEST_WHEN_NOT_IN_INDEX); } public String[] suggestSimilar(String word, int numSug, float accuracy) throws IOException { return suggestSimilar(word, numSug, null, null, SuggestMode.SUGGEST_WHEN_NOT_IN_INDEX, accuracy); } public String[] suggestSimilar(String word, int numSug, IndexReader ir, String field, SuggestMode suggestMode) throws IOException { return suggestSimilar(word, numSug, ir, field, suggestMode, this.accuracy); } /* * 核心重点 */ public String[] suggestSimilar(String word, int numSug, IndexReader ir, String field, SuggestMode suggestMode, float accuracy) throws IOException { IndexSearcher indexSearcher = obtainSearcher(); try { if ((ir == null) || (field == null)) { //SuggestMode.SUGGEST_ALWAYS永远建议 suggestMode = SuggestMode.SUGGEST_ALWAYS; } if (suggestMode == SuggestMode.SUGGEST_ALWAYS) { ir = null; field = null; } int lengthWord = word.length(); int freq = (ir != null) && (field != null) ? ir.docFreq(new Term(field, word)) : 0; int goalFreq = suggestMode == SuggestMode.SUGGEST_MORE_POPULAR ? freq : 0; // freq > 0表示用记搜索的关键词在SuggestMode.SUGGEST_WHEN_NOT_IN_INDEX为空,才提供建议 if ((suggestMode == SuggestMode.SUGGEST_WHEN_NOT_IN_INDEX) && (freq > 0)) { return new String[] { word }; } BooleanQuery query = new BooleanQuery(); for (int ng = getMin(lengthWord); ng <= getMax(lengthWord); ng++) { String key = "gram" + ng; String[] grams = formGrams(word, ng); if (grams.length != 0) { if (this.bStart > 0.0F) { add(query, "start" + ng, grams[0], this.bStart); } if (this.bEnd > 0.0F) { add(query, "end" + ng, grams[(grams.length - 1)], this.bEnd); } for (int i = 0; i < grams.length; i++) { add(query, key, grams[i]); } } } int maxHits = 10 * numSug; ScoreDoc[] hits = indexSearcher.search(query, null, maxHits).scoreDocs; SuggestWordQueue sugQueue = new SuggestWordQueue(numSug, this.comparator); int stop = Math.min(hits.length, maxHits); SuggestWord sugWord = new SuggestWord(); for (int i = 0; i < stop; i++) { sugWord.string = indexSearcher.doc(hits[i].doc).get("word"); if (!sugWord.string.equals(word)) { sugWord.score = this.sd.getDistance(word, sugWord.string); //求关键字和索引中的Term的相似度 if (sugWord.score >= accuracy) { if ((ir != null) && (field != null)) { sugWord.freq = ir.docFreq(new Term(field, sugWord.string)); //如果相似度小于设置的默认值则也不返回 if (((suggestMode == SuggestMode.SUGGEST_MORE_POPULAR) && (goalFreq > sugWord.freq)) || (sugWord.freq < 1)) { } } else { //条件符合那就把当前索引中的Term存入拼写建议队列中 //如果队列满了则把队列顶部的score(即相似度)缓存到accuracy即该值就表示了当前最小的相似度值, //当队列满了,把相似度最小的移除 sugQueue.insertWithOverflow(sugWord); if (sugQueue.size() == numSug) { accuracy = ((SuggestWord) sugQueue.top()).score; } sugWord = new SuggestWord(); } } } } String[] list = new String[sugQueue.size()]; for (int i = sugQueue.size() - 1; i >= 0; i--) { list[i] = ((SuggestWord) sugQueue.pop()).string; } return list; } finally { releaseSearcher(indexSearcher); } } private static void add(BooleanQuery q, String name, String value, float boost) { Query tq = new TermQuery(new Term(name, value)); tq.setBoost(boost); q.add(new BooleanClause(tq, BooleanClause.Occur.SHOULD)); } private static void add(BooleanQuery q, String name, String value) { q.add(new BooleanClause(new TermQuery(new Term(name, value)), BooleanClause.Occur.SHOULD)); } /* * 根据ng的长度对text字符串进行 ngram分词 */ private static String[] formGrams(String text, int ng) { int len = text.length(); String[] res = new String[len - ng + 1]; for (int i = 0; i < len - ng + 1; i++) { res[i] = text.substring(i, i + ng); } return res; } public void clearIndex() throws IOException { synchronized (this.modifyCurrentIndexLock) { ensureOpen(); Directory dir = this.spellIndex; IndexWriter writer = new IndexWriter(dir, new IndexWriterConfig(Version.LUCENE_CURRENT, null).setOpenMode(IndexWriterConfig.OpenMode.CREATE)); writer.close(); swapSearcher(dir); } } public boolean exist(String word) throws IOException { IndexSearcher indexSearcher = obtainSearcher(); try { return indexSearcher.getIndexReader().docFreq(new Term("word", word)) > 0; } finally { releaseSearcher(indexSearcher); } } /* * 这个比较难理解 */ public final void indexDictionary(Dictionary dict, IndexWriterConfig config, boolean fullMerge) throws IOException { synchronized (this.modifyCurrentIndexLock) { ensureOpen(); Directory dir = this.spellIndex; IndexWriter writer = new IndexWriter(dir, config); IndexSearcher indexSearcher = obtainSearcher(); List<TermsEnum> termsEnums = new ArrayList(); //读取索引目录 IndexReader reader = this.searcher.getIndexReader(); if (reader.maxDoc() > 0) { //加载word域上的所有Term存入TermEnum集合 for (AtomicReaderContext ctx : reader.leaves()) { Terms terms = ctx.reader().terms("word"); if (terms != null) { termsEnums.add(terms.iterator(null)); } } } boolean isEmpty = termsEnums.isEmpty(); try { //加载字典文件 BytesRefIterator iter = dict.getEntryIterator(); BytesRef currentTerm; //遍历字典文件里的每个词 while ((currentTerm = iter.next()) != null) { String word = currentTerm.utf8ToString(); int len = word.length(); if (len >= 3) { if (!isEmpty) { Iterator i$ = termsEnums.iterator(); for (;;) { if (!i$.hasNext()) { break label235; } //遍历索引目录里word域上的每个Term TermsEnum te = (TermsEnum)i$.next(); if (te.seekExact(currentTerm)) { break; } } } label235: //通过ngram分成多个Term Document doc = createDocument(word, getMin(len), getMax(len)); //将字典文件里当前词写入索引 writer.addDocument(doc); } } } finally { releaseSearcher(indexSearcher); } if (fullMerge) { writer.forceMerge(1); } writer.close(); swapSearcher(dir); } } private static int getMin(int l) { if (l > 5) { return 3; } if (l == 5) { return 2; } return 1; } private static int getMax(int l) { if (l > 5) { return 4; } if (l == 5) { return 3; } return 2; } private static Document createDocument(String text, int ng1, int ng2) { Document doc = new Document(); Field f = new StringField("word", text, Field.Store.YES); doc.add(f); addGram(text, doc, ng1, ng2); return doc; } private static void addGram(String text, Document doc, int ng1, int ng2) { int len = text.length(); for (int ng = ng1; ng <= ng2; ng++) { String key = "gram" + ng; String end = null; for (int i = 0; i < len - ng + 1; i++) { String gram = text.substring(i, i + ng); FieldType ft = new FieldType(StringField.TYPE_NOT_STORED); ft.setIndexOptions(FieldInfo.IndexOptions.DOCS_AND_FREQS); Field ngramField = new Field(key, gram, ft); doc.add(ngramField); if (i == 0) { Field startField = new StringField("start" + ng, gram, Field.Store.NO); doc.add(startField); } end = gram; } if (end != null) { Field endField = new StringField("end" + ng, end, Field.Store.NO); doc.add(endField); } } } private IndexSearcher obtainSearcher() { synchronized (this.searcherLock) { ensureOpen(); this.searcher.getIndexReader().incRef(); return this.searcher; } } private void releaseSearcher(IndexSearcher aSearcher) throws IOException { aSearcher.getIndexReader().decRef(); } private void ensureOpen() { if (this.closed) { throw new AlreadyClosedException("Spellchecker has been closed"); } } public void close() throws IOException { synchronized (this.searcherLock) { ensureOpen(); this.closed = true; if (this.searcher != null) { this.searcher.getIndexReader().close(); } this.searcher = null; } } private void swapSearcher(Directory dir) throws IOException { IndexSearcher indexSearcher = createSearcher(dir); synchronized (this.searcherLock) { if (this.closed) { indexSearcher.getIndexReader().close(); throw new AlreadyClosedException("Spellchecker has been closed"); } if (this.searcher != null) { this.searcher.getIndexReader().close(); } this.searcher = indexSearcher; this.spellIndex = dir; } } IndexSearcher createSearcher(Directory dir) throws IOException { return new IndexSearcher(DirectoryReader.open(dir)); } boolean isClosed() { return this.closed; } } 以上我们就建立的一个符合要求的检索功能,然后再从中筛选热点,根据用户画像分类推送就可以了。
想阅读更多技术文章,请访问听云技术博客,访问听云官方网站感受更多应用性能优化魔力。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

