Pinterest 的 Smart Feed 架构与算法
Pinterest 的本意是协同收集创意内容的工具,看到感兴趣的内容就把它钉(Pin)在板上(Board)。虽然 Pinterest 自己不认为自己是社交网络,但是它允许人关注人,关注兴趣,本质上就是社交网络了。
Pinterest 把 feed 改成兴趣feed是2014年的事情,也引起了不少争议,甚至你在 Google 搜索 Pinterest Smart Feed 能看到以下场景:

这都按下不表,世间互联网产品改版的遭遇大抵如此,只不过有的坚持下来,有的赶紧下线。
相对于 Facebook 的讳莫如深, Pinterest 在其官方技术博客上相对详细披露了其架构和算法的一些技术细节[1],本篇综合 Pinterest 的官方技术博客进行解读,窥探一个现有的兴趣feed是怎么实现的。
Pinterest 产品特点
Pinterest产品有几个关键元素:
-
Pin:采集或者采集的内容(既有名词含义,又有动词含义)。
-
Piner:采集内容的人。
-
Board:看板,内容集合。
-
Interest:兴趣,标签或分类。
用户在 Pinterest 上可以关注一个人,关注一个分类,看到感兴趣的内容可以 Pin 一下到已有的 Board 来。
所以,Pinterest 的首页 Feed 就包括三种:
-
来自你关注的人收集的 Pin。
-
跟你已采集的内容相似或相关的内容。
-
来自你关注的分类的内容。
Pinterest 架构概览
Pinterest 的首页 feed 有这么几个要求:
-
Pin 的不同发表源要按照一定比例混合后展示。
-
有选择地(按照权重)不展示或者推迟展示某些 Pin。
-
Pin 一定要按照“好坏”来排序,而不是按照“新旧”排序。
第三点很显然,“好坏”其实就是对用户的价值来说,否则就不是 Smart Feed 了,你也一定会认为我该吃药了。
整个首页 feed 后端主要模块逻辑如下:
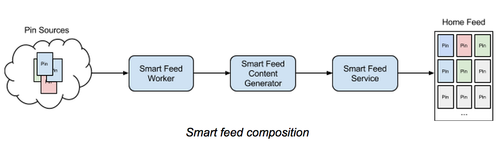
非常清晰,整个结构逻辑上由三部分构成:
-
Worker
-
Content Generator
-
Service
Worker
Worker可以认为是后台作业模块,最苦最累的活都在这里,其任务有两个:
-
接收数据源产生的新 Pin,决定这个 Pin 该推送给哪些用户,并针对每一个它该推送的用户,给出这个 Pin 对这个用户的吸引程度,俗称“打分”。
-
存储这些经过打分的 Pin,备用。
什么?你问用什么算法给 Pins 评分的?你们这些搞算法的就是猴急,上来就问G点在哪,后面会专门讲到,不要急,也不要快进,我们继续看看 Worker 是怎么回事。
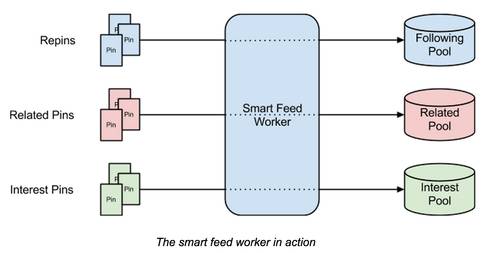
前面说到,Pins 一共来自三个地方,每一个 Pin 都会结合用户来打分,这决定了它会不会出现在这个用户的 Feed 里。
打了分的 Pin 就会根据其不同来源分开存储(Pool)。存储结构是一个优先队列,按照打分排序,新的 Pin 进来和原来(但用户还未看)的 Pins 一起排序。
这个存储的 Pool 可以直接用 KV 数据库顶上,HBase,Redis 都可以,每次送入数据库的数据是一个三元组:(user, pin, score)。
具体到 Pinterest,他们选用的是 HBase[3][5]。一共有两个 HBase 集群,一个存还没看过的 Pin,一个存已经看过的 Pin。
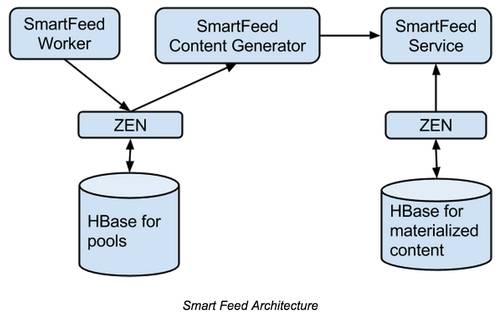
解释一下这个图。
-
Zen(中文名字叫禅,有意境)是个专门封装向 HBase 存储图模型(社交网络的基本模型[4])数据的,抽象了很多 HBase的 基本操作。
当数据源产生了新的 Pin 之后,需要由一个叫 PinLater 的模块经过 Zen 推送给粉丝。这里推送是异步的,有几秒到几分钟的延迟[2]。每一个新的 Pin 产生,都是异步地进行,并不会影响后面的 Content Generator 和 Service。
PinLater 是一个自己研发的分布式任务队列,开源替代品有 Celery,非常好用,下一篇会介绍。
-
materialized content 就是“旧”内容,它是和新内容分开存的。
另外,Pinterest 还在不同机房有一个热备 HBase 集群,对主集群的任何操作都会同步到这个热备集群上,一旦主集群挂了,热备集群就顶上去。
Content Genreator
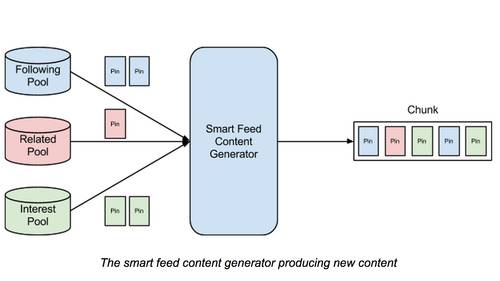
如图,Conent genreator 就是在用户登录后或者手动刷新时会触及的关键服务了。
当用户登陆上来后,会向 Content generator 请求“新的” Pins。这个模块最主要的责任就在这里:给出新的 Pins。这里所说的“新” Pins 就是用户没看过的。
具体它要做的就是:
-
决定返回多少个 Pins,数量不是固定的,会根据用户访问频繁程度,以及上次看到的新内容多少决定。
-
分配来源的比例构成,这块没有透露怎么分配比例,我们可以猜一下,也许是固定比例,也许是有一些启发式算法。
-
将 Pins 排成一定的顺序,按照分数排序就好了。
-
待推送内容要从 Pool 中删除,以保证每次请求的都是没看过的。
每一次产生的待推送内容合在一起叫做一个“块”(chunk)。
Feed Service
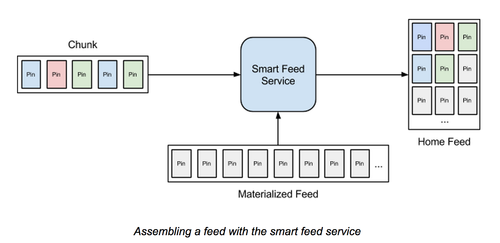
Feed service 就是提供前端的服务了。为了提供高可用服务,service 的任务有二个:
-
接收从 generator 返回的“新”内容。
-
新内容合并上一次的“旧”内容。
Service 不对内容顺序做任何修改,只是把新旧内容合并在一起,同时还要保证服务的高可用。
-
如果 generator 当掉了,service 就会优雅降级:返回上一次推送的内容。这时候从用户端看到的效果就是还没有产生新内容。
-
如果上一次发生了优雅降级,那么用户本次访问时获得的新内容会比正常要多。
总体架构逻辑上很清晰,每个模块的分工很明确。据 Pinterest 说,整个应用的流量1/3都来自首页,可想而知,首页架构必须要高可用。而且,Pinterest 内部对服务的要求是99.99%情况下不出错。
总结一下,这个架构关键有几点保证了服务的高可用:
-
内容产生后给粉丝采用异步的推模式(PinLater)。
-
HBase 集群采用冗余备份,并且新旧内容分开存储。
-
Service 和 Generator 分离,当事故发生时优雅降级。
Pinterest排序算法
好了,我知道大家都很关心 SmartFeed 的算法。
答案揭晓:名字叫做 Pinnability [6]。
我们可以翻译成“可Pin度”,可Pin度是一组机器学习模型,用于衡量一个用户对一条 Pin 产生互动的可能性。

在 Pinnability 诞生之前,Pinterest 的 Feed 一点也不 Smart,就是最简单的时间排序。但和 Facebook 不同的是,Pinterest 改成兴趣feed之后直接就上了机器学习,而没有走 EdgeRank 这样的中间状态。

时间序很简单直接。
Pinnability 模型用到的机器学习算法都是比较常用的模型:
-
Logistic Regression(逻辑回归)。
-
Support Vector Machines(支持向量机SVM)。
-
Gradient Boosted Decision Trees(GBDT,梯度提升树)。
-
Convolutional Neural Networks (CNN,深度学习之卷积神经网络)。
整个 Pinnability 的模型流程是:
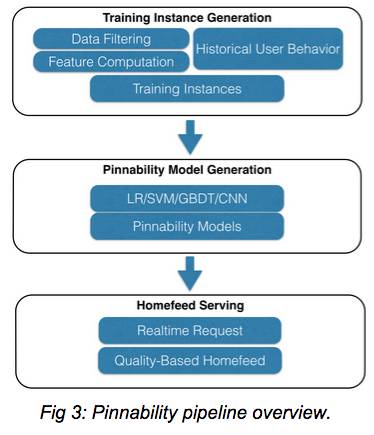
pipeline 分为三个阶段:
-
准备训练数据
-
训练模型
-
上线使用
准备训练数据的时候主要就是对样本采样和特征生成,因为曝光样本远多于正样本,严重不平衡的类别分布,需要对负样本采样(展示给用户但没产生互动的)。
模型用到特征目前有几千个,相比 Facebook 的 NewsFeed 少了一些。 这里有文本特征,还有图像特征(CNN也用于这里)。
特征有三类:
-
Pin 本身的特征,包含内容特征,一些统计特征如历史热度之类, 新鲜程度,是垃圾的可能性。
-
产生这个 Pin 的用户特征,比如活跃度,性别,看板状态等。
-
互动特征,待推送的这个用户之前和类似的 Pin 互动程度。
每条训练样本包含三部分:目标值(正负样本)、特征、元数据(一些ID类,时间戳等,用于在MapReduce阶段分割样本,用于交叉测试)。
模型训练时尝试了上面列的所有算法,用 AUC 做为模型的主要评价指标,发现同样的特征集合,基本上都是 LR 和 GBDT 表现最好。
确定算法之后,特征选择也是必须的,做了很多特征筛选工作,保留了最具区分性的特征。
每次模型更新训练之后,先用历史数据做离线测试,然后上线AB测试,最后再全局铺开。
根据 Pinterest 的博客显示,他们目前还是离线批量学习,在线使用,还没有做到实时更新参数,毕竟据说只有不到20人的公司。
模型上线之后就是以一个服务形式存在,当 PinLater 把新的 Pin 和要推送的用户发送过来后,就逐一去预测每个用户可能会对该 Pin 产生互动的概率,将概率做为分数返回,通过 Zen 存储进 HBase 集群中。
Smart Feed 给我们的启示
太shi公曰:Smart Feed 的架构平易近人,算法司空见惯,都是类似“多喝热水、重启一下”的常规方法,奈何其产品竟然如何成功。国内也有仿 Pinterest 的,先有花瓣网,后有微博倾全公司之力做了微刊,均没有 Pinterest 这么成功,介是为嘛呢?
现在关灯,我们一起闭眼思考思考。
[1] https://engineering.pinterest.com/blog/building-smarter-home-feed
[2] https://engineering.pinterest.com/blog/pinlater-asynchronous-job-execution-system
[3] https://engineering.pinterest.com/blog/building-scalable-and-available-home-feed
[4] https://engineering.pinterest.com/blog/building-follower-model-scratch
[5] http://www.slideshare.net/cloudera/case-studies-session-3a
[6] https://engineering.pinterest.com/blog/pinnability-machine-learning-home-feed
本文为系列文章之一,包括:
-
为什么应该关注兴趣Feed?
-
关于 Facebook NewsFeed,看这一篇就够了!
-
Pinterest 的 Smart Feed 架构与算法(本篇)
-
通用兴趣Feed的技术要点
作者简介:陈开江@刑无刀
-
2013年之前在新浪微博搜索部和商业产品部任资深算法工程师,先后负责过微博反垃圾、基础数据挖掘、智能客服平台、个性化推荐等产品的后端算法。
-
2012-2013领导翻译了《机器学习:实用案例解析》一书。
-
2013年末加入传统媒体公司车语传媒,任算法主管,负责从零打造公司转型产品考拉FM的个性化推荐系统,如今个性化推荐已成为考拉FM与其他FM之间最大差异化特性。
-
2015年初,离职创业,公司拿到IDG和晨兴资本的天使投资,产品几经调整,如今专注在用视频分享购物经验,App名称:边逛边聊。
微信公众号【 ResysChina 】,中国最专业的个性化推荐技术社区。
点击阅读原文,可以查看上一篇《 关于 Facebook NewsFeed,看这一篇就够了! 》
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

