MySQL之change master
问题来源:同事;
问题背景:在切换了master的IP(master的实例没变,只是IP变了)之后,主库和从库之间产生了非常高的流量;主从开启了GTID和semi-sync;
现象分析:
从监控图表上看,主库产生的异常流量全部为send,receive正常;
从库的异常流量全部为receive,send正常;
主库的send流量曲线和从库的receive曲线是基本重合的;
通过对流量监控的观察,基本判断为主库的send流量全部发往了从库;
据描述,当时候在从库上的操作只有一个change master, 修改了master_host,并指定了auto_position=1;
提出疑问:是否是change master导致了从库重新接收了主库上已经执行过的binlog?
在测试环境验证一下:
MySQL5.7.12,GTID;
使用auto_position配置的主从,执行几个操作,看一下relay-log的内容,
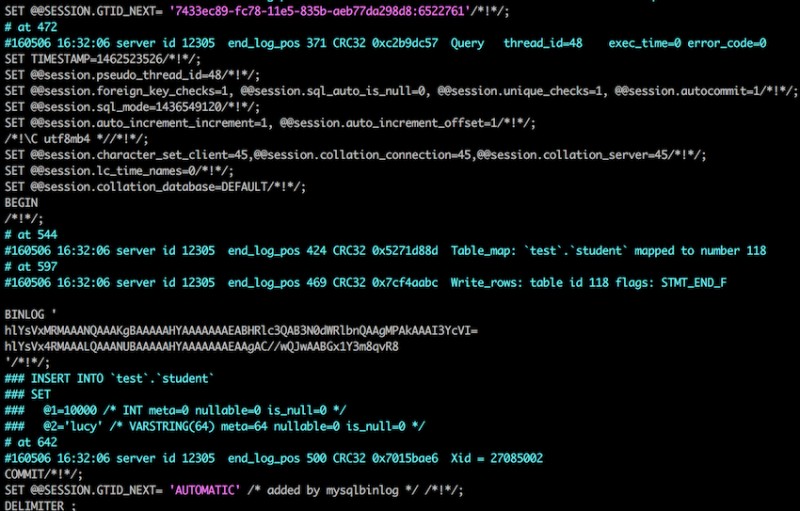
这时候再在从库上面change master,看一下relay-log的内容;
![]()
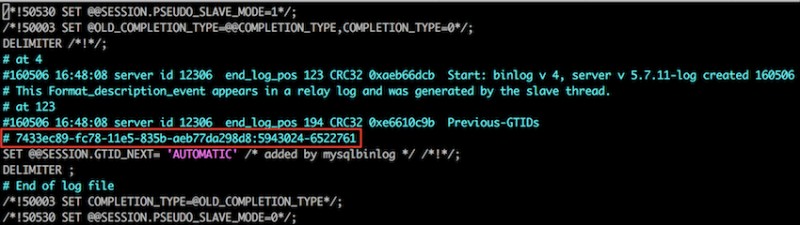
可以发现,在change master以后,MySQL已经把原有的relay-log清空了,并且在新的relay-log里面标注了有关GTID的信息;
重新开启slave,使用auto_position=1,再看一下relay-log和slave的信息;
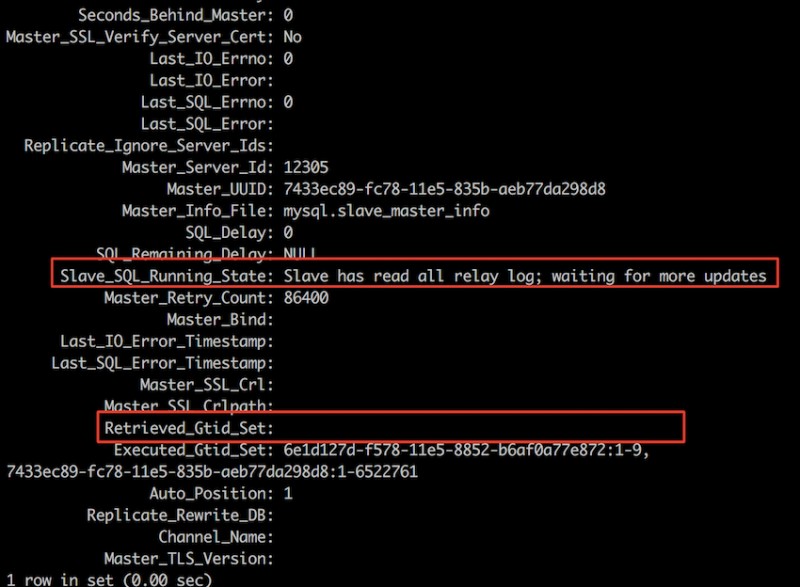
可以看到slave已经启动,但是并没有从主库拉取日志,那么在主库上执行一个sql看看,
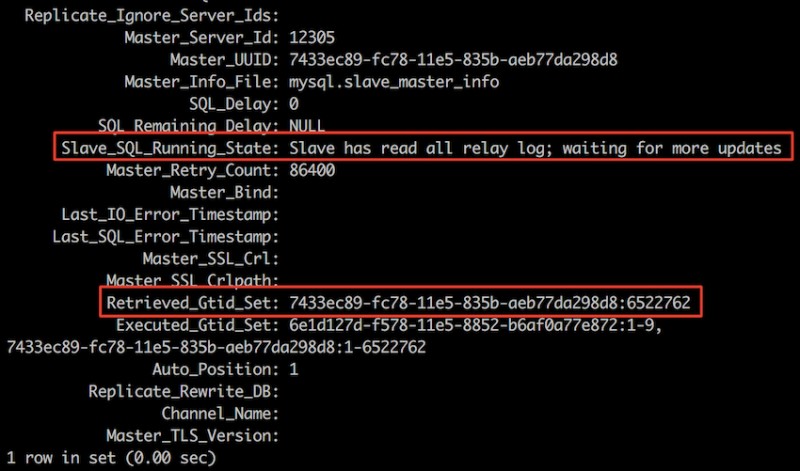
可以看到重新同步的时候,slave接收到的binlog,是从之前已执行GTID之后的日志,并没有接收已经执行过的binlog;
所以change master,并使用auto_position=1,并不会导致从库去重新拉去已经执行过的主库的binlog;
问题的延伸:如果在change master的时候,从库本身已经有延迟,那么在change master之后,之前已经拉取到的binlog(已经拉取,但是还没有在从库复现的那一部分)会不会重新拉取,从而产生短时间内的流量高峰?
回答:会;
验证:拿正在跑sysbench的环境看看,从库已经有延迟了,这时候停掉slave, 看一下从库的relay-log和slave的信息;
接收到的事务ID远多于执行完的,说明有比较大的延迟;
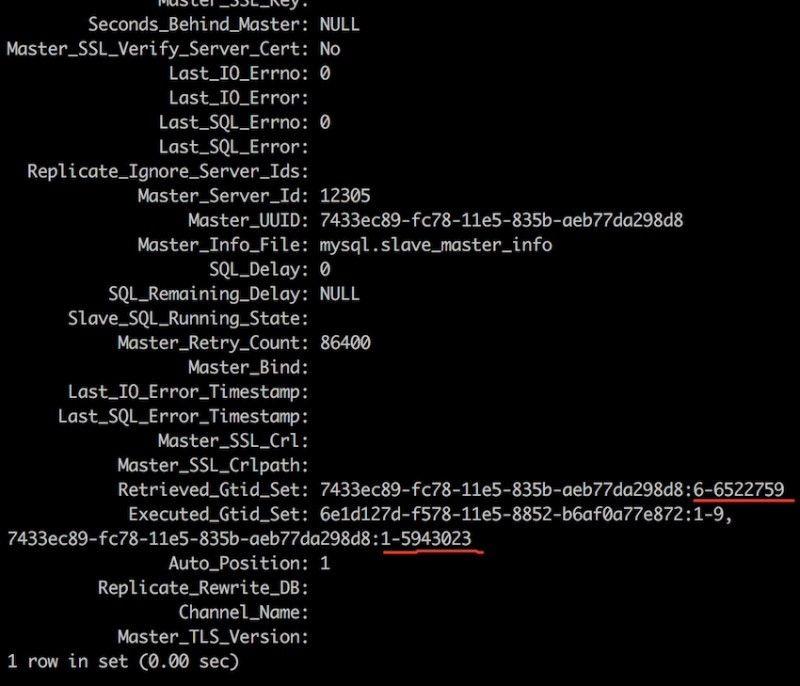
找到relay-log中对应的这个事务
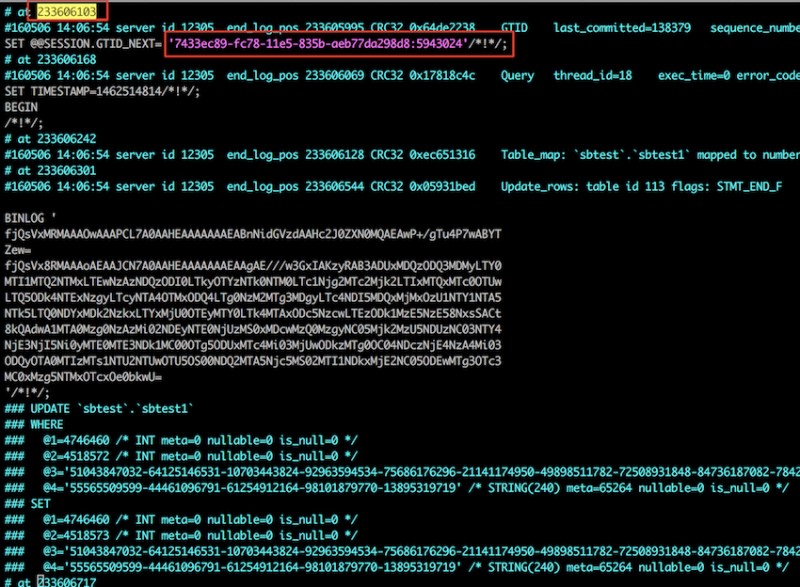
以及事务所处的relay-log的位置
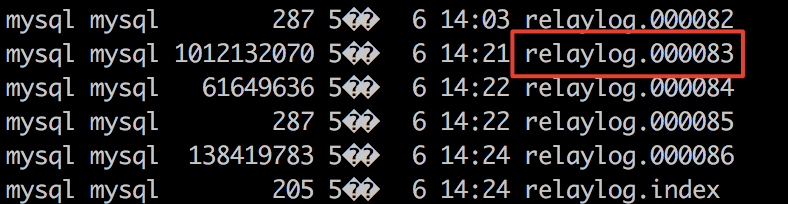
可以看到relay-log中确实已经堆积了一部分log了,
然后change master, 看看slave的信息,再看看监控和relay-log的信息;
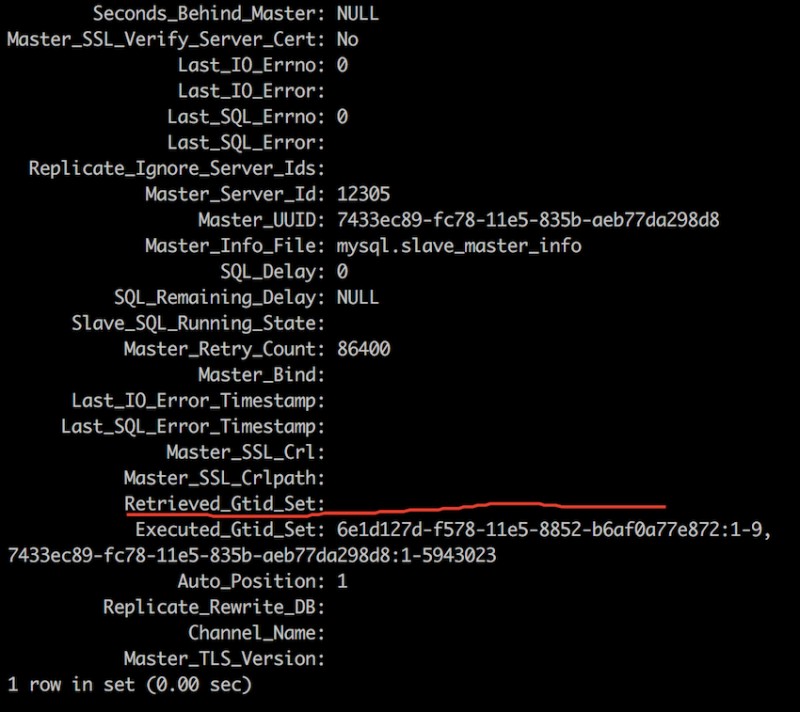
和之前一样,相关的relay-log全部被清空了,那么单独打开IO thread, 然后看看监控中流量的数据,
主库全部是发送,
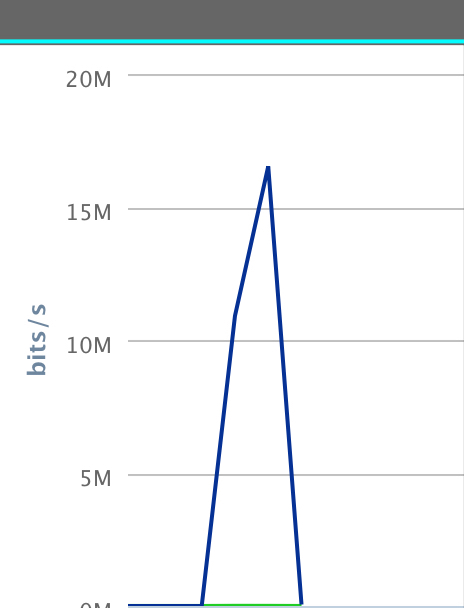
从库全部是接收,
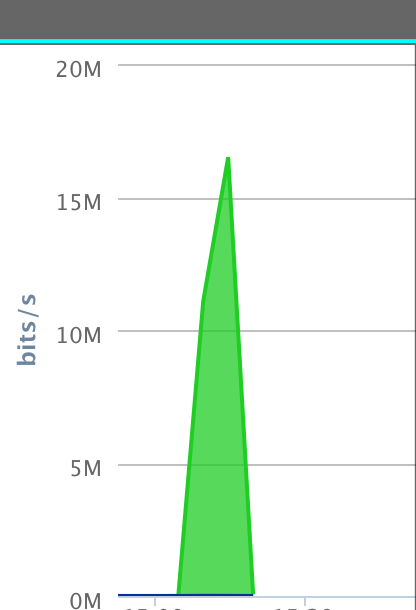
如预料一般,之前没来得及同步的那一部分日志,又被拉取下来了;
结论:如果在从库有延迟的情况下,执行change master的操作,会清除relay-log,然后重新拉取延迟的那一部分的binlog,会在主从之间产生一个流量高峰,有多高,持续多久,取决于延迟的这部分binlog的大小;
那么,最开始提出的问题,是不是因为这个原因造成的?
回答:可能在切换的过程中确实有堆积一部分binlog,但并不是主要原因,因为当时异常流量的现象持续时间非常长,产生的总流量远远超过主库binlog总的大小;还需要继续去排查......
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

