微博情绪分析器开发过程

很早以前我就对诸如人工智能,语义分析,大数据处理等等东西很感兴趣,无奈高等数学渣的天怒人怨,基本算法也烂的人神共愤,所以一直只是做一些不那么底层的东西,虽然也可以有趣,但趣味总是不那么深入。最近在SAE后台看到了分词服务,于是想到能不能借助它做一个情绪分析的工具,经过一番摸索,终于做出了一个小工具,顺便把它延伸到了微博平台,最后实现的功能是,用户通过微博登录,然后程序抓取所有发过和转发的微博,并挨个分析其中关键信息的情绪度,再根据不同权重计算出最后的情绪度,也可以叫做幸福感,我把这个工具称作『 微博幸福感分析器 』,下面是我的开发过程。
1.分词与情绪数据库
最重要的两样东西是分词和情绪词汇数据库,所幸这两样都有现成的。分词我使用的是新浪提供的分词接口。这个接口可以把你提供的文本按词性分成不同的词语,给出每个词语的词性,比如『我今天吃饭了』,分词接口会把这句话分成『我』『今天』『吃饭』『了』,这有助于我们进一步分析每个词的情感。
分词问题是很有难度的一项技术,新浪帮我解决了,剩下还要准备的一项是情绪数据库,经过寻觅,我最终发现大连理工『情感词汇本体库』最靠谱,这是大连理工大学信息检索研究室(DUTIR)的研究成果,这个本体库标注了超过两万词语,包括这些词语词性种类、情感类别、情感强度及极性等信息。
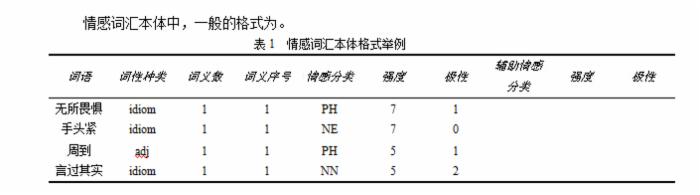
这个词库非常全面,可是我并不需要这么多,而且它是一个电子表格,我要把它迁移到数据库里面去。
2.应用数据库
这里面面临的问题是,我应该把它放在mysql数据库里面吗?放在mysql里面理论是可以的,2万多的数据量也很小,但问题在于,分析每一个词语,都会遍历这2W的数据库,看是否有相同的,一个文本如果有五百词汇,那么就需要查询数据库500 × 2W= 1000W次,这还只是一个文本的处理,如果有个十几个几十个的并发,那数据库的压力就简直不忍直视了。
于是我想到能否用更简单的方式来处理这2W经常要用到的数据,解决方案有两个,一个是Memcache,一个是SAE开发的用来支持公有云计算平台上的海量key-value存储的分布式key-value数据存储服务KVDB,通过描述的字数你就应该可以知道我最后用了什么,这2W多的数据需要的是持久化的存储,所以Memcache并不是特别合适,用KVDB的另一个原因在于我比较喜欢这个名字,因为它里面有D和K。
KVDB的使用非常的简单:
<?php $kv = new SaeKV(); // 初始化KVClient对象 $ret = $kv->init(); var_dump($ret); // 更新key-value $ret = $kv->set('abc', 'aaaaaa'); var_dump($ret);
// 添加key-value $ret = $kv->add('abc', 'aaaaaa'); var_dump($ret);
// 获得key-value $ret = $kv->get('abc'); var_dump($ret); // 删除key-value $ret = $kv->delete('abc'); var_dump($ret); // 一次获取多个key-values $keys = array(); array_push($keys, 'abc1'); array_push($keys, 'abc2'); array_push($keys, 'abc3'); $ret = $kv->mget($keys); var_dump($ret); ?>
这就几乎是全部操作需要的了,KVDB的读写可以达到10W qps,而且价格比mysql和Memcache都便宜不少,虽然我是SAE高级开发者,已经不担心价格这个问题了,但是还是能省一点是一点吧,这也是优化啊。
把电子表格导入mysql,再写一个PHP把mysql里面的数据迁移到KVDB,情绪数据库这部分工作就完成了。这部分的PHP代码是
$kv = new SaeKV();//初始化KVDB$ret = $kv->init();
$mysql = new SaeMysql();
$sql = “SELECT * FROM `mood`”;
$data = $mysql->getData( $sql );//从数据库里面读数据
foreach ($data as $word) {
if($word[‘goodbad’]==’2′)//判断词语情绪
{
$s = 0 – $word[‘intensity’];
}
elseif($word[‘goodbad’]==’1′)
{
$s = 0 + $word[‘intensity’];
}
else
{
$s = 0;
}
$ret = $kv->add($word[‘name’],$s);//写入KVDB
var_dump($ret);
}$mysql->closeDb();
我把情绪数据库弄的很简单,KVDB的key对应着词语本身,value对应着-9到9的一个数字,数字为负数则代表负面情绪,数字为正数代表这正面情绪,数字越大情绪越强烈,这些情绪有:

3.文本处理
获取一段文本,通过分词把这段文本的名词,动词,形容词提取出来,因为助词连词什么的是没有感情的。然后挨个在情绪词库里面搜寻是否有对应的,如果有,获取这个词语的情绪都度,如果没有,则记为0。然后把取出来的数值全部相加,再除以分析过的所有词汇的数量,最终的值,我把它称之为正能量度。
第一个小工具是分析一个网页的正能量度的,我写的小工具在: http://coolirand.com/getwebmood.php ,它可以抓取指定的网页内容,然后分析网页里面的所有词汇,并按照上述方法计算出一个数值。比如我分析自己的博客,《不创业的原因》这篇文章的正能量度比《媒体与极权》这篇文章高很多,然而它却比《厉害和不厉害的故事》低。
网页有很多特殊字符,也有数字和字母,但是它们都是无用的,我们只需要中文,因此我写了一个函数,把一个字符串中的所有非中文字符都剔除,有需要的可以看看这个函数:
function unhtml($string){
preg_match_all(‘/[/x{4e00}-/x{9fff}]+/u’, $string, $matches);
$string = join(”, $matches[0]);
return addslashes(strip_tags(trim($string))); //删除文本中首尾的空格
}
值得注意的是,新浪提供的分词服务最大只支持10kb的文本,因此我还做了分段查询,先判断一个文本是否大于10kb,如果是,则分成多段,先拿每段去查询,再把结果合在一起。
4.微博查询
做完上一个小工具之后我玩了很久,但是觉得还不够有趣,我更想知道每个人的情绪而非网页的,因此我想到了与微博结合,分析某个人发过和转发过的每一条微博,通过微博里面的每个词语的情绪来分析这个人的正能量度,也可以叫做幸福度,因为一个人的情绪越好,他应该就越幸福。
不会写爬虫,那就直接用微博的接口吧,微博的接口提供了读取函数,可以光明正大的读取用户的每一条微博,我把这些微博连成一个字符串,用上面提到的函数去掉特殊字符和数字字母,然后来分析,并且根据这个人的粉丝数量,恋爱状态等资料建立模型,再在这个模型的基础上进行数字的权重计算,最后又会得出一个数字,我把它称之为幸福感数值。
我还把用户和幸福感数值存储起来了,用来建立一个排行榜,榜上展示幸福感最高的前十位。忧伤的是,我除了测试的时候,那时候不到十个人用,我在榜上,之后就从来没上过榜了。。。。
我把这个微博上的小工具称之为『 微博幸福感分析器 』,它还有不少bug和不完善的地方,比如『那些幸福,高兴,开心都远去了,与我再无关系』,会理解成幸福度很高的一个句子,因为这种很绕的句子判断很麻烦啊,在此我也倡导大家不要卖关子绕句子,大家都直话直说嘛。
5.接下来
我也想过开源,可是我的代码真心不好意思拿出来见人,所以这个可能得以后再说了,如果有兴趣的朋友一起搞,我觉得可以做一个语言处理的接口,当然这里面还有很多难度,我也就这么一想。
6.最后
感谢新浪分词,感谢大连理工大学信息检索研究室。一般感谢都是很牛逼的人才会去感谢,我觉得虽然我不牛逼,但是我还是可以感谢,因为这些工具和资料真的对我有帮助。就这样。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

