Apache Flink源码解析之stream-sink
上一篇我们谈论了Flink stream source,它作为流的数据入口是整个DAG(有向无环图)拓扑的起点。那么与此对应的,流的数据出口就是跟source对应的 Sink 。这是我们本篇解读的内容。
SinkFunction
跟 SourceFunction 对应,Flink针对Sink的根接口被称为 SinkFunction 。继承自 Function 这一标记接口。 SinkFunction 接口只提供了一个方法:
void invoke(IN value) throws Exception;
该方法提供基于记录级别的调用(也就是每个被输出的记录都会调用该接口一次)。上面方法的参数 value 即为需要输出的记录。
SinkFunction 相对来说比较简洁,下面我们来看一下它的实现者。
内置的SinkFunction
同样,我们先来看一下完整的类型继承体系:
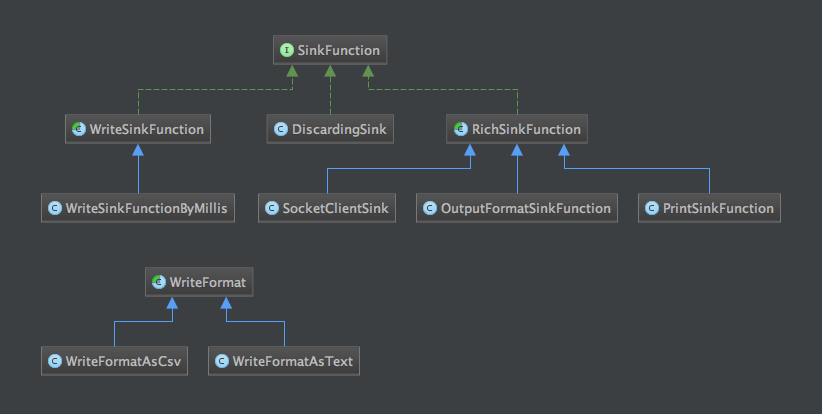
DiscardingSink
这是最简单的SinkFunction的实现,它的实现等同于没有实现(其实现为 空方法 )。它的作用就是将记录 丢弃 掉。它的主要场景应该是那些无需最终处理结果的记录。
WriteSinkFunction
WriteSinkFunction 是一个抽象类。该类的主要作用是将需要输出的 tuples (元组)作为简单的文本输出到指定路径的文件中去,元组被收集到一个list中去,然后周期性得写入文件。
WriteSinkFunction 的构造器接收两个参数:
- path : 需要写入的文件路径
- format :
WriteFormat的实例,用于指定写入数据的格式
在构造器中,它调用方法 cleanFile ,该方法用于初始化指定path的文件。初始化的行为是: 如果不存在则创建,如果存在则清空 。
invoke方法的实现:
public void invoke(IN tuple) {
tupleList.add(tuple);
if (updateCondition()) {
format.write(path, tupleList);
resetParameters();
}
}
从实现来看,其先将需要sink的元组加入内部集合。然后调用 updateCondition 方法。该方法是 WriteSinkFunction 定义的抽象方法。用于实现判断将tupleList写入文件以及清空tupleList的条件。接着将集合中的tuple写入到指定的文件中。最后又调用了 resetParameters 方法。该方法同样是一个抽象方法,它的主要用途是当写入的场景是批量写入时,可能会有一些状态参数,该方法就是用于对状态进行reset。
WriteSinkFunctionByMillis
该类是 WriteSinkFunction 的实现类。它支持以指定的毫秒数间隔将tuple批量写入文件。间隔由构造器参数 millis 指定。在内部, WriteSinkFunction 以 lastTime 维护上一次写入的时间状态。它主要涉及上面提到的两个抽象方法的实现:
protected boolean updateCondition() {
return System.currentTimeMillis() - lastTime >= millis;
}
updateCondition 的实现很简单,拿当前主机的当前时间戳跟上一次的执行时间戳状态作对比:如果大于指定的间隔,则条件为真,触发写入。
protected void resetParameters() {
tupleList.clear();
lastTime = System.currentTimeMillis();
}
resetParameters 实现是先清空tupleList,然后将lastTime老的时间戳状态覆盖为最新时间戳。
WriteFormat
一个写入格式的抽象类,提供了两种实现:
- WriteFormatAsText : 以原样文本的形式写入指定路径的文件
- WriteFormatAsCsv : 以csv格式写入指定文件
RichSinkFunction
RichSinkFunction 通过继承 AbstractRichFunction 为实现一个 rich SinkFunction提供基础( AbstractRichFunction 提供了一个open/close方法对,以及获取运行时上下文对象手段)。 RichSinkFunction 也是抽象类,它有三个具体实现。
SocketClientSink
支持以socket的方式将数据发送到特定目标主机所在的服务器作为flink stream的sink。数据被序列化为byte array然后写入到socket。该sink支持 失败重试 模式的消息发送。该sink 可启用 autoFlush ,如果启用,那么会导致吞吐量显著下降,但延迟也会降低。该方法的构造器,提供的参数:
- hostName : 待连接的server的host name
- port : server的端口
- schema :
SerializationSchema的实例,用于序列化对象。 - maxNumRetries : 最大重试次数(-1为无限重试)
- autoflush : 是否自动flush
重试的策略在 invoke 方法中,当发送失败时进入到异常捕捉块中进行。
OutputFormatSinkFunction
一个将记录写入 OutputFormat 的SinkFunction的实现。
OutputFormat :定义被消费记录的输出接口。指定了最终的记录如何被存储,比如文件就是一种存储实现。
PrintSinkFunction
该实现用于将每条记录输出到标准输出流(stdOut)或标准错误流(stdErr)。在输出时,如果当前task的并行subtask实例个数大于1,也就是说当前task是并行执行的(同时存在多个实例),那么在输出每条记录之前会输出一个 prefix 前缀。prefix为在全局上下文中当前subtask的位置。
常见连接器中的Sink
Flink自身提供了一些针对第三方主流开源系统的连接器支持,它们有:
- elasticsearch
- flume
- kafka(0.8/0.9版本)
- nifi
- rabbitmq
这些第三方系统(除了twitter)的sink,无一例外都是继承自 RichSinkFunction 。
小结
这篇文章我们主要谈及了Flink的stream sink相关的设计、实现。当然这个主题还没有完全谈完,还会有后续篇幅继续解读。
微信扫码关注公众号:Apache_Flink

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

