页面间跳转的性能优化(二)
版权声明:此文章如需转载请联系听云College团队成员阮小乙,邮箱:ruanqy#tingyun.com
续言
在页面间跳转的性能优化(一)中介绍了一些基础知识,讲述了情形一与情形二的优化方式及原理,但有许多人对情形二最后两种处理方式的原理表示不理解,不清楚处理过程,接下来会详细分步地讲述这两种方式的原理,如果你还没看过页面间跳转的性能优化(一),请先阅读。
页面间跳转的性能优化(一)
点击 https://github.com/IOSDelpan/SmoothTransitionDemo 下载Demo
页面间的跳转大致分为几个任务:
1.生成将即显示的页面视图
2.生成我们所需要的UI元素
3.生成页面跳转的动画
而这几个任务是在同一次Loop中执行的。我们知道每一次Loop都会检测图层树是否有更新,若图层树有更新,RunLoop会在观察者的回调函数_ZN2CA11Transaction17observer_callbackEP19__CFRunLoopObservermPv()执行完成时,发送图层树的更新到渲染服务进程进行绘制渲染,如果一次Loop的时间过长,这将会使图层树的更新延迟,这也就是我们所说的屏幕卡顿(CPU层面的卡顿)。为了解决页面跳转延迟,我们把原本在一次Loop中所需要执行的任务进行分解,分解成几次Loop来执行,这样就可以既不影响App的流畅度,也不影响UI的更新。
在Demo中,我们用GCD的方式来实现“在RunLoop下一次循环加载UI”。

调用dispatch_async()函数把生成UI元素的任务[self loadAllLabels]提交到GCD的主队列,在Application的主线程RunLoop进入下一次Loop时,会执行GCD主队列里面的任务,整个页面跳转的过程,即两次Loop的工作如下。
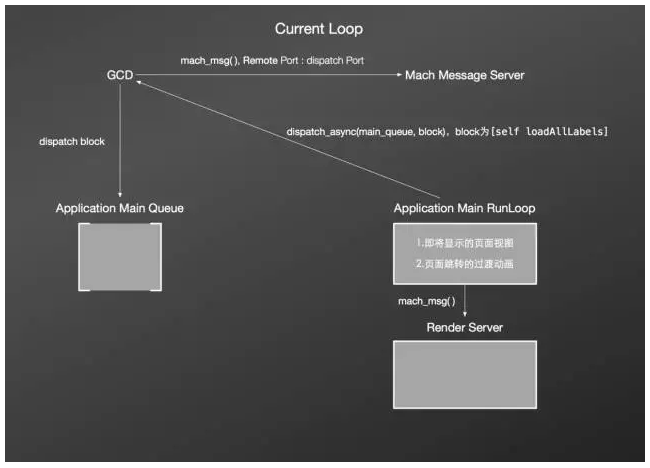
在第一次Loop中,把耗时的任务[self loadAllLabels]提交到Main Queue,生成即将显示的页面视图和页面跳转的过渡动画并发送到渲染服务进程进行绘制渲染,与此同时,由于Main Queue有任务待处理,GCD发送消息mach_msg()到Mach Message Server,目标端口为Application Main RunLoop的dispatch Port。
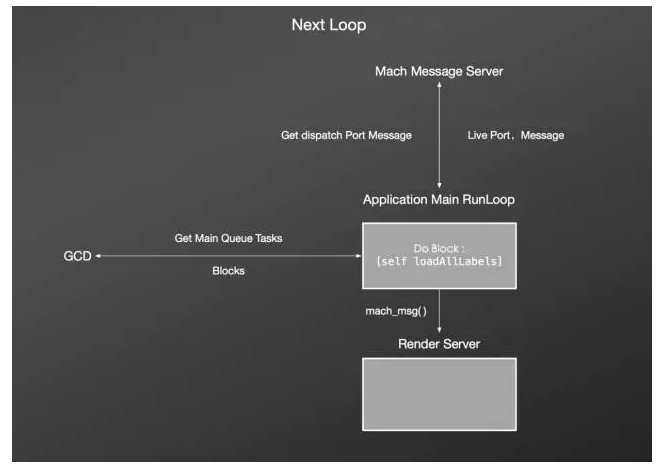
由于有端口事件待处理,RunLoop被唤醒并进入下一次Loop,RunLoop通过发送dispatch Port到Mach Message Server来接收dispatch Port的消息,当RunLoop接收到dispatch Port消息后,获取Main Queue待处理的任务[self loadAllLabels]并处理,处理完成后,把图层树的更新发送到渲染服务进程进行绘制渲染。
定时器处理方式的原理跟“在RunLoop下一次循环加载UI”的原理大致相同,但Loop的次数更多。

Main RunLoop的端口事件源基本分为三类,GCD事件,定时源事件,输入源事件(Source1),而这三类事件分别对应着三个不同的端口,dispatch Port,Timer Port和Source Port。每次Loop都会有两次检测是否有端口事件需要处理的机会,但是一次Loop只有一次机会处理端口事件,即在步骤5或步骤7触发处理端口事件。RunLoop在纯粹处理dispatch Port事件或Timer Port事件时,可以完整地运行一次RunLoop从被唤醒到进入休眠,即从步骤8返回到步骤7(顺序8,9,2,3,4,5,6,7),所以,可以用GCD异步嵌套的方式来实现跟定时器相同的效果。
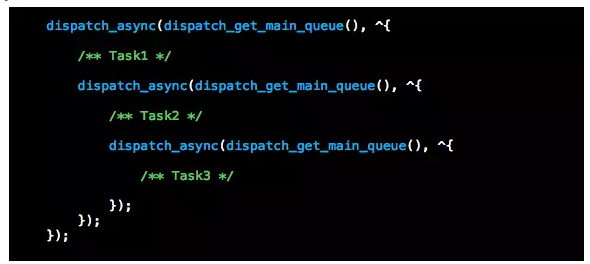

当Main RunLoop处理dispatch Port事件时,会获取Main Queue的所有待处理任务并处理,需要注意的是以下两种方式的实际执行过程是不一样的。

方式一是一次提交一个任务到Main Queue,即一次Loop处理一个任务,而方式二是一次提交三个任务到Main Queue,即一次处理完三个任务。

所以,方式二跟以下这种方式是一样的
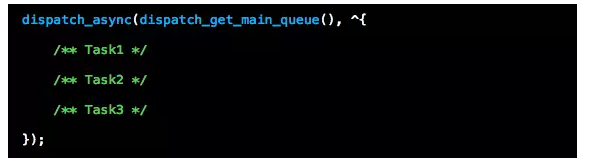
以上便是“在RunLoop下一次循环加载UI”处理方式的实现原理。
情形三

看到Gif图是否有种似曾相识的感觉?对头,这一情形是最普遍存在的,存在于大部份App当中,其中还不乏一些大厂出品的App。从这一情形的普遍程度也侧面反映出,其实绝大多数的团队都不会去做视图方面的性能优化,更不要说什么深入的优化了,不过还是能理解的,视图的性能优化并不是团队一两个人的事,开展起来各种困难。
情形一与情形二讲述了CPU方面的页面跳转延迟,除了CPU性能会导致页面跳转延迟外,GPU压力过大同样会出现性能问题,导致面页跳转时出现过场动画不流畅,缓慢等。从Gif图我们可以看到,整个跳转动画掉帧的情况非常严重,由于我们已经假定这一情形是由于GPU压力过大所导致,所以不再检测CPU方面的情况。

利用位图形变而强制GPU发生离屏渲染,在Demo中(根据你的机器情况,适当调整图位的数量来实现效果),有30个位图发生了形变,GPU需要进行30次离屏渲染,而且由于需要离屏渲染的位图寸尺比较大,所以大大增加了GPU的压力,使得整个动画出现了严重掉帧的情况,我们需要一个方法,既可以快速解决动画掉帧又不需要做页面的优化。

从Gif图我们可以看到,优化后页面跳转的整个过程并没有出现过场动画不流畅,缓慢等情况,即没有出现掉帧的情况。因为图层是绘制渲染的数据源,所以我们需要知道优化后图层树发生了什么变化。

优化原理是对视图控制器的图层做一次截图,把截图的结果设置为新图层的寄宿图,并把新图层添加到图层树中(没有与图层树相关联的图层不会被送到渲染引擎)。这种处理方式从CPU的层面看,Core Animation可以舍弃所有被完全遮盖住的图层,减少CPU的计算量,从GPU的层面看,GPU不需要再进行任何合成,直接Copy顶端纹理作为目标像素,减少了GPU的计算量,从而总体地提高了性能。每一种处理方式都很难做到两全其美,很多时候我们需要在时间密度与空间密度中做出选择,这种处理方式的缺点在于会增加内存的损耗,所以这种处理方式适合用于应急。对于Application如何保持高帧数,还是要从视图性能优化入手,这部份会在页面性能优化篇讲述。
总结
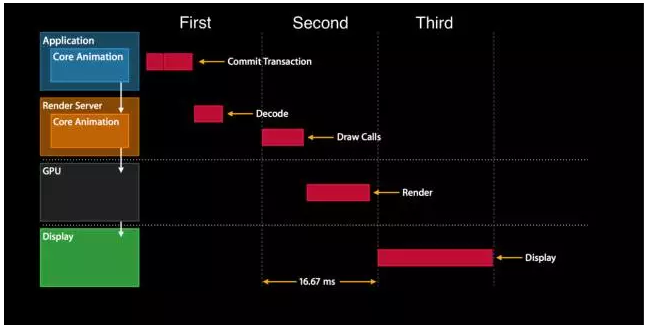
上图为WWDC2014讲述渲染模块所用的图(First,Second,Third是我加上去的)。这个图非常清晰地讲述了整个渲染过程,Application打包提交图层树并发送到渲染服务进程,渲染服务进程对图层树进行反序列化得到渲染树,利用渲染树绘制位图,GPU合成位图,最终显示出来。由上图得知,整个渲染过程分为三步,每一步都存在于独立的空间当中,即每一步都是存在于独立的帧里,iOS是以每秒60次速度刷新屏幕,即一秒60帧(fps),每一帧的时间为16.67ms,所以渲染过程的每一步理想的处理时间为16.67ms,若其中一步的处理时间超过16.67ms,就会导致屏幕刷新失败,即掉帧或屏幕卡顿,掉帧主要发生在第一步或第二步。
第一步的关键点在于Application Main RunLoop的每一次Loop是否及延时,而第二步的关键点则在于GPU的压力。从前面的讲述我们可以得知情形一,二,三的瓶颈处于那一步,情形一,二的瓶颈处于第一步,而情形三的瓶颈则处于第二步。
情形二主要讲述了如何把会阻塞主线程的UI任务进行分解,解决页面跳转延迟的问题。当UI任务会阻塞主线程,但阻塞的时间并不长的时候,可以选择用“在RunLoop下一次循环加载UI”的方式解决;如果UI任务会阻塞主线程且时间较长,可以选择用“GCD嵌套加载UI”把UI任务进一步分解的方式解决;如果UI任务会阻塞主线程且希望UI可以有序出现,可以选择用“定时器加载UI”的方式解决。
情形三主要讲述了怎么偷懒地解决页面跳转时出现过场动画不流畅,缓慢等问题,而处理方式适合用来应急,想Application保持高帧数,还是要从视图性能优化入手。 想阅读更多技术文章,请访问听云技术博客,访问听云官方网站感受更多应用性能优化魔力。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

