Java中的几个HashMap/ConcurrentHashMap实现分析
一、HashMap,即java.util.HashMap
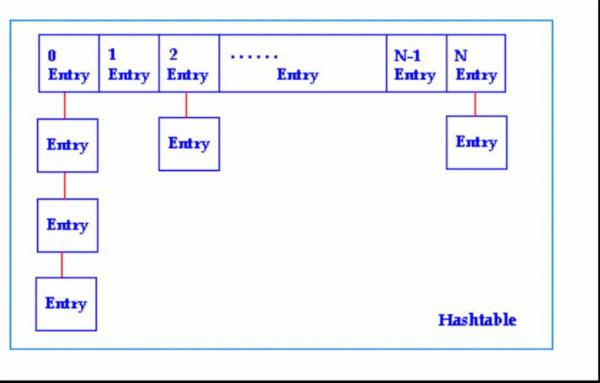
标准链地址法实现。这个不用多解析,下图十分明了。(图片来自网络)
二、Collections.synchronizedMap() 函数返回的线程安全的HashMap
这个的实现比较简单。
代码中有:
private final Map<K,V> m; // Backing Map final Object mutex;// Object on which to synchronize
基本所有的方法都加上了synchronized(mutex)。
但是这个HashMap不能随便地进行迭代,因为它只是简单包装了HashMap,而回看HashMap的实现,我们可以发现,对于冲突的key,形成一个链表,明显如果有一个线程在历遍HashMap,另一个线程在做删除操作,则很有可能出错。
因此,JDK中给出以下代码:
Map m = Collections.synchronizedMap(new HashMap()); ... Set s = m.keySet(); // Needn't be in synchronized block ... synchronized(m) { // Synchronizing on m, not s! Iterator i = s.iterator(); // Must be in synchronized block while (i.hasNext()) foo(i.next()); } 三、ConcurrentHashMap
对于HashMap,最主要的是以下四种的操作:
public V get(Object key) public V put(K key, V value) public V remove(Object key) 迭代
在多线程环境下,get,put,remove都是比较容易实现的(如果不考虑效率,简单加锁即可),迭代的操作才是真正的难点。
从Collections.synchronizedMap()的迭代来看,它并不能做到对客户代码透明,有点蛋疼。
下面简单分析ConcurrentHashMap的实现,相当精巧。
默认一个ConcurrentHashMap中有16个子HashMap,所以相当于一个二级哈希。对于所有的操作都是先定位到子HashMap,再作相应的操作。
对于:
public V get(Object key)
先得到 key所在的table,再像HashMap一样get中间并不加锁
public V put(K key, V value)
先得到所属的table,加锁
判断table是否要扩容
如果table要扩容,则产生newTable
hash值相同的slot整体移到newTable
hash值不同的slot,把oldTable中的所有Entry都复制到newTable中
因为有可能其它线程在历遍这个table,所以不能把原来的链表拆断
public V remove(Object key)
remove操作,如下图,要删除Entry3,则先复制Entry1为Entry1*,Entry1*指向Entry4,再复制Entry2为Entry2*,Entry2*指向Entry1*,最终形成一个两叉的链表。原本的Entry1,Entry2,Entry3会被GC自动回收。

迭代操作:
ConcurrentHashMap的历遍是从后向前历遍的,因为如果有另一个线程B在执行clear操作时,会把table中的所有slot都置为null,这个操作是从前向后执行如果线程A在历遍Map时也是从前向后,则有可能会出现追赶现象。
以下代码:
HashMap<Integer, String> m1 = new HashMap(); m1.put(1, "001"); m1.put(2, "002"); for(Entry<Integer, String> entry : m1.entrySet()){ System.out.println("key:" + entry.getKey()); } HashMap输出的是 key:1 key:2ConcurrentHashMap输出的是key:2 key:1
总结: Java 中的类库实在太多了,HashMap还有很多,有空再补充。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

