cuDNN 5对RNN模型的性能优化
原文: Optimizing Recurrent Neural Networks in cuDNN 5
作者:Jeremy Appleyard
翻译:赵屹华 审校:刘翔宇
责编:周建丁(zhoujd@csdn.net)
在GTC2016大会上,NVIDIA发布了最新版本的深度学习开发包,其中包括了cuDNN 5。第五代cuDNN引入了新的特性,提升了性能,并且支持最新一代的NVIDIA Tesla P100 GPU。cuDNN的新特性包括:
- 使用Winograd卷积算法,计算前向、后向卷积速度更快;
- 支持3D FFT Tiling;
- 支持空间转移网络;
- 更优的性能,在Pascal GPU上使用半精度函数节省了内存空间;
-
支持用于序列学习的LSTM递归神经网络,速度提升6倍。
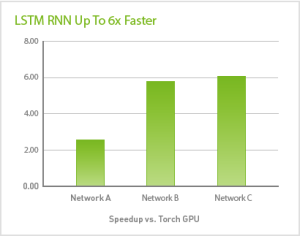
图1:cuDNN 5 + Torch speedup vs. Torch-rnn ,M40, Intel:emoji: Xeon:emoji: Processor E5-2698。网络模型A:RNN维度2560,输出维度2560,1层,序列长度200,批大小为64。网络模型B:RNN维度256,输入维度64,3层,批大小为64。网络模型C:RNN维度256,输入维度256,1层,批大小为32,序列长度1000。
cuDNN 5的新特性之一就是它可以支持递归神经网络(Recurrent Neural Networks)。RNN是各个领域用于序列学习的强大工具,从语音识别到图像配字。若想简单了解RNNs,LSTM和序列学习的内容,我推荐阅读Tim Dettmers最近的文章Deep Learning in a Nutshell: Sequence Learning ,更深入的理解可以阅读Soumith Chintala的文章Understanding Natural Language with Deep Neural Networks Using Torch。
我对cuDNN 5支持RNN的能力感到非常激动;我们投入了大量的精力来优化它们在NVIDIA GPU上的性能,我在本文中将会介绍这些优化的一部分细节。
cuDNN 5支持四种RNN模式:ReLU激活函数模式,tanh激活函数模式,门控递归单元(Gated Recurrent Units)和长短期记忆(LSTM)。在这类,我将以LSTM网络的性能为例,但大多数的优化可以用在任意RNN模型。
第一步:优化单次迭代
下列方程组表示了数据如何在LSTM单元正向传播。图2展示了LSTM单元的示意图。
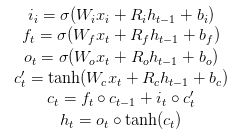

从计算的角度来看,这里需要8次矩阵的乘法运算(GEMM)—— 有四次对输入i,有四次对输入h —— 以及大量逐点运算。
这个案例分析的出发点是LSTM的逐步实现。对于每次迭代的每一层计算,系统调用cuBLAS sgemm分别来完成那8次GEMM运算。人工编写的CUDA内核调用每个逐点运算。这种方法的伪代码如下所示:
for layer in layers: for iteration in iterations: perform 4 SGEMMs on input from last layer perform 4 SGEMMs on input from last iteration perform point-wise operations我在Tesla M40 GPU上逐步、逐层地记录了运行耗时,作为对照数据。我的对照LSTM模型有512个隐藏单元,每批次的样本数为64.对照组的性能很一般,在M40上只达到了大约350 GFLOPs。这个GPU的峰值性能是6000 GFLOPs,因此还有很大的优化空间。我们开始吧。
优化1:组合GEMM操作
GPU有非常高的浮点数吞吐量峰值,但是需要大量的并行化才能达到这个峰值。你设计的任务越是并行化,能达到的性能越好。测试这段LSTM代码后发现,GEMM操作所用的CUDA thread block个数远远少于GPU的SM个数,也就是说GPU远未被充分利用。
GEMM往往在输出矩阵维度上做并行化,每个线程计算很多输出元素。在这里,8个输出矩阵的每一个都有512x64个元素,只用到4个thread block。理想情况下block的运行个数可以远大于GPU的SM个数,需要最大化这个内核的理论占用值,至少达到每个SM有4个block(或者总共96个)。(参见 CUDA Best Practices guide for more on occupancy)
如果n个独立的矩阵乘法共用同一份输入数据,那么它们可以被合并为一个大的矩阵乘法,输出结果扩大n倍。因此,第一个优化方法就是把递归阶段的四次W矩阵操作合并为一次,并且把输入数据的四次W矩阵操作也做合并。我们剩下了两个矩阵乘法,而不是原来的八个,但是每次结果扩大了四倍,并行能力扩大四倍(每个GMM有16个block)。这种优化在大部分框架中都很常见:很简单的变化确带来了显著的性能提升:代码运行速度大约翻倍。
优化2:流式GEMMS
尽管GEMMs被合并了,性能仍旧收到缺少并行的限制:尽管从4个提升到16个,但是我们的目标是至少96个。剩余的两个GEMM相互独立,因此它们可以用CUDA stream并行计算。这又将并行的block个数翻倍,达到了32个。
优化3:融合逐点运算
图3显示目前大部分的时间消耗在了逐点运算上。没必要在独立的内核中进行这些;将它们融合到同一个内核可以减少数据在全局内存中的传递,并且大大减少了内核加载的开销。

至此,我非常欣慰地看到单次迭代的性能改善:大部分的计算量在于GEMM,并且尽可能地做了并行计算。这种实现方法比对照组快了5倍,但是仍有提升的余地。
for layer in layers: for iteration in iterations: perform sgemm on input from last layer in stream A perform sgemm on input from last iteration in stream B wait for stream A and stream B perform point-wise operations in one kernel第二步:优化多次迭代
在RNN模型中,单次迭代的操作会被重复很多次。这也意味着很有必要让这些重复操作有效率地执行,即使需要先增加一部分开销。
优化4:预转置权重矩阵
在进行一次GEMM计算时,标准的BLAS接口允许我们对两个输入矩阵的任意一个做转置。两个矩阵是否转置的四种组合中,其中某几种组合会比其它几种算得更快或者更慢。这取决于方程组到计算过程的映射方式,可能使用了较慢版本的GEMM。通过预先对权重矩阵的转置操作,每一次迭代会略微快一些。尽管多了一步转置操作的开销,但是开销也不大,所以如果在多次迭代中用到了转置矩阵,也是值得的。
优化5:合并输入GEMMs
许多情况下,在RNN计算开始之时所有的输入就已经就绪。也就是说对这些输入的矩阵运算操作可以立即开始。这也意味着它们能够被合并为更大的GEMMs。尽管起初这似乎是件好事(合并的GEMMs有更好的并行化),递归GEMM的传递依赖于输入GEMMs的完成度。因此需要我们做出取舍:合并输入GEMMs使得操作的并行化程度更高,但也阻止了递归GEMMs的过程重叠。这里的最佳策略往往取决于RNN的超参数。在我们的例子里,合并两个输入GEMM是最合适的。
for layer in layers: transpose weight matrices for iteration in iterations / combination size: perform sgemm on combined input from last layer in stream A for sub-iteration in combination size: perform sgemm on input from last iteration in stream B wait for stream A wait for stream B for sub-iteration in combination size; perform pointwise operations in one kernel第三步:优化多个层次
最后一步是考虑层与层的优化。这里仍然有大量的并行化空间。图4显示了RNN的依赖关系图。某一层的第n次迭代仅依赖于该层的第n-1次迭代和前一层的第n次迭代,因此有可能在前一层结束之前开始下一层的计算。这相当有用;如果网络有两层,则并行能力提升一倍。
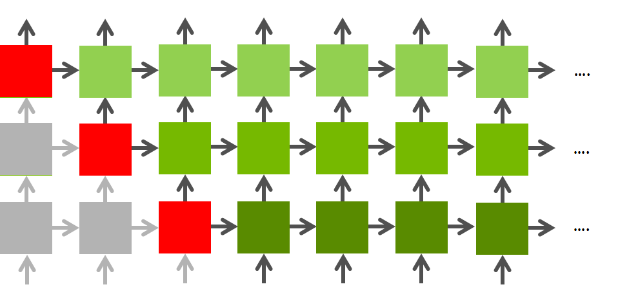
从一层网络到四层网络,吞吐量大约提升了1.7倍:从2.3TFLOPs到3.9TFLOPs。此时,并行化所带来的收益已经有限了。相比最初只有4个block的实现方法,这种方法可以同时运行128个block。这足以充分利用M40的资源,达到近70%的峰值浮点性能,运行速度比原来的快10倍。
下面的表格显示了我所描述的每一次优化之后的性能,以及相比于对照代码的效率提升。
| Optimization | GFLOPS | Speedup |
|---|---|---|
| Baseline | 349 | (1.0x) |
| Combined GEMMs | 724 | 2.1x |
| GEMM Streaming | 994 | 2.8x |
| Fused point-wise operations | 1942 | 5.5x |
| Matrix pre-transposition | 2199 | 6.3x |
| Combining Inputs | 2290 | 6.5x |
| Four layers | 3898 | 11.1x |
反向传播
反向传播梯度与值的正向传播非常相似。一旦梯度被传播,权重值将会被更新:不再有任何递归性的依赖。这使我们得到了一个非常大、非常高效的矩阵乘法。
总结
为了得到最好的性能,你需要经常要更多地提高并行性,而不是直截了当地实现方程。在cuDNN,我们将这些优化用在四种常见的RNN模型。因此如果你正在序列学习中用到这些RNN模型,我强烈推荐你使用cuDNN 5。
由CSDN重磅打造的 2016中国云计算技术大会 (CCTC 2016)将于5月13日-15日在北京举办,大会特设“中国Spark技术峰会”、“Container技术峰会”、“OpenStack技术峰会”、“大数据核心技术与应用实战峰会”等四大技术主题峰会,以及“云计算核心技术架构”、“云计算平台构建与实践”等专场技术论坛。80+位一线互联网公司的技术专家将到场分享他们在云计算、大数据领域的技术实践,目前大会剩票不多,欲购从速。详情请点击CCTC 2016大会官网。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

