Menagerie:使用 Docker 容器执行批处理作业调度
前言
批处理作业调度是许多设计模式和实现都在处理的一个常见的、很有用的问题,也是许多计算系统的核心。批处理作业与运行微型服务不同,因为它运行时间较短,根据输入计算输出,然后被丢弃。 在常规计算环境中执行此调度时,我们需要确保所有潜在的作业都在目标执行节点上拥有它们所需的资源。该资源包括物理资源、前提软件、配置文件和附加文件,可能还包括其他资源。 当然,随着考虑的作业变得更加复杂,目标节点上的资源和前提条件冲突将会变得更难管理,比如库版本、语言解释器和虚拟机冲突,有时甚至来自主机的不同需求也会发生冲突。即使前提条件没有完全冲突,随着添加的目标作业的增加,目标环境也可能变得极为凌乱。此外,如果需要为一个作业回滚软件组件,那么我们可能遇到可怕的情况。 我们在开始设计一个平台时遇到了这个问题,该平台可持有多个文件分析器(引擎),它们可能使用恶意软件样本、PCAP 文件、Android APK 等。所有这些引擎都拥有不同甚至冲突的前提条件,而且我们一开始就很明显地发现无法简单地将所有引擎安装在目标机器上。除了这个核心需求之外,我们还有以下需求:
- 引擎列表是动态的,我们需要轻松地添加新引擎或升级现有引擎
- 作业提交和结果收集应通过 HTTP API 完成
- 需要支持作业跟踪和历史记录
- 需要限制资源,甚至需要对某些引擎进行资源拦截,无论是为了保持良好的公民环境还是出于安全原因
所有这些导致我们设计和构建了Menagerie 平台,下面我们将会介绍它。
作业引擎
不同的安装需求让我们立即就想到了 Docker 容器。对于每种作业类型,我们创建了一个“作业引擎”,基本上讲,它就是一个围绕该工具构建的容器镜像。我们在它之上提供一个入口点脚本,该脚本使用了一个输入文件,并提供了一个输出文件(二者都可以是多个压缩文件,只要工具支持且需要它)。 我们使用 Docker 容器获得的收益可以立即显现出来:
- 消除冲突的前提条件和主机凌乱
- 利用 Docker 镜像版本系统
- 使用 Docker 注册表存储引擎镜像
- 更有效地限制作业
我们在开源项目中提供的默认的 Vagrant 配置围绕 apktool(一个 Android 逆向工程工具)构建了这样一个镜像。您可以查看 Docker 文件,看看这个引擎包装实际上有多小。
作业工作流
对于作业排队,我们使用了 RabbitMQ,它提供了一个健全的、容错的、现成的解决方案来构建“生成者-使用者”工作流。设置 RabbitMQ 很容易,只需拉入官方 Docker 镜像;我们编写了一些简单的 Go 代码,向(和从)RabbitMQ 推送(和拉入)条目。 在生成者一端,我们编写了一个公开该 API 的轻量型 Web 服务器。当输入传入时,它存储在一个内部文件存储中,而且会将一个 ID 写入一个特定于引擎的队列中。在使用者一端,每个作业引擎都拥有可配置的工作者线程数量。这些工作者线程从上述队列拉取条目,并使用该输入启动一个引擎容器。当启动引擎时,会写回输出,更新作业状态,然后用户可以通过 API 拉取结果。 完整的作业历史记录和跟踪由一个作为单独容器启动的 MySQL 数据库提供支持。
将各部分结合起来
整个系统是通过相互交互并提供上述服务的容器构建起来的。如果在设置 Vagrant 后查看该工具箱,就可以看到以下运行的容器:
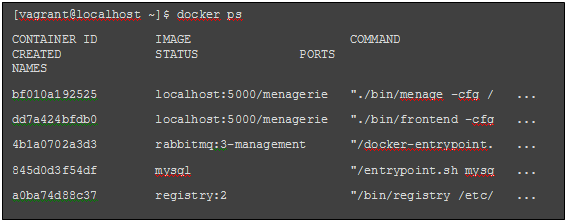
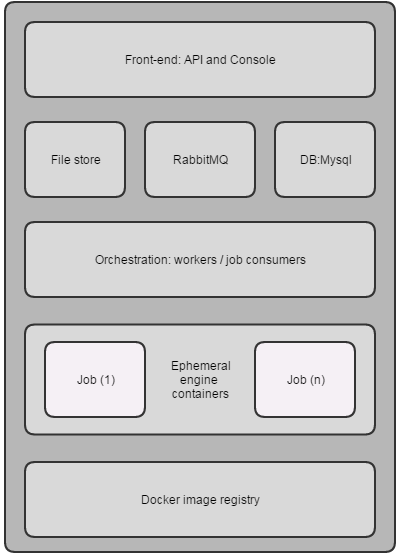
3 个底部的容器是支持性的第三方基础架构:RabbitMQ、Docker 注册表和 MySQL。顶部的两个容器来自同一个镜像(Menagerie 代码),但在不同的容量下执行,一个作为前端,另一个作为后端工作者线程编排器。 前端由一个非特权用户启动,因为它向外部世界公开。后端容器需要引擎容器内创建新作业,所以它必须有足够的特权来访问 Docker 后台进程(这通过映射容器内的 /var/run/docker.sock 来完成)。 下图描述了获得的整体架构:
结束语
Menagerie 已在一个预生产环境中运行,每天处理数千个文件。我们呼吁您了解一下该项目,考虑使用、评审此项目并为其做出贡献。
在未来的文章中,我将介绍在多个节点上分布 menagerie 的考虑因素,展示如何增强它的安全性,尤其是在作业执行方面。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

