聊天机器人中的深度学习技术(引言)
原文链接: DEEP LEARNING FOR CHATBOTS, PART 1 – INTRODUCTION
译者:刘翔宇 审核:赵屹华
责编:周建丁(zhoujd@csdn.net)
聊天机器人,又被称为会话代理或者对话系统,它是一个热门的话题。微软在聊天机器人上下了 很大的成本 ,Facebook(M),苹果公司(Siri),谷歌,微信,和Slack也是如此。聊天机器人在初创公司中掀起了一种新浪潮,他们试图通过建立类似于 Operator 或 x.ai 这样的应用程序,类似于 Chatfuel 这样的平台以及类似 Howdy’s Botkit 这样的机器人库来改变消费者与服务的交互。最近微软发布了自己的 机器人开发者框架 。
许多公司都希望开发出有人类水准能够进行自然对话的机器人,并且许多公司都声称使用自然语言处理和深度学习技术来实现。但是随着AI被大肆炒作,很难将事实与虚幻区分开来。
在本系列中,我会介绍用于构建会话代理所用到的一些深度学习技术,首先我将阐述我们目前所处的阶段,哪些可能实现,以及又有哪些,至少在短期内几乎不可能实现。这篇文章将作为一个介绍,我们会在接下来的文章中深入讲解实现细节。
模型分类法
基于检索(Retrieval-Based)与生成模型(Generative Models)
基于检索的模型(更容易) 使用一套预定义的响应和一些启发式方法,根据输入和上下文来选择适当响应。启发式方法可以和基于规则表达式匹配一样简单,也可以和组合机器学习分类器一样复杂。这些系统不产生任何新的文本,它们只是从固定的数据集中选择响应。
生成模型(更困难) 不依赖于预定义的响应。它们从头开始生成新的响应。生成模型通常基于机器翻译技术,只不过不是将一门语言翻译成另一门语言,而是将一个输入“翻译”成一个输出(响应)。
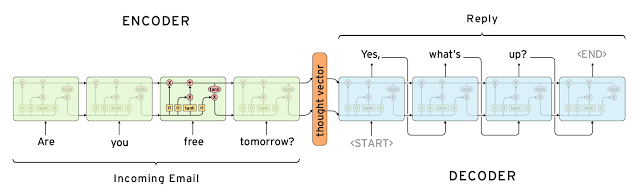
这两种方法都有一些明显的优点和缺点。由于有一套人工响应,基于检索的方法不会犯语法错误。然而,它们可能无法处理未知情况下的数据,因为没有合适的预定义的响应。出于同样的原因,这些模型不能引用回上下文中实体的信息,比如前面会话中提到的人名。生成模型就“更聪明”了。它们可以引用到输入中的实体,并让你觉得你在与一个人在交谈。然而,这些模型很难训练,很容易犯语法错误(特别是语句比较长的时候),这些模型通常也需要大量的训练数据。
深度学习技术可以同时用于基于检索模型和生成模型,但是研究者似乎往生成模型方面研究。类似于 序列-序列 (Sequence to Sequence )的深度学习架构唯一适用于生成文本,研究人员希望在这一领域取得突破。但是,我们仍处于构建合理工作的生成模型的初级阶段。目前来说生产系统更多的是使用基于检索的模型。
长对话与短对话
对话越长,越难以自动化。短文本对话(更容易)的目标是创建一个针对一个输入的响应。比如你收到一个用户的提问然后回复一个合适的答案。长对话(更困难)需要转多个弯,而且还要跟上对话的节奏。客户支持对话通常是有很多提问的长对话。
开域(Open Domain )与闭域(Closed Domain)
在 开域(更困难) 中设定了用户可以随时随地通话。不一定要有一个明确的目标或意图。在诸如Twitter和Reddit这样的社交媒体网站上的对话是开域的——它们可以是任何方面的。无限的主题和一定数量关于世界知识的必要性使得创造合理的响应比较困难。
在 闭域(更容易) 中设定了可能的输入和输出的有限空间,因为系统是为了实现某一特定目标。客户技术支持和购物助手就是闭域的例子。这些系统不需要能够谈论政治,它们只需要尽可能高效地完成它们特定的任务。当然,用户仍然可以在任何地方发起对话,但是系统并不要求能够处理所有的情况——用户也不指望它能这么做。
共同挑战
构建对话代理的时候有一些明显和不那么明显的挑战,其中大部分属于活跃的研究领域。
结合上下文
要产生有意义的响应系统可能需要结合语境和物理环境。在长对话中,人们会记住说了什么以及交换了什么信息。这是语境的一个例子。最常见的方法是将对话 放到 一个向量中,但是在长对话中这么做是具有挑战性的。 Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models 和 Attention with Intention for a Neural Network Conversation Model 中的实验都属于这方面。可能还需要加入其它上下文数据,比如日期/时间,地点,或者用户信息。
相干个性(Coherent Personality)
代理在产生响应时,应当对语义相同的输入产生一致的答案。比如,当你问“你多大了?”和“你年龄多少?”时,你想得到相同的答案。这听起来很简单,但是将这种固定的知识或“个性化”与模型结合还属于研究课题。许多系统学习产生语义似乎合理的响应,但它们没有被训练来产生语义一致的响应。通常这是因为它们在来自于很多不同用户数据上训练而成。 A Persona-Based Neural Conversation Model 中的模型在明确建模个性化方向迈出了第一步。

模型评估
评估一个会话代理的理想方法是测试它是否履行了其任务,例如在一个给定的对话中解决客户支持问题。但是这样的标签很难获得,因为这需要人工判断和评估。有时候没有明确定义的目标,比如在开域模型的情况下。机器翻译中常见的指标,比如 BLEU ,基于文本匹配的方法在这里并不合适,因为合理的响应可以包含完全不同的词或短语。事实上,在 How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation 中,研究人员发现没有一个常用的指标与人类判断相符。
意图和多样性
生成系统的一个常见问题是它们往往会产生适用于许多输入样例的通用响应,比如“那太棒了!”或者“我不知道”。谷歌Smart Reply的早期版本 往往会对任何事情回复“我爱你” 。这可能是这些系统的训练方式导致的,无论是在数据方面还是实际训练的目标/算法上。 一些研究人员试图通过各种目标函数来人工促进多样性 。然而,人类通常产生针对特定输入以及带有意图的响应。因为生成系统(尤其是开域系统)并没有被训练有特定意图,所以它们缺少这种多样性。
它实际效果如何?
鉴于目前所有的尖端研究,我们处在哪个阶段以及这些系统实际工作效果如何?让我们再次考虑我们所说的分类。一个基于检索的开域系统很明显不可能实现,因为你不可能指定对于所有情况下足够的响应。一个生成模型的开域系统几乎就是强人工智能(AGI)了,因为它需要处理所有可能出现的情况。这同样遥不可及(但是有大量的研究正在朝这方面努力)。
这就给我们带来了这样一个问题,生成模型和基于检索的方法在闭域中都适用。对话越长,上下文越重要,那么问题也变的越复杂。
在最近的 一次采访 中,百度首席科学家吴恩达这么说:
如今深度学习大多数的价值是在狭窄领域,你可以从中获取大量数据。而下面这个例子是它做不到的:进行一场有意义的对话。如果你择优挑选对话,你会觉得它看起来有意义,但是如果你自己进行这么一场对话的话,你就会发现不同了。
许多公司将他们的对话外包给其他人,并且承诺一旦他们收集到足够的数据他们可以将对话“自动化”。这只可能在狭窄领域的情况下实现——比如Uber聊天接口。任何开放一点的领域(比如销售电子邮件)都超出了我们的能力范围。但是,我们可以使用这些系统进行提议和修正响应来帮助人类。这就更加可行了。
生产系统中的语法错误代价是非常昂贵的,它可能会造成用户流失。这就是为什么大多数系统还是选择使用基于检索的方法,这样可以避免语法错误和无礼的响应。如果公司能够得到海量的数据,那么生成模型的方式是可行的——但是它们需要 类似微软的Tay 那样使用其他技术来防止偏离主题。
未来章节和阅读列表
在接下来的文章中,我们将讲述使用深度学习实现基于检索和生成会话模型的技术细节,如果你对一些研究感兴趣,你可以阅读下面这些论文来作为铺垫:
- Neural Responding Machine for Short-Text Conversation (2015-03)
- A Neural Conversational Model (2015-06)
- A Neural Network Approach to Context-Sensitive Generation of Conversational Responses (2015-06)
- The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems (2015-06)
- Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models (2015-07)
- A Diversity-Promoting Objective Function for Neural Conversation Models (2015-10)
- Attention with Intention for a Neural Network Conversation Model (2015-10)
- Improved Deep Learning Baselines for Ubuntu Corpus Dialogs (2015-10)
- A Survey of Available Corpora for Building Data-Driven Dialogue Systems (2015-12)
- Incorporating Copying Mechanism in Sequence-to-Sequence Learning (2016-03)
- A Persona-Based Neural Conversation Model (2016-03)
- How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation (2016-03)
由CSDN重磅打造的2016中国云计算技术大会(CCTC 2016)将于5月13日-15日在北京举办,大会特设“中国Spark技术峰会”、“Container技术峰会”、“OpenStack技术峰会”、“大数据核心技术与应用实战峰会”等四大技术主题峰会,以及“云计算核心技术架构”、“云计算平台构建与实践”等专场技术论坛。80+位一线互联网公司的技术专家将到场分享他们在云计算、大数据领域的技术实践,目前大会剩票不多,欲购从速。详情请点击CCTC 2016大会官网。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

