认识CPU
CPU是一个系统的核心所在,它推动了所有软件的运行。

CPU的核
一般我们会说,这是一个4核CPU,或者是一个4核8线程的CPU,这是什么意思呢?
物理CPU
指机器上的插槽插的CPU个数。物理CPU的数量,可以通过查询系统中不重复的 physical id 数量来判断:
$ cat /proc/cpuinfo |grep "physical id"|sort |uniq|wc -l
1
明显看到我的机器上只有一个物理CPU,主板上插了一个CPU。
每个CPU都会集成一个或者多个处理器芯片( 称为Core,核心 )。
CPU最初发展的时候是一个CPU一个处理核心,CPU的性能主要靠提高核心工作频率来提高,但是仅仅提高单核芯片的速度会产生过多热量且无法带来相应的性能改善。
为了提升处理器的能效,于是发展出来了双核心CPU( Dual-core processor )和多核心的CPU( Multi-core processor ),在物理上是把2个或者更多的独立处理器芯片封装在一个单一的集成电路中。
在操作系统中,可以看到具有相同 physical id 的CPU是同一个物理CPU封装的线程或核心(下面会讲到线程)。
总物理核数 = 物理CPU个数 X 每颗物理CPU的核数
查看CPU核数:
$ cat /proc/cpuinfo| grep "cpu cores"| uniq
cpu cores : 4
以上是我的电脑的CPU核心数,有4核物理核的CPU。
逻辑CPU
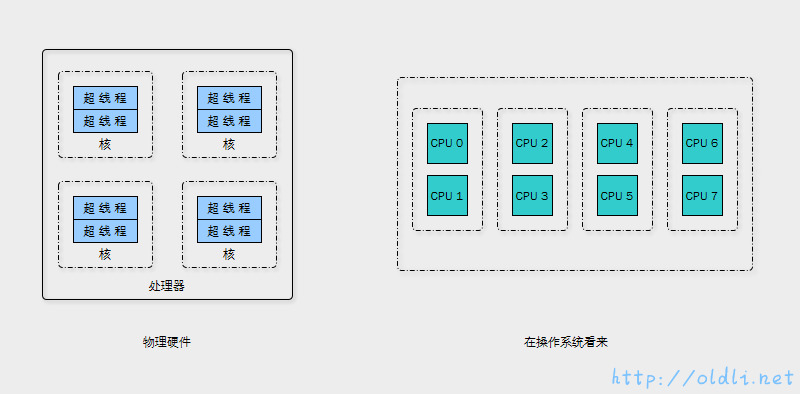
开始的时候CPU是一个核心一个线程,为了进一步提升CPU的处理能力,Intel又引入了HT(Hyper-Threading,超线程)的技术,一个Core打开HT之后,在操作系统看来就是两个核,当然这个核是逻辑上的概念,所以也被称为逻辑处理器(Logical Processor)。
**“超线程”(Hyperthreading Technology)**技术就是通过采用特殊的硬件指令,可以把两个逻辑内核模拟成两个物理超线程芯片,在单处理器中实现线程级的并行计算,同时在相应的软硬件的支持下大幅度的提高运行效能,从而实现在单处理器上模拟双处理器的效能。其实,从实质上说,超线程是一种可以将CPU内部暂时闲置处理资源充分“调动”起来的技术。
所以,逻辑CPU的数量有时会大于物理CPU的数量,是因为开了超线程技术,计算公式如下:
总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
在操作系统中查看逻辑CPU的个数:
$ cat /proc/cpuinfo| grep "processor"| wc -l
8
查看 /proc/cpuinfo 可以看到,分别各有2个 processor 的 core id 是一样的,也即这2个逻辑CPU是同一个CPU核心的超线程。
查询CPU是否启用超线程:
$ cat /proc/cpuinfo | grep -e "cpu cores" -e "siblings" | sort | uniq
cpu cores : 4
siblings : 8
-
cpu cores指的是一个物理CPU有几个核 -
siblings指的是一个物理CPU有几个逻辑CPU
如果cpu cores数量和siblings数量一致,则没有启用超线程,如果siblings是cpu cores的两倍,则说明支持超线程,并且超线程已打开。
要实现HT的功能,除了CPU要支持外,还需要主板芯片组,主板BIOS,以及操作系统的支持。一般说来,最大发挥HT技术的运行效能还需要真正支持超线程技术的软件。
虽然采用超线程技术能同时执行两个线程,但它并不象两个真正的CPU那样,每个CPU都具有独立的资源。当两个线程都同时需要某一个资源时,其中一个要暂时停止,并让出资源,直到这些资源闲置后才能继续。因此超线程的性能并不等于两颗CPU的性能。
根据Intel提供的数据,这样一个技术会使得设备面积增大5%,但是性能提高15%~30%。
来一张我的机器的CPU架构图:
CPU指令
CPU指令集
为什么CPU能控制一个庞大而复杂的电脑系统?这就关乎到指令集。
CPU依靠指令来计算和控制系统,对电脑下达的每一个命令都需要CPU根据预先设定好的某一条指令来完成。这些预先设定好的指令是预存在CPU中的。CPU依靠外来指令“激活”自己内存的指令,来计算和操控电脑。
每款CPU在设计时就规定了一系列与其硬件电路相配合的指令系统,这就是所谓的 指令集 。
指令周期
说到指令,就不能不提指令周期。
指令周期是执行一条指令所需要的时间,是从取指令、分析指令到执行完所需的全部时间。它一般由若干个 机器周期 组成。
机器周期(也称为CPU周期)指计算机完成一个基本操作所需要的时间。例如,取指令、存储器读、存储器写等,这每一项工作称为一个基本操作。
机器周期还不是计算机最小最基本的时间单位,计算机中最基本的、最小的时间单位是 时钟周期 ,在一个时钟周期内,CPU仅完成一个最基本的动作。
计算机之所以能自动地工作,是因为CPU能从存放程序的内存里取出一条指令并执行这条指令;紧接着又是取指令,执行指令,如此周而复始,构成了一个封闭的循环。除非遇到停机指令,否则这个循环将一直继续下去。
CPU工作频率
时钟频率
时钟频率(又译: 时钟频率速度 ,clock rate),是指同步电路中时钟的基础频率,它以“若干次周期每秒”来度量,量度单位采用SI单位赫兹(Hz)。它是评定CPU性能的重要指标。
在电子技术中,脉冲信号是一个按一定电压幅度,一定时间间隔连续发出的脉冲信号。脉冲信号之间的时间间隔称为 周期 ;而将在单位时间(如1秒)内所产生的脉冲个数称为 频率 。
时钟频率的单位有:Hz(赫兹)、kHz(千赫兹)、MHz(兆赫兹)、GHz【吉赫兹(1吉=1000000000)】。其中1GHz=1000MHz,1MHz=1000kHz,1kHz=1000Hz。
例如,一个5GHz的CPU每秒运行50亿个时钟周期。
主频
主频用来表示CPU的运算、处理数据的速度,单位是兆赫(MHz)或千兆赫(GHz)。通常,主频越高,CPU处理数据的速度就越快。
CPU的主频 = 外频 X 倍频系数
查看型号以及主频:
$ cat /proc/cpuinfo | grep "model name" | cut -f2 -d: | uniq
Intel(R) Core(TM) i7-3632QM CPU @ 2.20GHz
我的电脑的CPU最高频率可达2.20GHZ。
查看当前执行频率:
$ cat /proc/cpuinfo |grep MHz|uniq
cpu MHz : 1218.250
cpu MHz : 1249.531
cpu MHz : 1208.453
cpu MHz : 1493.250
cpu MHz : 1341.140
cpu MHz : 1427.164
cpu MHz : 1318.023
cpu MHz : 1200.031
由于开启了CPU的节能特性,每次执行的频率都会不一样。CPU会自动调整当前的执行频率。
外频
外频是CPU的基准频率,单位是MHz。CPU的外频决定着整块主板的运行速度。
倍频系数
倍频系数是指CPU主频与外频之间的相对比例关系。在相同的外频下,倍频越高CPU的频率也越高。
CPU缓存
CPU缓存(Cache Memory)是位于CPU与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多。
高速缓存的出现主要是为了解决CPU运算速度与内存读写速度不匹配的矛盾,因为CPU运算速度要比内存读写速度快很多,这样会使CPU花费很长时间等待数据到来或把数据写入内存。
在缓存中的数据是内存中的一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可避开内存直接从缓存中调用,从而加快读取速度。
CPU缓存可以分为一级缓存,二级缓存,部分高端CPU还具有三级缓存,每一级缓存中所储存的全部数据都是下一级缓存的一部分,这三种缓存的技术难度和制造成本是相对递减的,所以其容量也是相对递增的。
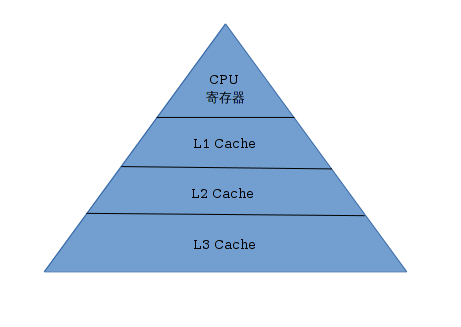
在操作系统查看CPU缓存:
$ lscpu
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 6144K
$ cat /sys/devices/system/cpu/cpu0/cache/index0/size
32K
$ cat /sys/devices/system/cpu/cpu0/cache/index1/size
32K
$ cat /sys/devices/system/cpu/cpu0/cache/index2/size
256K
$ cat /sys/devices/system/cpu/cpu0/cache/index3/size
6144K
附/proc/cpuinfo
不同指令集(ISA)的CPU产生的 /proc/cpuinfo 文件不一样,基于X86指令集CPU的/proc/cpuinfo文件包含如下内容:
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 58
model name : Intel(R) Core(TM) i7-3632QM CPU @ 2.20GHz
stepping : 9
microcode : 0x15
cpu MHz : 1288.289
cache size : 6144 KB
physical id : 0
siblings : 8
core id : 0
cpu cores : 4
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm ida arat epb pln pts dtherm tpr_shadow vnmi flexpriority ept vpid fsgsbase smep erms xsaveopt
bugs :
bogomips : 4389.72
clflush size : 64
cache_alignment : 64
address sizes : 36 bits physical, 48 bits virtual
power management:
- processor : 系统中逻辑处理核的编号。对于单核处理器,则可以认为是其CPU编号,对于多核处理器则可以是物理核、或者使用超线程技术虚拟的逻辑核
- vendor_id : CPU制造商
- cpu family : CPU产品系列代号
- model : CPU属于其系列中的哪一代的代号
- model name : CPU属于的名字及其编号、标称主频
- stepping : CPU属于制作更新版本
- microcode : CPU微码
- cpu MHz : CPU的实际使用主频
- cache size : CPU二级缓存大小
- physical id : 单个CPU的标号
- siblings : 每颗物理cpu的逻辑核数,与cpu cores对比可以确认cpu是否启用超线程
- core id : 当前物理核在其所处CPU中的编号,这个编号不一定连续
- cpu cores : 每颗物理cpu的核数,即几核CPU,每个物理cpu具有几个运算内核core
- apicid : 用来区分不同逻辑核的编号,系统中每个逻辑核的此编号必然不同,此编号不一定连续
- initial apicid: 0
- fpu : 是否具有浮点运算单元(Floating Point Unit)
- fpu_exception : 是否支持浮点计算异常
- cpuid level : 执行cpuid指令前,eax寄存器中的值,根据不同的值cpuid指令会返回不同的内容
- wp : 表明当前CPU是否在内核态支持对用户空间的写保护(Write Protection)
- flags : 当前CPU支持的功能
- bogomips : 在系统内核启动时粗略测算的CPU速度(Million Instructions Per Second)
- clflush size : 每次刷新缓存的大小单位
- cache_alignment : 缓存地址对齐单位
- address sizes : 可访问地址空间位数
- power management: 对能源管理的支持
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

