(深度好文)重构CMDB,避免运维之耻
- CMDB,几乎是每个运维人都绕不过去的字眼,但又是很多运维人的痛,因为CMDB很少有成功的,因此我也把它称之为运维人的耻辱。
- 那么到底错在哪儿了?该如何去重构它?
- 今天我想从我的角度来和大家探讨一下业务失败的原因,基于失败再去看重构的逻辑,也许会成功。
从失败中寻找成功的逻辑,往往是最有效的,那我们就来逐一看看:
1、组织的设计问题
我必须把核心原因归结成这一条,很多公司把CMDB的建设责任放到基础设施建设部门,由他们主导承建。最后他们梳理出来的核心逻辑是面向基础设施资源的管理,你在他们的CMDB中都能看到如下菜单,AIX主机是哪些,中间件有哪些,大小机有哪些,Oracle有哪些等等,这些都是和公司的IT运维部门组织结构是一一对应的。组织的隔离是CMDB失败的核心原因!
这个里面能看到一些CMDB管理能力错位,拿两个例子来说一下:
A、中间件。
一直搞不明白为什么中间件要作为一个单独的对象来管理,“皮之不存,毛将附焉”。没有主机,没有业务这个皮,哪来的中间件。把他单独拿出来管理,纯粹就是为了满足组织的一个管理视角。从来没人想过,这是主机上的一个资源对象,应该是一个附属资源,其实对他的信息管理和机器上的CPU、网卡一样。
B、进程对象,比如说数据库
这个是另外一种管理错位,是专业的管理平台应该去履行的管理职责,结果放到CMDB平台中了,然后CMDB管理了大量的动态属性,比如主备关系,服务状态等等,太复杂了。最简单的看,从主机的角度来说,他就是服务器上运行的一个进程而已。管它死活干嘛,那是监控系统做的事情,管它状态干嘛,那是**组件管理平台干的事情。
2、Excel是最好的管理工具
当组织隔离,不能够形成有效的信息互动之后,Excel更是之上的一次痛击。可能从外围思考,为什么不去解决现实层面上的问题,而选择了Excel?Excel很简单,特别是IT服务对象不多的情况下,几百个还是能够应对的。我就拿个Excel记录一下,然后svn上小组内共享一下就好了,反正我的信息也就我使用,别的小组也不用(组织的隔离性)。对它的思考,还是要回归的第一点,使用Excel是结果,但我比较反对Excel做法。每次建设cmdb的第一个目标,就说要消灭掉Excel。
3、去简就繁
这个是从产品本身说的,我看了几个开源的产品,oneCMDB和iTOP(建议大家都体验一下),界面都是复杂的要命,还有商业的产品(具体哪家不说了)。
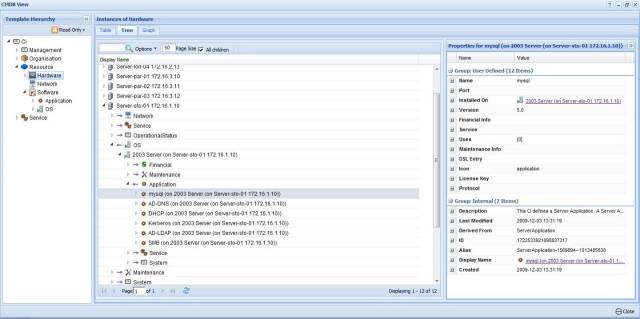
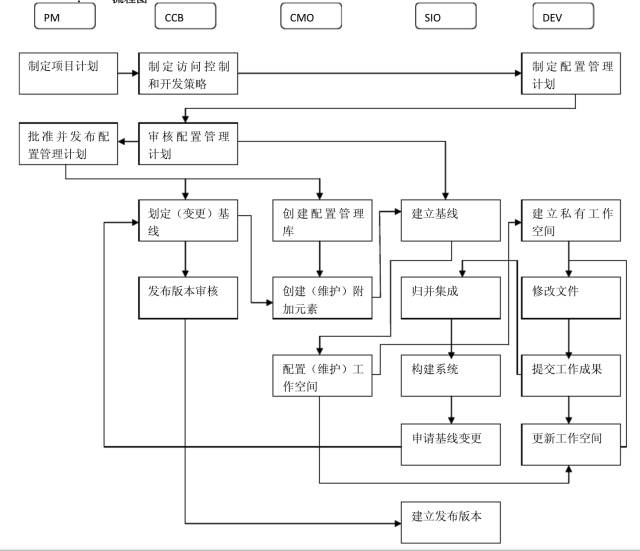
首先必须要解决产品易用性的问题,易用性不够,你怎么让能用户有使用的欲望呢,以下是来自于UC做的CMDB系统产品截图:
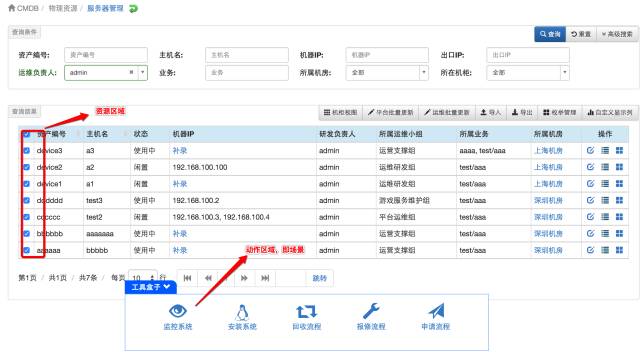
其次还有一种信息复杂带来的易用性下降的问题。我看很多产品都管理了一些无光的信息,信息的管理归类也是有考究的,没归类好,用户又被淹没了。
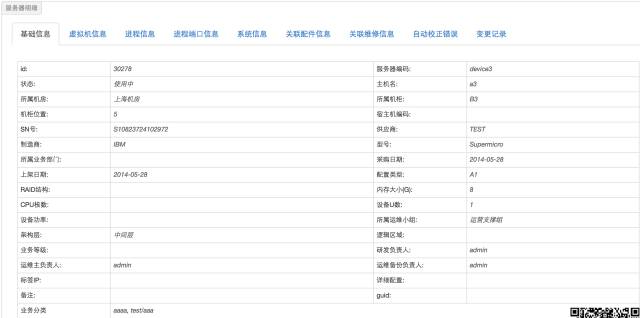
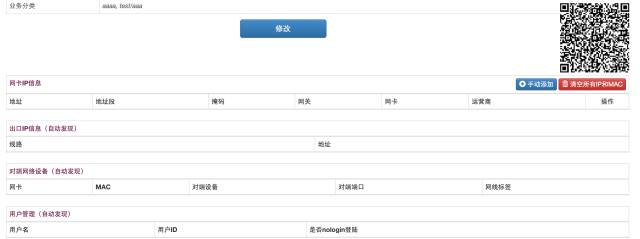
拿主机来说,维护其核心需要的信息就好了,比如说固资编号、所在机房的位置信息、厂家信息、上架信息、进程端口信息、维护信息等等。这些信息都是有运维场景的,比如说位置信息+固资信息在驻场需要操作的时候有用;上架信息对于过保维修有用;进程端口对于监控有用;维护信息在运维申请资源的时候有空,谁也不想用经常故障的机器吧;主机状态位是用来做资源池管理+监控使用的。
很多配置的变更都是因为场景变更引起的,比如说机器搬迁导致机器的物理位置信息发生变化,那就搞一个机器搬迁流程吧;机器上的业务下线了,但进程信息没有清理,那是业务下线流程的问题....
5、和应用没有关联,更别提场景关联了,就更别提主动场景了
很有意思的现象:客户的监控系统中监控的应用主机信息都是该系统中自行维护的,从来没有考虑从CMDB获取。也就是因为CMDB是另外一家产品,为啥呢?如果资源和应用关联起来了,并且由他来驱动监控,这个维护的动力是不是不一样呢?
哪怕是你的CMDB系统能够支撑一下我上图中的工具盒子的能力,CMDB维护的动力不至于那么糟糕,它的数据也不至于那么糟糕。之前和人探讨过是先有操作系统安装把信息写到CMDB还是先有CMDB的信息然后再有操作系统安装的动作?当然是后者了。事实上在服务器采购分配上机架的时候,其实所有的信息都分配完毕,此时入库,就可以启动远程自动安装了。
其实还有很多原因,比如说物理世界和逻辑世界是独立的,物理世界发生的过程没法直接映射到CMDB系统中(有些配置信息需要进入固件中);CMDB的对象Owner没有或者过多(Owner很累);过分强调CMDB的基线作用,引入对比(动态变化的环境基线的作用应该下降);夸大CMDB自动发现的作用等等。
说了很多的失败的原因,接下来就需要讨论一下解决方案了,既然讲重构,老王的重构逻辑是什么样的?
第一、重构你的CMDB思维
建议大家不要把CMDB称之为CMDB了,那叫什么,就叫资源管理吧。为什么你要从改名字开始?老是叫CMDB,大家都回到过去的思维上了,道不清说不明的,或者各执己见。
一切皆资源!!!一切皆资源!!!一切皆资源!!!
从基础设施的对象来说,计算资源、存储资源、网络资源、IP资源、机房资源等等,在CMDB的管理上,把你的资源对象罗列出来,关系梳理清楚,就可以构建其能力管理了。
从上层的业务资源来说,建立以应用为中心的资源管理逻辑,把 一切都看成应用的资源来看待。比如说Host,应用包、权限、RDS服务、cache资源等等。
老王现在做的产品把CMDB一分为二,底层的基础资源层CMDB可以不要。在不要的情况下,我可以构建上层应用的信息管理平台(业务CMDB),它可以独自构造场景来驱动上层运维。以下是优维EasyOps产品截图:
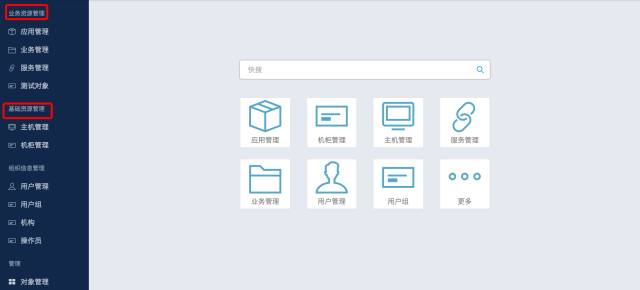
随着应用相关的一些支撑资源云化之后,面向应用的资源管理能力要不断加强。我经常和大家举的一个例子,是IaaS公有云平台中的Mysql实力已经是一个资源对象:实例域名。如何实现的对他们的管理,你只能把他当成一个附加资源来进行管理,不是么?
此时有意义的事情来了,你管理的业务资源信息越丰富,你的自动化驱动能力就越强。别再绕回去了,说让自动化来帮我维护这些信息。相辅相成、互相促进的事情,就不该设定前提,而是关注那个上升式的过程。
第二、重构你的CMDB方法
标准的CMDB方法是教你如何迭代进行一个CMDB项目,这个没有错误,但我会指出有些方法是你必须要坚持的,否则你的系统会面临失败。
A、放弃你的excel
excel是一个CMDB失败的佐证,必须去除它的存在,很多时候大家说是系统不好用引起的,但我的观察是大家的习惯引起的。改变习惯很难,有些时候需要借助组织自上而下的力量。没有集中的平台依赖,平台是没有人去驱动优化的。
B、构建CMDB的微内核和弹性CMDB模型库
CMDB的微内核很小,其实你只需要应用、集群和主机三个概念就可以构建起一个CMDB,基于这三个概念,可以不断去向周边扩散。应用可以往用户侧的概念不断靠拢,形成业务的概念。主机可以在其关联或者拥有的资源上不断去扩展,比如说主机所在的机柜、机柜所在的机房、机器关联的交换机等等。
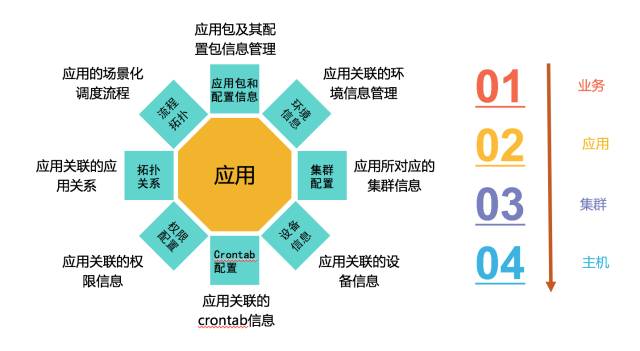
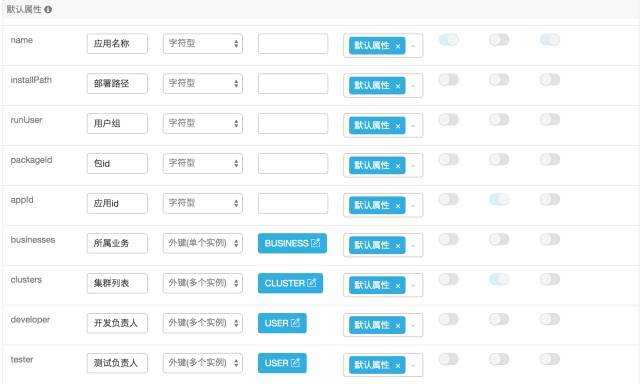
这个微内核,我想是可以适用一切场景了,但还不够呢,如何保证这个模型对所有企业做到落地可适配的?这个时候就是弹性模型的作用了。弹性模型由对象的弹性和对象CI及其关联的弹性定义实现的。简单的理解,你就是实现了一个业务数据库的可视化定义,下图是对象的弹性定义:

下图是对象的CI及其关联关系的弹性定义:
C、构建“自动发现+标准流程+人工维护”的CMDB数据库
自动发现是降低维护成本的一种有效方式,但我认为确保一个CMDB库信息的有效性,还是需要其他几个手段,标准化的流程和人工维护。
标准化的流程是运维资源信息变更的场景化流程梳理,比如说机房搬迁,服务器搬迁,服务器下架等等,这个流程需要识别出来,并确定相应的CMDB配置项状态变更过程。
人工维护,在有些流程没有构建起来的情况下,则需要通过人工变更的能力把CMDB信息维护准确,比如说主机所属负责人变更,这个时候不建议流程了,可以通过人工直接变更完成。那如何确保维护准确呢?通过外围系统来控制,比如说告警信息,如果负责人没有变更告警是直达原有负责人,导致告警不准确。
D、CMDB是持续迭代的过程
贪大求全求细、一步到位都是它的反义词,建议以微内核和核心需求为中心,快速实现,然后在此基础上快速迭代。随着底层云平台的出现,对CMDB都提出了新的要求,我们都知道,每一个IaaS都有一个自己的CMDB,如何实现对IaaS云的CMDB管理?Docker和其他类似服务化平台出现之后,又如何实现这类资源的管理?
E、边界、边界、边界
CMDB实现拓扑是为了故障定位,但不能实现故障定位;CMDB实现资源管理,可以去评估故障影响,但不能实现故障和变更影响评估;CMDB实现业务拓扑是为了快速的故障定位,但不能实现故障根因分析;一切都是因为在CMDB提供的数据基础之上,周边系统(变更、监控、发布)借助的CMDB提供的数据能力,实现自身的场景化系统能力。
第三、重构你的CMDB组织
围绕业务能力重构你的CMDB!!!
分离CMDB建设的层次和结构,独立建设不是没有可能,至少应该分离出两个CMDB系统--面向基础设施的资源管理系统和面向业务的资源管理系统。
面向基础设施的资源管理系统可以由数据中心的同事来建设,而面向业务的资源管理系统是由应用运维部门来构建。
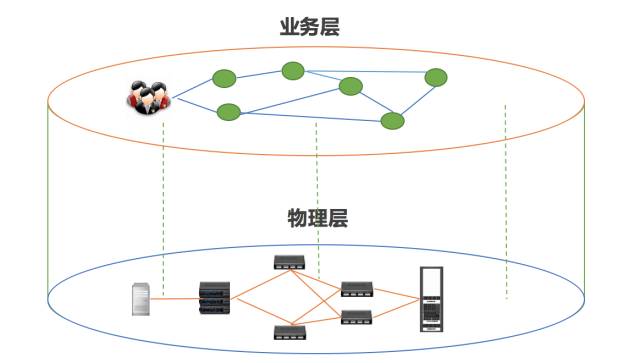
这两者没有先后之分,当然如果有底层的基础设施的资源管理,在其上构建业务的资源管理系统之后,数据的关联性会更强一些。
如果在两个职能管理分离的组织中,这个独立建设的必要性就更强了。比如腾讯,CMDB就是分两层的,一层是有网络平台部建设的面向基础资源的CMDB管理平台,另一层是业务的CMDB(是否叫CMDB已经不重要了),是各个业务部门建设的。
第四、重构你的CMDB产品形态
建立面向应用的资源管理CMDB!!!
核心是面向应用的CMDB产品思路要发生重大变化,仅仅聚焦在资源管理是远远不够的,资源是静态的。必须要建立一个逆向思维,不要从资源的角度维护资源,而是从应用的角度来维护资源。主机是什么?是应用的一个资源;Docker是什么?可以看成应用的附属资源;PaaS平台中分布式RDS服务是什么?是应用的附加资源等等。
这个形态要突出应用的核心位置,并以此为核心打造CMDB的管理入口,把资源管理、应用的场景维护等能力紧密集成起来。
第五、重构你的CMDB服务场景
经常大家都在说CMDB场景化,那真正的场景化到底是什么?
- 基于流程的场景识别
这是最传统的场景识别方式,通过ITIL认识到IT服务管理的核心流程,这些流程其实就是运维的场景。这个场景还有两个方面需要改进,第一在企业落地的过程中要结合实际,细分成一些核心流程;第二,具体的场景流程需要基于角色进行分类细化,比如说网络运维、服务器运维、机房运维、业务运维等等。
- 基于服务化的场景识别
我自己觉得这个场景很好归类,把角色+维护的IT服务对象二维考虑起来,把自动化+可视化当做目标,服务化(API化)的能力结果就是必然。同一个角色可能维护了很多IT服务对象,把这个IT服务对象的管理能力API化,供外部服务集成,IaaS云平台就提供了很好的示范。
- 基于应用交付流的场景识别
这个是应用运维场景的垂直识别。如果按照云计算的三个层次来说,IaaS和PaaS依然是底层的运维支撑能力,面向应用的运维能力才是真正直接作用于用户的。面向用户的价值流梳理对应的就是应用交付流的识别。里面有几个核心的场景:应用上线场景、应用维护升级场景、应用迁移场景、应用下线场景等等,贯穿了整个应用交付的生命周期管理。
最后,其实CMDB就是“资源+动作+状态”形成的统一入口
CMDB到底是什么?什么可以让CMDB成功?最近不断在思考这个问题。有天我回到了之前在UC维护的一些代理游戏业务,看过Gameloft的游戏管理后台,才找到CMDB的答案。后来又对照我们公司CTO黎明之前在腾讯做的织云全自动化平台,对这个答案就更加具体而明确了。
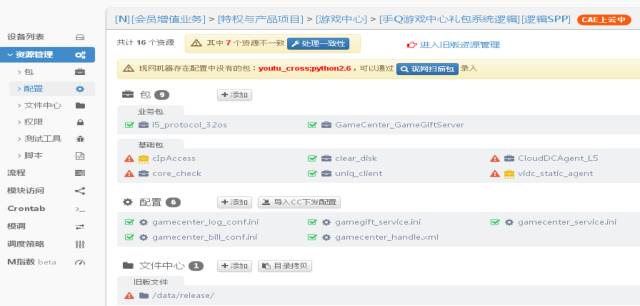
在游戏运维管理系统中,几个信息是关键且必不可少的:
- 游戏关联的资源。游戏运行的主机有哪些?主机上启动哪些进程和端口?进程和端口分别属于哪些区服(一般用端口来划分)?
- 游戏关联的运维场景。开区开服、合区合服等等。
- 游戏当前的状态。查看区服的用户数量,连接数,资源的状态等等。
由此就已经构成了一个强入口,这个强入口不断吸引游戏运维参与信息的维护,同时参与信息的变更过程。因此我也下断言,CMDB应该成为运维人的入口,不仅仅是静态信息的入口,而且是一个动态变更和状态管理的入口,把面向场景的运维编排集成到CMDB之中才是未来,否则在一个IT快速变化和组织弱约束的环境中,CMDB的失败还是不可避免。
谁让CMDB成为入口,谁就可以让CMDB成功!不过那时CMDB是不是叫CMDB就真的无所谓了!
文章来自互联网运维杂谈
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

