Git 客户端在 WebIDE 中的实现
Coding WebIDE 是 Coding.net 自主研发的在线集成开发环境 (IDE)。你可以通过 WebIDE 创建项目的工作空间, 进行在线开发, 调试等操作,有功能健全的 Terminal。由于 Git 使用门槛偏高, WebIDE 提供了便利的 GUI 界面,在此前,WebIDE 实现了基本的 Git 客户端特性。本次更新,增加了 merge,stash,rebase,reset, tags 几个高级特性,使得开发者使用 WebIDE 的效率大大提升!以下为 Coding.net 工程师在实现 WebIDE 中 Git 功能的心得分享。
版本控制
管理文档、程序、配置等文件内容变化的的系统。
其实版本控制很想 并不难理解,其实即使不是编程人员对他也不会陌生,比如 windows 的系统还原,mac 的 timemachine。他们在某一时刻,记录下系统的状态或文件的内容,然后在需要的时候可以恢复。
对于程序员来说,他有以下好处:
-
恢复:当不小心删除了文件、或者改错了文件,可以恢复文件内容
-
回滚:新版本出现了重大问题,可以回滚到上一正确的状态。
-
协作:不同开发者根据同一个版本进行开发,形成不同版本可以方便的合并在一起。
常见的版本控制系统
常见的版本控制系统有 CVS、SVN、Mercurial、Git 等。
这四个版本控制系统可以根据对网络的要求分成两组,一组是CVS、SVN,一组是 Mercurial、Git。
-
CVS、SVN:使用中央仓库,开发者需要从中央仓库中取出代码
-
Mercurial、Git:使用本地仓库,开发者可以本地开发
第一组要求必须连到公司的网络才能办公,而第二组仓库在本地,意味着不用连接到公司的网络,进一步可以说是离线就可以办公。
像Git、Mercurial这样的分布式的版本控制系统变得越来越流行,正在慢慢取代像CVS、SVN“中央式“的版本控制系统。
为什么选择 Git
是什么原因让 git 从这么多的版本控制系统中脱颖而出呢?
-
本地提交:这意味着无论你是在家里、还是地铁上都可以离线工作了,不需要连到公司的网络。
-
轻量级分支:git 的轻量级分支使得你可以快速的切换项目版本。这种特性在某些场景下特别重要,尤其是当我们正在开发过程中,突然发现一个紧急bug需要修复,我们可以快速切换分支,修复bug。
-
解决冲突方便:正因为有轻量级的分支,git也鼓励我们使用分支进行开发。但是当我们将分支合并到主干时,不可避免的会出现冲突,而 git 解决冲突的方式对用户非常的友好
-
有 Github、Coding 这样强大的代码托管平台支持:在 Github 和 Coding 上有非常多的开源代码,而且这两个平台上的用户非常的活跃,使用 git,有助于接触更多优秀的项目、优秀的开发者,对我们的成长有非常大的帮助。
Git 原理
例子
一段经典的 git 操作。
touch README.md git add README.md git commit -m "add readme" touch READEME.md 可以代表创建、修改文件操作
git add README.md 表示将对文件的改动添加到暂存区
git commit -m "add readme" 表示将改动提交到仓库
这些我们都已经知道了,那么添加到暂存区、提交到仓库具体是什么意思?
三种状态
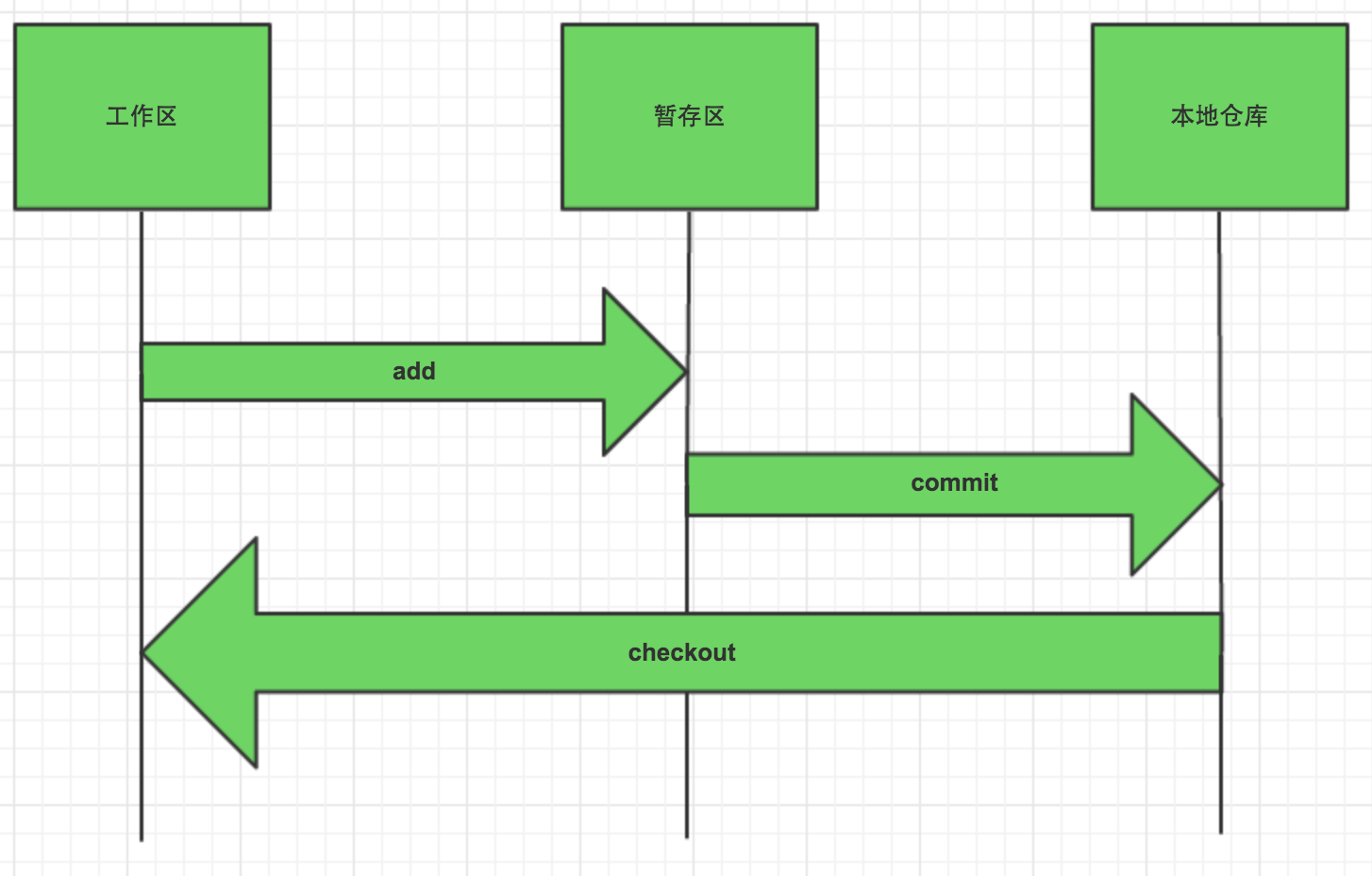
git 有三种状态:工作区、暂存区、本地仓库。
-
add:工作区 -> 暂存区
-
commit:暂存区 -> 本地仓库
工作目录我们是知道的,我们平时编写代码,就是在工作目录中完成的。
暂存区也叫做索引,保存了下次将提交的文件列表。
本地仓库是 Git 用来保存项目的数据的地方。提交代码,意味着将文件内容永久保存到数据库中。
首先看一下本地仓库,项目中的文件在本地仓库中是以快照的形式来保存的。
git 中的快照
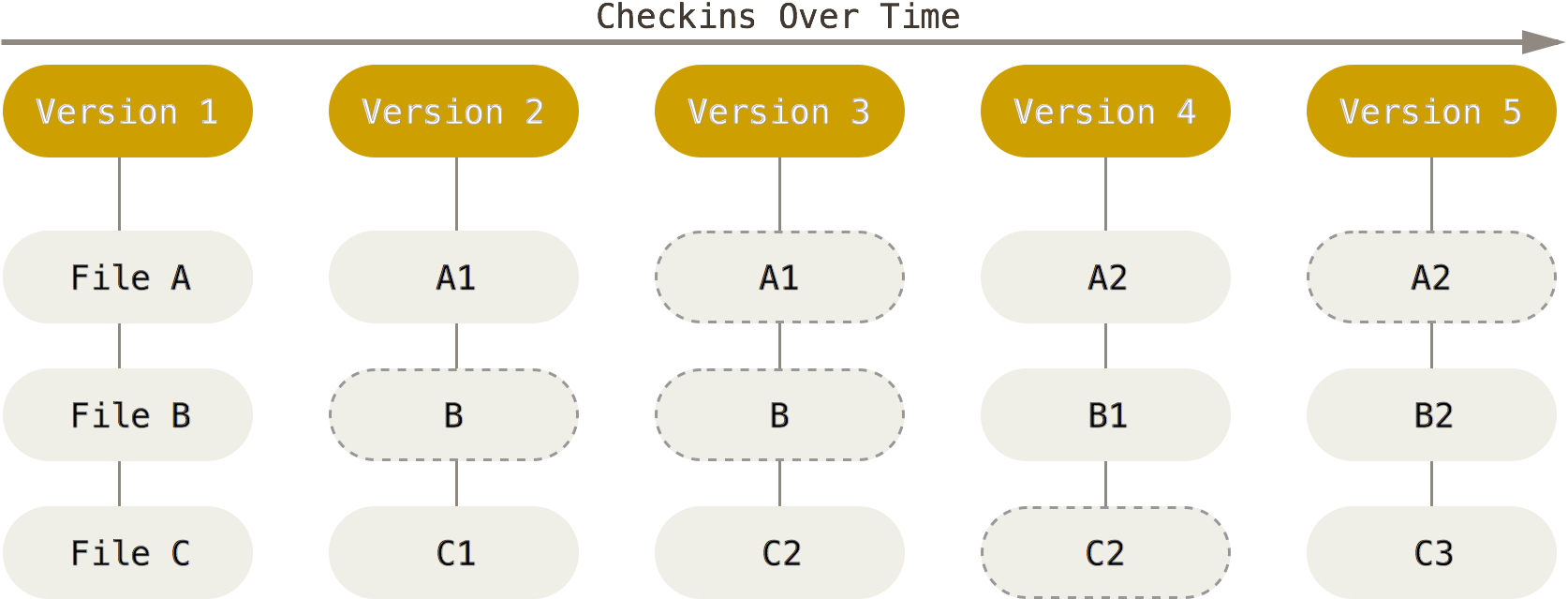
每一个 version,都是项目的一次完整快照。而快照中没有修改的文件,Git 使用链接指向之前存储的文件。
这就带来了一个问题,链接是什么?怎么快速的知道文件内容是否发生了改变?git 中的方案是使用 SHA-1。
SHA-1
echo 'test content' | git hash-object --stdin d670460b4b4aece5915caf5c68d12f560a9fe3e4 特点:
- 由文件内容计算出的hash值
- hash值相同,文件内容相同
- 作为唯一 id
SHA-1将文件中的内容通过算法生成一个 160bit 的报文摘要,即40个十六进制数字。SHA-1的一个重要特征就是几乎可以保证,如果两个文件的SHA-1值是相同的,那么它们确是完全相同的内容。
上面的代码,无论运行几次,得到的 hash 值都是一样的。这个hash值可以看作是该文件的唯一id。
Git 中所有数据在存储前都计算该hash值,然后用该hash值来引用。因此这个 id 除了可以唯一表示任何版本中的文件,还可以表示任何一次提交、任何一次代码的快照。
实际存储在 git 中的数据
find .git/objects -type f
我们来看一下实际存储在git中的数据,看起来比较乱,这些数据存放在 .git/objects,然后使用sha-1计算的hash值的前两位作为文件夹的名字,后面的38位作为文件的名字。
在这么多的文件中,其实可以分为4种类型,分别是 blob、commit、tree 和 tag。
将上面的内容经过按照这些类型整理可以得到类似下面的关系(忽略 tag)。
每一个线框表示了一个object,也就是 objects 目录下的一个文件。
每个 object 上面的这个字母与数字组合的字符串,就是object的上一目录名+文件名,也就是 sha-1 hash 值。
每个 object 的第一行格式是一致的,都由两列组成,第一列表示了 object 的类型,第二列是文件内容的长度。
接下来我们分别看一下每种类型:
blob:用来存放项目文件的内容,项目的任意文件的任意版本都是以 blob 的形式存放的。但是不包括文件的路径、名字、格式等其它描述信息。
tree:用来表示项目中的目录,我们知道,目录中有文件、有子目录。因此 tree 中有 blob、子 tree。这是与目录的对应。tree 中还包含了文件的路径以及名称。从顶层的 tree 纵览整个树状的结构,叶子结点就是blob,表示文件的内容,非叶子结点表示项目的目录,那么 顶层的 tree 对象就代表了当前项目的快照 。
commit:一个commit表示一次提交。里面的 tree 的值指向了项目的快照。还有一些其它的信息,比如 parent,committer、author、message 等信息。
tree 看成一个树状的结构,blob 可以作为其中的叶子结点出现。commit 可以看作是一个DAG,有向无环图。因为 commit 可以有一个 parent,也可以有两个或者多个parent。
至此,本地仓库我们就了解完了。接下来看一下暂存区。
暂存区
暂存区是工作区与本地仓库之间的一个缓冲,它保存了下次将提交的文件列表信息。它其实是一个文件,路径为: .git/index 。由于该文件是一个二进制文件,没办法直接看它的内容,但是可以使用 git 命令查看。
每列的含义依次为,文件权限、文件 blob、文件状态、文件名。
第二列指的是文件的 blob。这个 blob 存放了文件暂存时的内容。
我们操作暂存区的场景是这样的,每当编辑好一个或几个文件后,把它加入到暂存区,然后接着修改其他文件,改好后放入暂存区,循环反复。直到修改完毕,最后使用 commit 命令,将暂存区的内容永久保存到本地仓库。
这个过程其实就是构建项目快照的过程,因此可以说暂存区是用来构建项目快照的区域。
分支
接下来看一下分支的概念,首先看一张图:
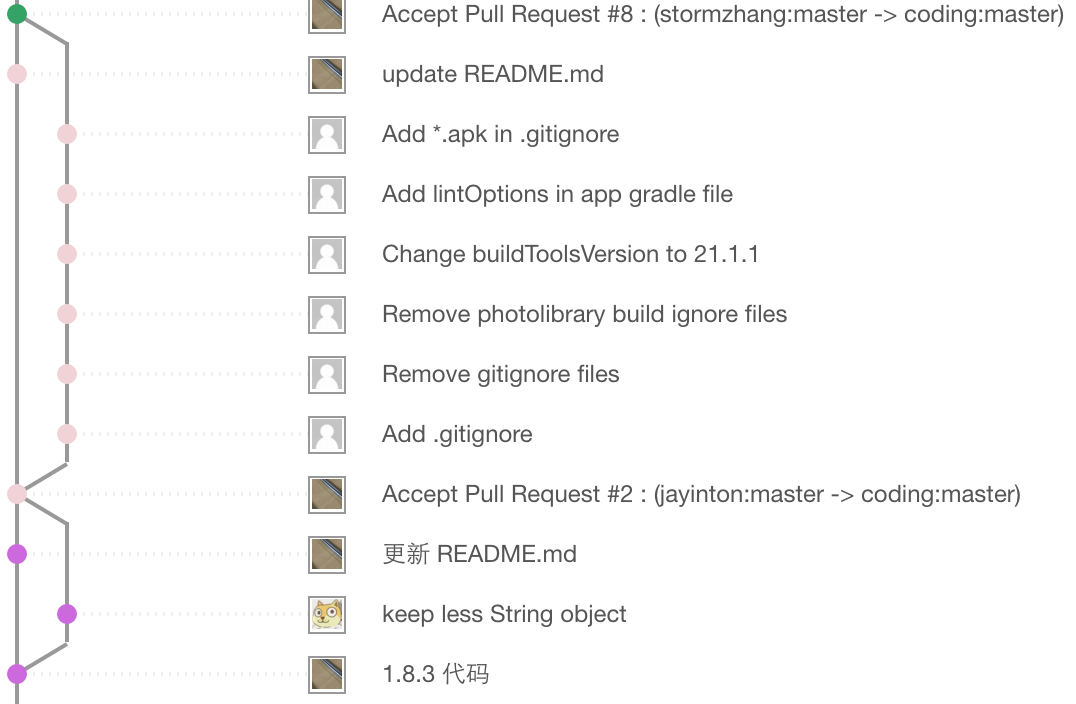
这张图中的每一个点表示了一个commit。从这张图中我们可以看出的信息有:
-
从任意一点分歧出来的线都可以叫做分支
-
分支可以合并
分支的实现
在 .git/HEAD 文件中,保存了当前的分支。
cat .git/HEAD =>ref: refs/heads/master 其实这个 ref 表示的就是一个分支,它也是一个文件,我们可以继续看一下这个文件的内容:
cat .git/refs/heads/master => 2b388d2c1c20998b6233ff47596b0c87ed3ed8f8 可以看到分支存储了一个 object,我们可以使用 cat-file 命令继续查看该 object 的内容。
git cat-file -p 2b388d2c1c20998b6233ff47596b0c87ed3ed8f8 => tree 15f880be0567a8844291459f90e9d0004743c8d9 => parent 3d885a272478d0080f6d22018480b2e83ec2c591 => author Hehe Tan <xiayule148@gmail.com> 1460971725 +0800 => committer Hehe Tan <xiayule148@gmail.com> 1460971725 +0800 => => add branch paramter for rebase 从上面的内容,我们知道了分支指向了一次提交。为什么分支指向一个提交的原因,其实也是git中的分支为什么这么轻量的答案。
因为分支就是指向了一个 commit 的指针,当我们提交新的commit,这个分支的指向只需要跟着更新就可以了,而创建分支仅仅是创建一个指针。
至此git的原理就讲完了,接下来看一下 JGit。
JGit
JGit 是一个用 Java 实现的比较健全的 git 实现,Eclipse IDE 中的 git 插件 Egit,就是基于 JGit 开发的。同 git 一样,它提供了底层命令和高层命令。
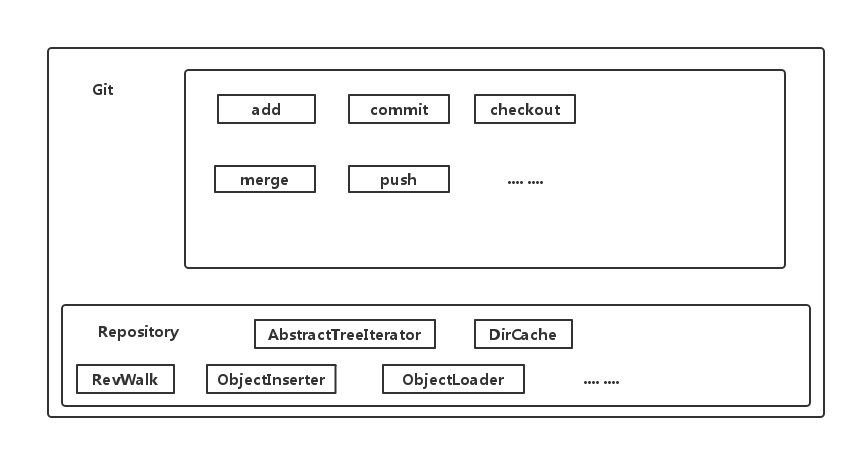
高层命令的入口是 Git 类。高层命令好理解,我们使用 git 的客户端绝大多数命令都是高层命令。
比如 add、commit、checkout 等都是高层命令,他们提供了友好的交互,往往一条命令就能完成你所想要的效果。
底层命令的入口是 Repository 类。底层命令不同于高层命令,它们直接作用域 仓库(Repository)。比如 AbstractTreeIterator,就是用来遍历 Tree 结构的,DirCache 是用来操作暂存区的,RevWalk 是用来遍历 commit 的,ObjectInsert 是用来生成 obj的,ObjectLoader 是用来加载 object。
一条高层命令往往是由多条底层命令组成的。
Repository(仓库)
作为一切的开始,你需要一个 Repository。
Repository repository = new FileRepositoryBuilder() .setGitDir(new File("/home/tan/GitTest/.git")) .readEnvironment() .build(); 使用时只需要将仓库的路径传进来就可以了,它会自动读取一些必要的环境变量。
ObjectInserter
ObjectInserter用来将数据插入到git数据库中,也就是 objects 目录下。插入的类型为我们刚才提到的四种,分别是 Blob、Tree、Commit、Tag。
try (ObjectInserter inserter = repo.newObjectInserter()) { ObjectId objectId = inserter.insert(Constants.OBJ_BLOB, new String("test").getBytes()); inserter.flush(); } 第二个参数表示要插入的数据,该数据会自动使用 zlib 压缩。
TreeWalk
用来遍历目录结构,可以为工作区、暂存区或项目快照(版本库)。
try (TreeWalk treeWalk = new TreeWalk(repo)) { treeWalk.setRecursive(true); treeWalk.addTree(new FileTreeIterator(repo)); treeWalk.addTree(new DirCacheIterator(repo.readDirCache())); while (treeWalk.next()) { AbstractTreeIterator treeIterator = treeWalk.getTree(0, AbstractTreeIterator.class); DirCacheIterator dirCacheIterator = treeWalk.getTree(1, DirCacheIterator.class); } } TreeWalk 是用来遍历树这种结构的,它比较厉害的一点是可以同时遍历多棵树,遍历多课树的思路为将文件列表做一个合并,然后遍历这个列表,没有的调用 getTree 会返回 null 值。
其实 git status 就是这种原理来做的:
- changed: 在版本库、idnex 中都存在,内容不同
- removed: 在版本库存在,在 index 不存在
- added:在 index 存在,在版本库不存在
- untracked:不在版本库和 index,只在工作目录中存在
- modified:在 index,在工作区,且文件内容不同
- missing:在 index 存在,在工作区不存在
RevWalk
RevWalk 用来遍历 Commit。
try (RevWalk revWalk = new RevWalk(repository)) { revWalk.markStart(one); revWalk.markStart(two); revWalk.setRevFilter(RevFilter.MERGE_BASE); RevCommit base = revWalk.next(); } 我们这个例子,标记了两个 commit,我们设置的 filter 是 MERGE_BASE, 它会自动查找这两个 commit 所在分支的 MERGE_BASE。其中 MERGE_BASE 可以看作是分支的分岔点,合并的时候 MERGE_BASE 会作为参照。
使用底层命令
高层命令其实是由多条底层命令组成的,比如我们最常使用的 add、commit:
-
add
- 使用 ObjectInserter 将文件内容写入 objects (blob),得到 blob id
- 使用 DirCache 将 blob id 写入暂存区
-
commit
- 使用 DirCache 将 index 生成 tree
- 使用 ObjectInserter 将 tree 写入仓库(tree),得到 tree 的 id
- 构建 commit,写入 tree id 以及设置其 parent、message 等其它信息
- 利用 ObjectInserter 将 commit 写入 objects (commit),得到 commit id
- 将 commit id 写入当前的 branch,使得 branch 指向最新的 commit
高层命令
上面的复杂操作,可以简单的用底层命令替代。
git.add().addFilepattern("README").call(); git.commit().setMessage("add readme").call(); 高级操作的局限
高层命令使用起来方便,但是它所提供的功能有限。这里我们拿 merge 举例。
使用 JGit Merge api
使用 JGit 提供的接口进行 merge 十分的方便,只需要指定要合并的 branch 就可以了。
MergeCommand merge = git.merge(); merge.include(branch); MergeResult result = merge.call(); 但是 merge 之后呢,文件冲突了怎么办,怎么解决冲突呢?实际上除了 merge,stash、rebase 等等操作也都会产生冲突。也就是说 git 冲突文件的处理是客户端的重要功能之一。
遗憾的是 jgit 并没有提供解决冲突的方案,所以这就需要我们自己来解决这个问题。
resolve conflicts:
一种比较理想的解决冲突的方案是,将冲突的文件根据本地修改、基础版本、要合并分支的修改分成三栏。
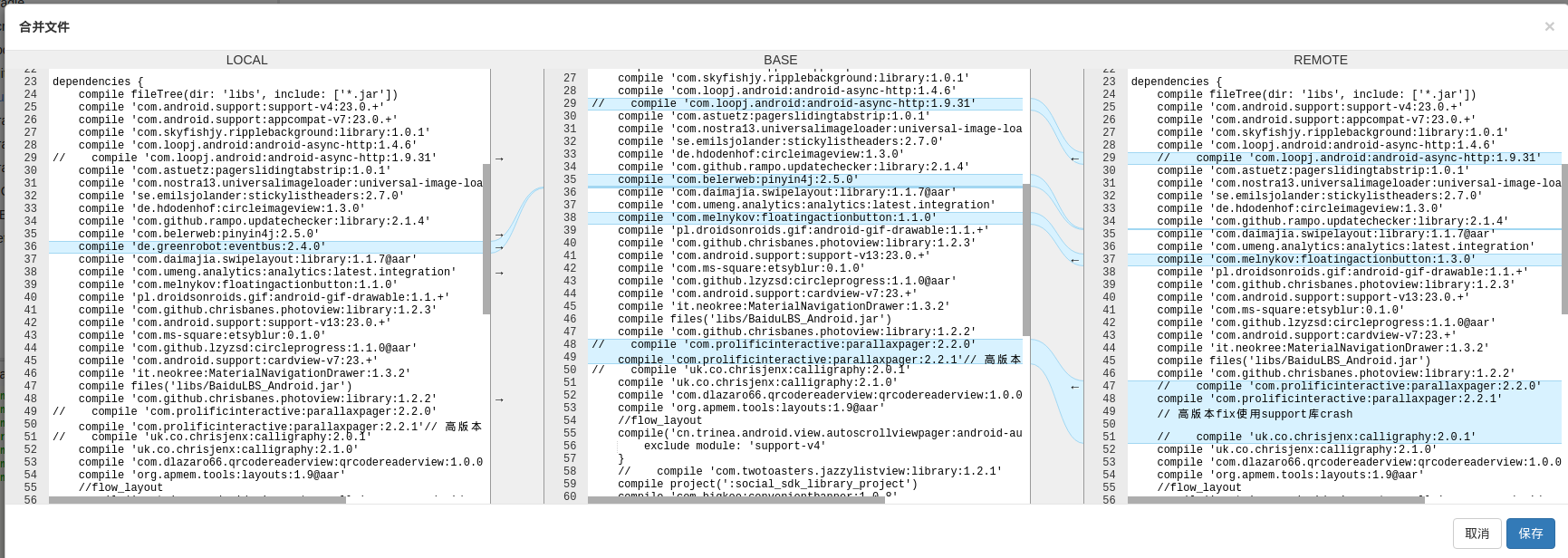
通过这样的方式,我们可以直观的对照冲突的内容,并且可以方便的选取或者要抛弃修改。
可选方案
-
计算 merge base
第一个就是计算这两个分支的 MERGE_BASE。这样我们获得了三个 commit,每个 commit 都都纪录了提交时的文件快照。而我们只要将冲突文件的内容从快照中取出来就好了。但是这个方案有个缺点,那就是我们只有在合并的那一瞬间才能知道要合并的分支,之后想要知道只能去 .git 下面的 MERGE_HEAD 去查,而且其它方式比如 stash、rebase 等操作引起的冲突是不会生成该文件的。
-
使用暂存区的信息
想想我们 当我们有合并冲突状态时,使用 git status,会列出冲突文件,以及冲突的类型,比如 “双方修改”、“由我们删除”,“双方添加”等这样的字眼,git 如果获得这些信息的呢?
如果存在冲突文件,我们查看暂存区,可以看到类似下面的内容:
git ls-files --stage 100644 6e9f0da13f19b444ec3a9c3d6e795ad35c0554a2 1 Readme 100644 29d460866c44ad72cc08ef4983fc6ebd48053bab 2 Readme 100644 12892f544e81ef2170034392f63c7fc5e6c6ccd9 3 Readme原来暂存区中有四种状态用于标示文件:
* 0: standard stage
* 1: base tree revision
* 2: first tree revision (usually called "ours")
* 3: second tree revision (usually called "theirs")
接下来我们专门看一下这4种状态是如何表示冲突状态的。
文件冲突的状态:
假设当前我们处于 master 分支,要合并的分支为 test,开发历史如下图:
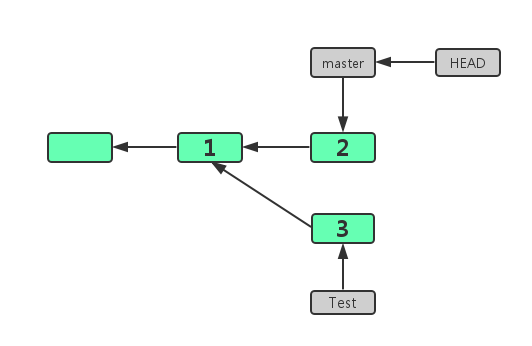
现在假设合并过程中有个文件(Readme)发生了冲突,我们查询暂存区该文件的状态(可以有多个):
- 1 and 2: DELETED_BY_THEM;
- 1 and 3: DELETED_BY_US;
- 2 and 3: BOTH_ADDED;
- 1 and 2 and 3 : BOTH_MODIFIED
我们拿第一种情况举例,文件(Readme)有两种状态 1 和 2,1 表示该文件存在于 commit 1(也就是MERGE_BASE),2 表示该文件在 commit 2 (master 分支)中被修改了,没有状态 3,也就是该文件在 commit 3(test分支)被删除了,总结来说这种状态就是 DELETED_BY_THEM。
可以再看一下第四种情况,文件(Readme)有三种状态 1、2、3,1 表示 commit 1(MERGE_BASE)中存在,2 表示 commit 2(master 分支)进行了修改,3 表示(test 分支)也就行了修改,总结来说就是 BOTH_MODIFIED(双方修改)。
获取冲突文件的三个版本
知道了冲突文件的状态,就能在暂存区获得冲突文件的三个版本了。代码如下:
DirCache dirCache = repository.readDirCache(); // 在暂存区中,所有文件是按照字母顺序排列的,因此文件的不同状态是连着的 int eIdx = dirCache.findEntry(path); // nextEntry 会自动调过文件名相同的文件,找到下一个文件。 int lastIdx = dirCache.nextEntry(eIdx); // 在 [eIdx, lastIdx) 区间的也就是文件的冲突的不同版本 for (int i=0; i<lastIdx - eIdx; i++) { DirCacheEntry entry = dirCache.getEntry(eIdx + i); // 如果是 MERGE_BASE if (entry.getStage() == DirCacheEntry.STAGE_1) readBlobContent(entry.getObjectId()); // 如果是 当前分支 else if (entry.getStage() == DirCacheEntry.STAGE_2) readBlobContent(entry.getObjectId()); // 如果是 要合并的分支 else if (entry.getStage() == DirCacheEntry.STAGE_3) readBlobContent(entry.getObjectId()); } 至此我们得到了解决合并冲突的一个方案。
Happy Coding;)
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

