每日一博 | HBase 之 HFile 存储
原 荐 HBase之HFile存储
发表于9小时前(2016-05-11 23:51) 阅读( 90 ) | 评论() 0 人收藏此文章,
赞 0
上海源创会5月15日与你相约【玫瑰里】,赶快来约哦~!>>> 
摘要 HBase是一个分布式的、持久的、强一致性的存储系统,具有近似最优的写性能(能使IO利用率达到饱和)和出色的读性能,它充分利用了磁盘空间,支持特定的列族切换,可选压缩算法。
基本概念
- 表(Table),数据的组织形式
- 行(Row),Table中的每一行
- 列族(Column Family),一行中有多个列,以Column Family进行分组,同一Column Family的列存储在同一个底层文件(HFile)中,所以Column Family会影响数据的物理存储,一般在表创建的时候,就需要指定好,并且不要轻易修改。
- 列(Column Qualifier),这个不需要创建表的时候就指定。
- 单元格(Cell),一组Row、Family、Qualifier可以定位一个Cell。
- 时间戳(Timestamp),一个单元格中的数据是由版本的,版本以Timestamp来区分。默认写入的是当前的timestamp,读取的是最新的timestamp的数据。HBase默认一个单元格保存三个版本。
所以,一个HBase的Table存取模式为:
` (Table, RowKey, Family, Qualifier, Timestamp) -> Value
一个Table存取等价于高级语言的一个map: ``SortedMap<RowKey, List<SortedMap<Qualifier, List<
Value, Timestamp > > >
` 或者,再直观一点,逻辑上等价于一个固定格式的Json:
` { "RowKey1" { "Family1": { "Qualifier11":{ "Timestamp111":"Value111" } "Qualifier12":{ "Timestamp121":"Value121", "Timestamp122":"Value122" } }
"Family2" : { "Qualifier21":{ "Timestamp211":"Value211" } } } "RowKey2" { ... } } ```
HFile存储单元
也叫StoreFile, google论文中是SSTable ,是数据存储的地方,HBase之所以是面向列的数据库,是因为数据以key-value形式存储的,列可以动态扩展
KeyValue
当put到hbase一个key和value的时候,会增加一条记录:
` (Table, RowKey, Family, Qualifier, Timestamp) -> Value
` 该记录以字节流的方式存储,对应到磁盘中的存储格式为:
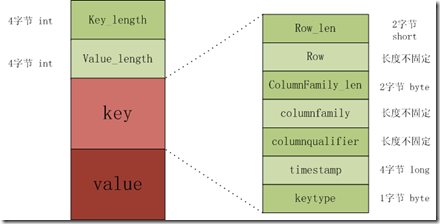
- Key Length(32位整形)
- Value Length(32位整形)
- Key
- Row Length
- Row(即:rowKey)
- Column Family Length
- Column Family
- Column Qualifier(Qulifier的长度可以通过Key Length、Row Length、Column Family Length、Timestamp固定长度、KeyType固定类型计算出来)
- Timestamp
- KeyType (Put, Delete, DeleteColumn, DeleteFamily等类型)
- Value KeyValue是一个基本的单元模块,不可再分,例如:BlockData默认为64K,但是如果有一个KeyValue是8MB,一样会整体写进去,这个BlockData的大小是后检查的,插入数据后,再检查是否超过默认值。
BlockData
多个KeyValue结构,按照Key递增的顺序,组成一个BlockData(默认64K),BlockData在HFile存在磁盘中的存储方式为: 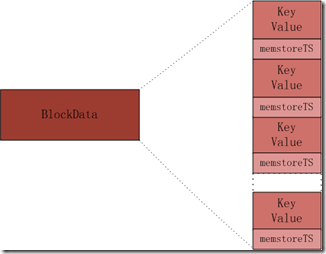
DataBlock
DataBlock是对BlockData的进一步封装,在BlockData基础上,增加了一个8字节的标志位,magic number,用来标记BlockData的类型,常见的标记类型有: * DATA,就是BlockData类型 * LEAF INDEX,叶子索引块 * BLOOM CHUNK ,Bloom filter块(Bloom Filter是采用位hash标记,常数时间内可以判断key是否存在的一种数据结构) * ...(等等)
HFile
由以下四部分组成: * Scanned Block section,扫描数据存储部分 + Data Block,数据块 + leaf block index,索引块 + Bloom chunk blocks,Bloom chunk块 * Non-scanned block section,非扫描数据存储部分 + Meta Block + intermediate-level index blocks * load-on-open section,打开HFile文件的时候,这部分需要加载到内存,包括文件信息和索引信息。 * Trailer,一个固定长度,记录了HFile的基本信息、各个部分的偏移值和寻址信息。
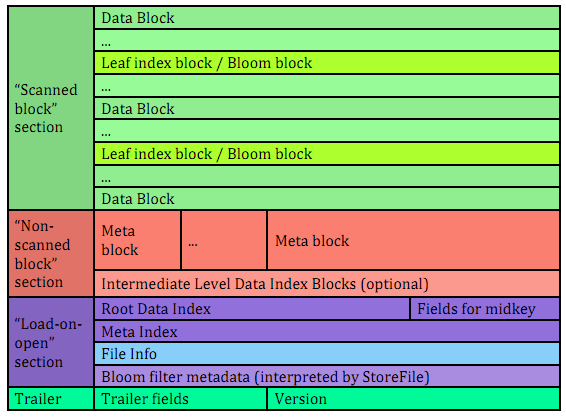
HFile V1、V2和V3
- V1,HBase0.92之前,结构简单,当数据增多的时候,每个HFile的BloomFilter会有100M多,当超过20个region的时候,会有2G,Block indexes会有6G,Region需要将所有的索引load完,才认为是正确加载了,速度非常慢。
- V2,加速了regions server的启动,同时,采用load-on-open这个部分加载到完,Region就算是正确加载了。
- V3,HBase0.98之后引入,在File Trailer中增加了encryption_key,支持AES对当前的HFile加密。
查找rowKey过程:
- HFile内部是有序的,但是HFile之间是无序的
- 判断key是否存在Hfile中,可以通过Leaf index或者Bloom Filter
- HBase将rowKey可能存在的所有HFile中的最小的rowKey,进行排序(rowKey、column升序,timestamp降序),然后放入队列中
参考资料
官方文档
Transcript of HBase for Architects Presentation
《HBase权威指南》
转载请注明出处:http://my.oschina.net/serverx
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

