通用兴趣Feed的技术要点
一句废话:兴趣feed,就是按照兴趣相关重排序的feed。
温馨提示:要搜索 feed 相关技术文章,你应该用 Activity Stream 作为关键词去搜,而不应该只用"feed"搜索。 Activity Stream 之于 Feed,就好比多潘立酮之于吗丁啉。
整体逻辑
要实现一个兴趣feed,整体逻辑上是比较清楚的。可以划分为两个子问题:
-
如何实现一个 feed 系统?
-
如何给 feed 内容重排序?
我们先给出整体的逻辑框架,然后再分别详谈。
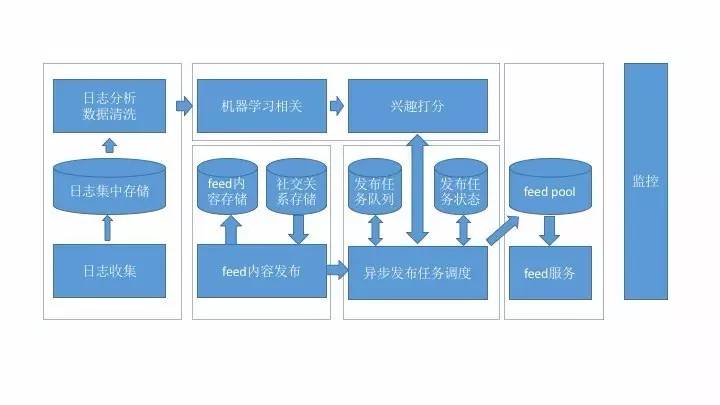 数据模型
数据模型
Feed 的基本数据有三个:用户(User)、内容(Activity)和关系(Connection)。 用户不用说,就是区别不同用户的身份。重点说一说 feed 的数据模型。
内容即 activity。表达 activity 的元素有相应的规范,叫做 Atom[1],可以参考它,并结合产品需求,定义出自己的feed数据模型来。
根据 Atom 的定义,一条 Activity 包含以下元素:
-
Time: activity 发生的时间。
-
Actor: activity 由谁发出的?通常 actor 就是用户ID,但是我们也可以扩展到其它拟人化物体上,如关注的一个“店铺”,收藏的一部“电影”
-
Verb: 动词,这个 activity 是哪一个动作?比如“follow”,“like”等
-
Object: 动作作用到最主要的对象,只能有一个
-
Target: 动作的最终目标,与 verb 有关,可以没有。它对应英语中介词to后接的事物,比如"John saved a movie to his wishlist"(John保存了一部电影到清单里),这里电影就是 Object,而清单就是 Target。
-
Title: 这个 activity 的标题,自然语言描述
-
Summary: 通常是一小段 HTML 代码,是对这个 activity 的描述,还可能包含类似缩略图这样的可视化元素,可以理解为 activity 的 view,不是必须的。
举个例子: 2016年5月6日23:51:01(Time) @刑无刀(Actor) 分享了(Verb) 一条微博(Object) 给 @ResysChina (Target)。Title 就是前面这句话去掉括号后的内容,Summary 暂略。
除了上面的字段外,还有一个ID,用于唯一标识一个 activity。社交电商 Etsy 在介绍他们的feed系统时,还创造性地给 activity 增加了 Owner 属性,同一个 activity 可以属于不同的用户[2]。
关系即连接。互联网产品里处处皆连接,有强有弱,好友关系,关注关系等社交是较强的连接,还有点赞,收藏,评论甚至浏览,这些动作都可以认为用户和另一个对象之间建立了连接。有了连接,就有 feed 的传递和发布。
定义一个连接的元素有:
-
from: 连接的发起方
-
to: 被连接方
-
type/name: 连接的类型/名字,关注,加好友,点赞,浏览,评论,等等
-
affinity: 连接的强弱
如果把建立一个连接视为一个 Activity 模型的话,from 就对应 Activity 中的 actor,to 就对应 Activity 中的 object。
将整个社交网络视为一个图。可以按照 from节点的邻接表来分解其中林林总总的连接关系。
连接的发起从 from 到 to,内容的流动从 to 到 from。Connection 和 Activity 是相互加强的,蛋和鸡的关系:有了 Activity,就会产生 Connection,有了 Connection,就可以喂(feed)给你更多的 Activity。
已有的轮子
-
Activity 存储: mysql/redis/cassandra
-
Connection 存储: mysql
-
User 存储: mysql
Feed 发布
用户登录/刷新后,feed 是怎么产生的?内容出现在受众的 feed 中,这个过程称为 Fan-out。
我们的直觉上是这样实现的:
-
获取用户所有连接的终点(如好友或者关注对象)
-
获取这些连接终点(关注对象)产生的新内容(Activity)
-
排序后输出
上面这个步骤别看简单,在一个小型的社交网络上,通常还是有效,而且twitter的早期也是这么做的[3]。

这就是行话说的“拉”模式(Fan-out-on-load),feed 是在用户登录/刷新后实时产生的。
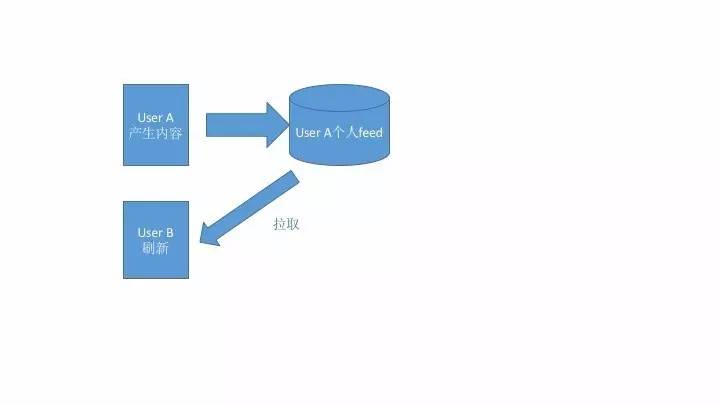
“拉”模式的好处有目共睹:
-
实现简单直接:一行sql就搞定了
-
实时:内容产生了,受众只要刷新就看得见
但是不足也是大写的:
-
随着连接数的增加,这个操作的复杂度是指数级增加的,显然不可取。
-
内存中腰保留每个人的产生的内容
-
服务很难做到高可用
与之对应,还有一个“推”模式(Fan-out-on-write)。
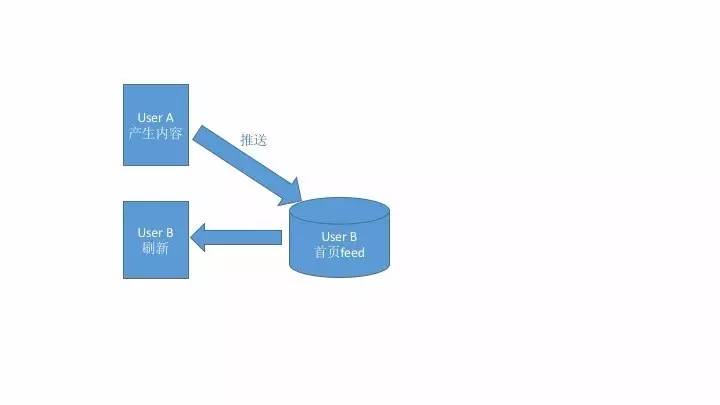 当一个 Actor 产生了一条 Activity 后,不管受众在不在线,刷没刷新,立即将这条内容推送给相应的用户(和这个 actor 建立了连接的人),系统为每一个用户单独开辟一个 feed 存储区域,用于接收推送的内容。如此一来,当用户登录后,系统只需要读取他自己的 feed 即可。
当一个 Actor 产生了一条 Activity 后,不管受众在不在线,刷没刷新,立即将这条内容推送给相应的用户(和这个 actor 建立了连接的人),系统为每一个用户单独开辟一个 feed 存储区域,用于接收推送的内容。如此一来,当用户登录后,系统只需要读取他自己的 feed 即可。
推模式的好处显而易见: 在用户访问自己的feed时,几乎没有任何复杂的查询操作,所以服务可用性较高。
推模式的不足:
-
大量的写操作:每一个粉丝都要写一次
-
大量的冗余存储:每一条内容都要存储N份(受众数量)
-
非实时:一条内容产生后,有一定的延迟才会到达受众feed中
既然两者各有优劣,那么实际上就应该将两者结合起来。
一种简单的结合方案是全局的:
-
对于活跃度高的用户,使用推模式,每次他们刷新时不用等待太久,而且内容页相对多一些
-
对于活跃度没有那么高的用户,使用拉模式,当他们登录时才拉取最新的内容
-
对于热门的内容生产者,缓存其最新的N条内容,用于不同场景下拉取
还有一种结合方案是分用户的,这是 Etsy 的设计方案[2]:
-
如果受众用户与内容产生用户之间的亲密度高,则优先推送,因为更可能被这个受众所感兴趣
-
如果受众用户与内容产生用户之间的亲密度低,则推迟推送或者不推送
-
也不是完全遵循亲密度顺序,而是采用与之相关的概率
在中小型的社交网络上,采用纯 push 模式就够用了,结合的方案可以等业务发展到一定规模后再考虑。
已有的轮子
-
用户feed的存储: redis, uid为key
-
feed推送的任务队列: celery
celery是一个开源的分布式异步任务队列,python语言,它与常用的消息队列(redis, RabbitMQ等)结合使用,很容易做到水平扩展。
用户只需要定义任务处理方法即可,其余的celery都帮你处理了。还可以将多个处理方法串成一个异步的chain,从而构建自己的pipeline。
celery还能做定时任务,周期任务。
具体到兴趣feed系统中,每当一个用户发布一条动态,我们就产生一个celery的任务,这个任务就是做兴趣预测和动态推送,它是准实时的异步任务,不会阻塞feed的读取和写入。
排序算法
兴趣feed的排序,要避免陷入两个误区:
-
没有目标
-
人工量化
第一个误区意思就是:设计排序算法之前,一定要先弄清楚为什么要对时间序重排?希望达到什么目标?我们这里假设兴趣排序要提高互动率:即希望用户对feed里面的内容互动比例越高越好。所以这里的目标就是:提高互动率。只有先确定目标,才能检验和优化算法。
第二个误区是人工量化。也就是我们通常见到的产品同学或者运营同学要求对某个因素加权、降权。这样做很不明智,因为人的知识利于做启发,不利于做量化。我们很多算法理论上可以得到最优参数,但是所需时间可能是无法承受的,这时候如果有丰富领域知识的人给一些有用的信息,就能大大缩小算法参数的搜索空间,从而在可接受的时间内搜索到效果可以接受的参数。
人可以告诉算法很多可能有用的排序因素,缩短效果提升的路径,但是人直接指定参数的权重,对效果提升来说基本上有百害而无一利。
基于上述经验,我们从机器学习思路来简单设计一个优化互动率的兴趣feed。
首先,定义好互动行为包括哪些,比如点赞,转发,评论,查看详情等。 其次,区分好正向互动和负向互动,比如隐藏某条内容,点击不感兴趣等是负向的互动。
基本上到这里就可以设计成一个典型的二分类监督学习问题了,对一条feed的内容,在展示给用户之前,预测其获得用户正向互动的概率,概率就可以作为兴趣排序分数输出。
能产生概率输出的二分类算法都可以用在这里:贝叶斯,最大熵,逻辑回归等。互联网常用的是 Logistic Regression,谁用谁知道,反正用过的都说好:
-
线性模型,足够简单
-
产生0-1之间的输出,互相可以比较
-
开源实现多,初始技术成本小
-
工业界已经反复验证过
-
...
分类器需要特征输入,一条feed内容推送给一个用户,特征可以分三类:
-
用户特征,包括用户人口统计学属性,用户兴趣标签,活跃程度等。
-
内容特征,一条内容本身可以根据其属性提取文本、图像、音频等特征,并且可以利用 Topic Model 提取更抽象的特征。
-
其他特征,比如刷新时间,所处页面等。
在算法选定后,人工可以花很多力气在寻找新特征上,这就是传说中的“特征工程”,特征工程还包括对已有的特征进行选择,选择的目的是:
-
控制模型的维度,降低复杂度
-
去掉信号小的特征,提高效果
工程上常用的特征选择有很多,可以参考我的朋友严林在知乎上的答案[5]。 关于特征工程,还可以参考[6]。工程上,特征工程比算法要重要很多,方法有一些,但是领域差别大,具体不再赘述。
在线使用排序算法时,可以做成 RPC 服务,以供发布feed时调用。
已有的轮子
-
RPC 框架:thrift,FB开源,支持多语言,包括C、C++、Java、Python、PHP等
-
模型训练:vowpal wabbit,分布式机器学习框架,可以和Hadoop轻松结合
-
特征工程:python (ipython notebook) 或者 R (RStudio Server).
数据和效果追踪
既要通过历史数据来寻找算法的最优参数,又要通过新的数据验证排序效果。 所以搭建一个数据流通的 pipeline 也是兴趣feed系统必须的。
相关数据:
-
目标有关的互动行为数据(记录每一个用户在feed上的操作行为)
-
曝光给用户的内容(一条曝光要有唯一的ID,曝光的内容仅记录ID即可)
-
互动行为与曝光的映射关系(每条互动数据要对应到一条曝光数据)
-
用户profile(提供用户特征,来自离线挖掘和数据同步)
-
feed内容分析数据(提供内容特征)
对于一个初级的兴趣feed,没必要做到在线实时更新排序算法的参数,所以数据的 pipeline 可以借鉴 Pinterest 的 pipeline,具体见上一篇。

如果选用 LR 预测互动行为排序feed的话,在离线时关注模型的 AUC[7] 是否有提升。AB测试时关注具体的产品目标是否有提升,比如互动率等,同时还要根据产品具体形态关注一些辅助指标。
另外,互动数据相比全部曝光数据,数量会小得多,所以在生成训练数据时需要对负样本(展示了却没有产生互动的样本)进行采样,采样比例也是一个可以优化的参数,固定算法和特征后,在0.1-0.9之间遍历对比实验,选择最佳的正负比例即可,经验比例在2:3左右,即负样本略大于正样本,你可以用这个比例做启发式搜索。
已有的轮子
-
日志存储:HDFS
-
训练样本生成:Hive
-
效果追踪:Hive
其他
还需要有:
-
一个提供 feed API 的服务
-
系统指标收集及监控
-
服务监控及管理
已有的轮子
-
feed API: tornado
-
监控指标收集:StatsD,Nodejs 服务
-
监控指标可视化:Graphite,Django 服务
-
python进程管理:supervisor
-
API 反向代理:nginx
最后的最后
本文逐一梳理了实现一个通用兴趣feed的关键模块,及其已有的轮子,从而能最大限度的降低开发成本。
这些对于一个中小型的社交网络来说已经足够,当你面临更大的社交网络,会有更多复杂的情况出现,尤其是系统上的。所以,壮士,请好自为之,时刻观察系统的监控,日志的规模。
最后再补充三点:
-
准备上兴趣feed之前先想清楚,是否真的需要这样做。
-
以上整个系统框架已有开源实现,作者本人也是把剧本演到最后才发现:如不自宫,也可成功[8]。
-
学挖掘机到蓝翔,学推荐系统,到 ResysChina。
[1] http://activitystrea.ms/specs/atom/1.0/
[2] http://www.slideshare.net/danmckinley/etsy-activity-feeds-architecture
[3] http://www.slideshare.net/nkallen/q-con-3770885
[4] http://www.slideshare.net/cevin/timyang
[5] https://www.zhihu.com/question/28641663/answer/41653367
[6] http://machinelearningmastery.com/an-introduction-to-feature-selection/
[7] https://en.wikipedia.org/wiki/Area_under_the_curve_(pharmacokinetics)
[8] https://github.com/tschellenbach/Stream-Framework
本文为系列文章之一,包括:
-
为什么应该关注兴趣Feed?
-
关于 Facebook NewsFeed,看这一篇就够了!
-
Pinterest 的 Smart Feed 架构与算法
-
通用兴趣Feed的技术要点(本篇)
全系列完。
作者简介:陈开江@刑无刀
-
2013年之前在新浪微博搜索部和商业产品部任资深算法工程师,先后负责过微博反垃圾、基础数据挖掘、智能客服平台、个性化推荐等产品的后端算法。
-
2012-2013领导翻译了《机器学习:实用案例解析》一书。
-
2013年末加入传统媒体公司车语传媒,任算法主管,负责从零打造公司转型产品考拉FM的个性化推荐系统,如今个性化推荐已成为考拉FM与其他FM之间最大差异化特性。
-
2015年初,离职创业,公司拿到IDG和晨兴资本的天使投资,产品几经调整,如今专注在用视频分享购物经验,App名称:边逛边聊。
微信公众号【 ResysChina 】,中国最专业的个性化推荐技术社区。
点击阅读原文,可以查看上一篇《 Pinterest 的 Smart Feed 架构与算法 》
正文到此结束
- 本文标签: tar UI GitHub HTML REST 同步 关键词 微信公众号 测试 sql API App list 微博 http 2015 翻译 js HDFS 管理 智能 key 开源 ECS 文章 Nginx https 标题 领导 CTO 消息队列 重排序 运营 数据挖掘 PHP git 产品 Facebook 空间 Select 开发 统计 python java ip 互联网 IDE 时间 遍历 缩小 src Architect Twitter mysql node 进程 redis 需求 解析 缩略图 Connection 数据模型 社交网络 创业 数据 代码 Cassandra 参数 投资 ACE Atom Hadoop
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

