谷歌开源最精确自然语言解析器SyntaxNet的深度解读
自然语言理解研究中,如何处理语言歧义是个难题。 SyntaxNet 将神经网络和搜索技术结合起来,在解决歧义问题上取得显著进展:SyntaxNet 能像训练有素的语言学家一样分析简单句法。今天,谷歌开源了SyntaxNet,也发布了针对英语的预训练解析程序 Parsey McParseface。除了让更多人使用到最先进的分析技术之外,这次开源举措也有利于公司借助社区力量加快解决自然语言理解难题的步伐,惠及谷歌业务。
如果你对 Siri 说,设置闹钟:早上五点,她可以办到。但是,如果问她哪种处方止疼片对胃部刺激最小,她就束手无策了,因为你说的句子很复杂。Siri 还远未实现计算机科学家所说的「自然语言理解」。
这并不是说虚拟助理将永远这样。
科技巨头、创业公司、大学的研究人员正在想办法让计算机理解自然语言。多亏深度神经网络,这方面的技术正变得越来越好。谷歌、脸书和微软以及其他公司,已经使用深度神经网络来识别图片中的物体,也用于识别人们对虚拟助手说的单个单词。
人们希望这类人工智能可以显著提升机器理解语词意义的能力,让机器懂得语、词是如何互动、构成有意义的句子。
「我们大部分用户都通过语言与我们交流,」谷歌公司自然语言理解和机器学习方面的负责人 Fernando Pereira 说,「他们询问查询——键入或口语输入。所以,为了很好地服务用户,我们不得不让我们的系统理解用户想要什么。」
今天,谷歌开源了软件 SyntaxNet(句法分析程序)以及针对英语的解析程序 Parsey McParseface,我们从中看到了自然语言理解快速发展的希望。
SyntaxNet 和 Parsey McParseface
SyntaxNet(句法分析程序)是谷歌自然语言研究的基础。它使用深度神经网络,对句子进行语义分析,试图搞清楚每个语词在句子中扮演的角色,以及这些单词如何组合起来生成意义。系统可以识别潜在的语法结构——哪个单词是名词,哪个是动词,哪个是主语,主宾关系如何——然后试着了解句子的大致意思,不过,是以机器可读的方式。
因为使用了深度神经网络,SyntaxNet 将句法分析推向了一个新的高度。这款系统分析了数以百万条句子,不过,这些句子并不是一般的句子,而是经过人工精心标记过的句子(他们浏览所有作为实例的句子,然后认真标记句中每个单词的角色)。学习完所有这些标记好的句子后,系统就可以分析判断对其他句子中类似语词角色。
这和 Facebook 的方法不同。后者试图通过为计算机提供很大程度上未标记的大量数据来训练这些计算机解析语言(参见 Teaching Machines to Understand Us),而不是象谷歌这样围绕着人类专家打造。
SyntaxNet 使用了谷歌之前发布的深度学习框架 TensorFlow ,它也是到目前为止使用 TensorFlow 开发的最复杂和最先进的组件。
不过,SyntaxNet 是工程师和人工智能研究者的工具。
谷歌还发布了一个预训练的、针对英语的解析程序 Parsey McParseface(一位发言人说该公司正为想名字发愁时,有人建议了这个朗朗上口的绰号)。送入这个解析程序的文本会自动被分解成句法成分(如名词、动词、主语和宾语)。因此,计算机更容易地对模糊的请求或命令做出正确语义分析。
94% 的准确性
简单地说,基本上就是个五岁的孩子,在学习语言的细微差别
谷歌研究人员随机抽取英文新闻专线的句子(来源 Penn Treebank)作为一个标准的基准, Parsey McParseface 重新获取句子语词之间的依存关系 ,正确率达94%。这个成绩不仅好于公司之前的最好成绩,也击败了之前任何研究方法。尽管还没有这方面人类表现如何的研究文献,但是,从公司内部的注释项目那里,研究人员得知,受过这方面训练的语言学家分析准确率为96-97%。这意味着,我们正在接近人类表现——不过,仅仅是在编辑完好的文本方面。
那么, SyntaxNet 与 SpaCy 和 CoreNLP 相比,难分伯仲吗?
对此,谷歌 NLP 研究的产品经理 Dave Orr 回答是:
这取决于你所谓的比,是什么意思。但是,比数字的话,SyntaxNet(据我所知,尤其是英语模型 Parsey McParseface)是已经公布的分析器中最好的。假设所有这些分析程序都接近之前的最好水平(我认为,它们是处于这个水平),SyntaxNet 至少也比其他竞争对手好那么一点。
与其他系统相比,SyntaxNet 只做一件事(依存分析,包括词性标注,所以你可以说是两件事)。SpaCy 也叫做命名实体识别(named entity recognition);斯坦福的系统会做包括 NER、情感分析在内的所有事情。
如果你想要的是分析器,SyntaxNet 是最好的。如果你要求更多,你可能需要并用其他系统,或者直接使用其他系统。
另一个不同是, SyntaxNet 基于谷歌的开源软件 TesnorFlow。如果你对在神经网络结构上建造 NLP 系统感兴趣,使用它就很棒。
SpaCy 和 CoreNLP 都是英语 NLP 开发人员经常使用到的软件。
SpaCy 是一个 Python 和 CPython 的 NLP 自然语言文本处理库。这是一个 MIT 许可协议下的开源商业软件。
据其在 Github 上的介绍,SpaCy 有以下几个特征:
标记依存句法分析( OntoNotes 5 上 91.8% 的准确率)
命名实体识别(OntoNotes 5 上 82.6% 的准确率)
词性标注(OntoNotes 5 上 97.1% 的准确率)
使用词矢量方便
所有字符串映射到整数 ID 上
包括容易使用的拼写特征
不需要前期处理。Spacy 使用原文本材料
另外,SpaCy 有两项顶级性能:速度最快:<50ms 每文档;SpaCy 在全部任务性能(句法分析、命名实体识别、词性标注)上的准确率与最顶尖的水平相比,误差不到 1%,但 Spacy 的速度要快的多。
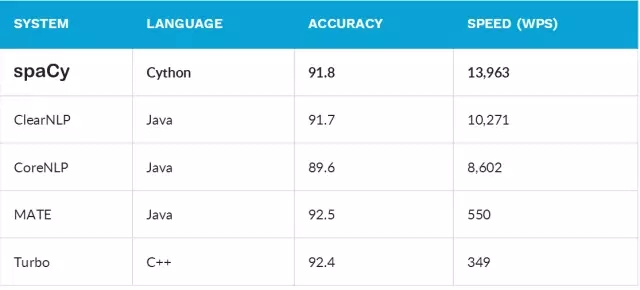
SpaCy 官网介绍:2015 年两篇同行评议的论文确认 ,spaCy 提供的是世界上最快的句法分析,与世界上准确率最高的系统之间的误差在 1% 以内。但少数几个比 SpaCy 精确的系统的速度要慢 20 倍或者更多。
斯坦福 CoreNLP 是一个混合的语言处理框架,它集成了所有的自然语言处理工具,包括词性的终端(POS)标注器,命名实体识别(NER),分析器,对指代消解系统,以及情感分析工具,并提供英语分析的模型文件。
它提供的内容包括:
一个包含多种语法分析工具的综合工具包
对任意文本的快速、可靠分析
全面高水平的文本分析
支持多种主要的人类语言
适用于多种主要的编程语言
可作为简单的网页服务运行
系统原理
SyntaxNet 是句法分析框架,也是自然语言理解系统第一个关键组成部分。给定一个句子,这个系统就能给句子中的每个语词贴上词类标签,亦即描述相应语词的句法功能(比如,主谓宾),还能判定给定句子中,语词之间的句法关系,并用依存关系分析树(dependency parse tree)来表示。这些句法关系与句子的潜在含义有着直接联系。
简单的关系树例子如下:爱丽丝看见鲍勃
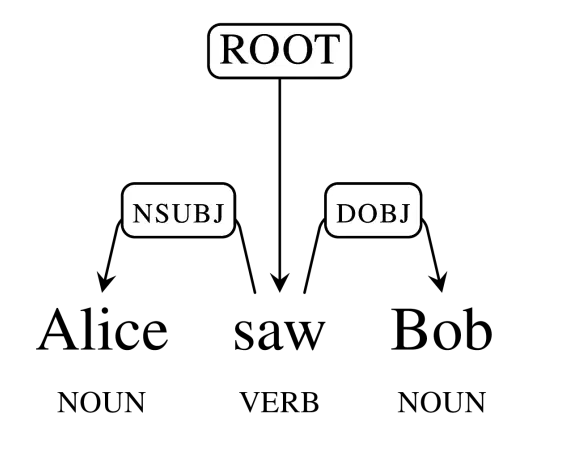
对这个句子的分析:「爱丽丝」和「鲍勃」是名词,「看见」是动词。主动词是「看见」,也是句子的谓语,「爱丽丝」是看见的主语,而「鲍勃」是看见的宾语。正如研究人员所预期的, Parsey McParseface 正确分析了句子的句法结构。不过,它能分析更加复杂的句子。
分析:「爱丽丝」和「鲍勃」分别是「看见」的主语和宾语,除此之外,有一个带有动词「reading」的关系从句修饰「爱丽丝」,「看见」被表示时间的修饰成分「yesterday」修饰,等等。理解了依存结构中的语法关系,就能简单回答各种问题:比如,爱丽丝看见了谁?谁看到了鲍勃?爱丽丝一直在看什么书?或者,爱丽丝看见鲍勃,是什么时候?
神经网络+搜索解决语言歧义难题
人类可以使用常识消除句子中的歧义,谷歌系统则使用了神经网络。
人类语言具有相当的歧义性。
一个简单如「Find me cats in hats(帮我找到帽子里的猫)」的搜索查询,既可能会被解读成「寻找戴着帽子的猫」,也可能会被解读成「寻找坐在帽子里的猫」。一个中等长度的句子——大概 20 到 30 个单词——会有数以百计甚至成千上万种可能的语义结构。
自然语言的语义分析必须在某种程度上搜索所有可能的语义结构,根据给定文本,找到最合乎逻辑的结构。
举个简单例子,爱丽丝开车行驶在大街上(Alice drove down the street in her car),至少有两种可能的依存分析:
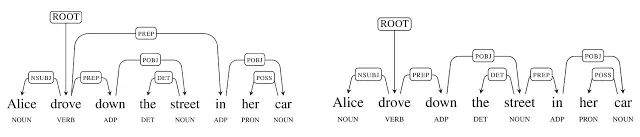
第一个分析是正确的分析:爱丽丝正开着她的车;第二个分析显然很荒唐:街道位于她的车里。这里存在歧义问题,因为,介词「 in 」可能修饰「驾驶(drove)」,也可能修饰的是「街道(street)」。这个例子就是所谓的介词短语的歧义性。
在处理语言高度歧义问题上,人类就擅长多了,甚至都感觉不到有困难,因为靠常识就可以解决这个问题。计算机的一大挑战就是像人类这样处理模糊句子。比如,在更长句子中会有多重歧义,组合爆炸产生多种句子结构。这些结构的绝大部分都是极其不合乎逻辑的,必须通过语义分析进行某种程度上的舍弃。
SyntaxNet 利用神经网络来解决这个难题。
系统会从左到右处理被输入的句子,每处理一个语词,就会逐步添加分析语词之间的依存关系。每处理一处,就意味着诸多可能的选择(因为歧义),此时,神经网络就会根据各竞争性答案的逻辑合理程度进行打分。也正因为如此,在模型中使用定向搜索(beam search)就很重要了。系统不是简单地每处理一处,就采取一级最优的选择,而是每一步都会保存多个局部假设,仅当将其他几个得分更高(higher-ranked)的假设纳入考虑范围后,才会舍弃之前的那些假设。
按照从左到右的决定顺序进行简单的语法分析,例如: I booked a ticket to Google.
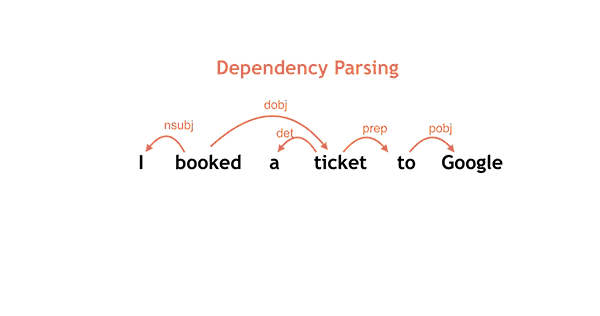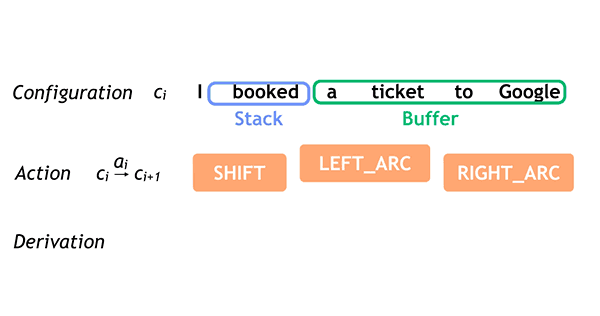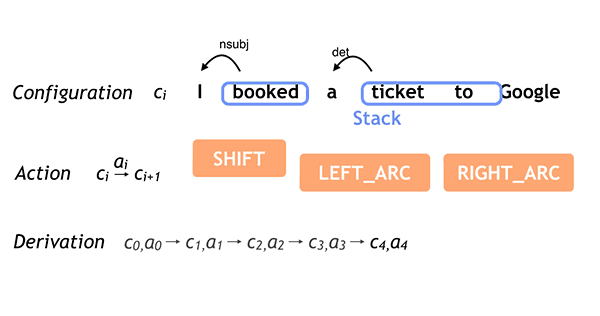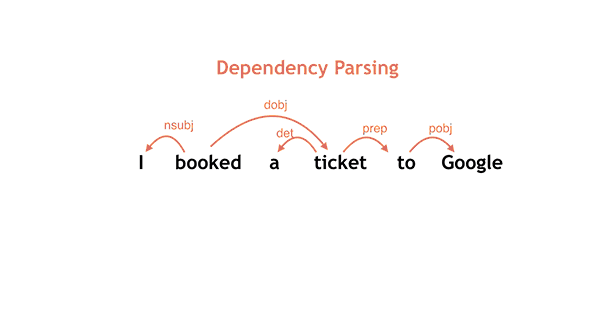
正如之前论文中所描述的,将学习和搜索紧密联系起来,非常重要,这样才能实现高度的预测准确性。
不足
Parsey McParseface 和 SyntaxNet 并不是最终解决方案,谷歌只是将之视为迈向更好的人工智能语义分析的第一步。
即使众多同行认为,SyntanxNet 是众多系统中最好的,但是,该技术还远未完美地掌握英语。Pereira 表示,「我们的系统在结构合理、经过精心编辑的文本上效果最好,但社交媒体和搜索查询的不规则性更有挑战性。我们确实已经取得了进展,但仍还有很大的提升空间。」
从网页上提取的句子更难分析(2011),Parsey McParseface 在这组数据组上的表现不佳,准确率略高于90%。
另外,在自然语言处理中仍然还有很多歧义需要人类水平的常识才能解决——「那些我们从经验中学到的东西,以及来自同龄人和父母的指令。」Pereira 说,「那种非常丰富的解决问题的能力是我们的系统所完全缺失的。」
研究语言理解的斯坦福大学教授 Noah Goodman 说,提高句法理解只是计算机掌握语言的开始。「句法肯定是语言的重要一部分,」他说,「但从句法到语义之间、从浅语义到意义推断之间都还有很大一步。」
另外,来自华盛顿大学计算机科学教授、专门研究自然语言理解的 Noah Smith 表示,语言分析最后的希望在于使用网络上面更广泛的数据训练这样的系统,然而这样做也非常的困难,因为人们在网上使用语言的方式多种多样。
Smith 还指出,在语言使用(非英语)上的研究也远远不够。
未来
虽然不是百分百准确,但是,系统足以应用于诸多应用。
谷歌的研究负责人Fernando Pereira (负责管理公司自然语言理解的研究工作)估计,较之之前的办法,这个工具已使公司产品错误率下降了20-40%,也正在协助谷歌实时服务,包括公司的拳头产品,搜索引擎。
通过共享 SyntaxNet,谷歌想要加快解决难题的步伐,如同当初开源软件引擎 TensorFlow 一样。让每个人都可以使用和修改 SyntaxNet,谷歌就能从更多的人那里获得帮助,解决自然语言理解上的棘手问题。
当然,最终也将惠及谷歌业务。
在数字助理的竞争赛场上,谷歌远非孤军奋战。微软发布了Cortana,亚马逊正在摸索语音助手Echo的成功之道。无数创业公司也加入了这场竞赛,包括最近发布最新demo 的 Viv。脸书的野心更大,他们推出了Facebook M,一个可以通过文本(而不是语音)进行聊天的工具,旨在帮助用户完成各种事务,从约会安排到计划下一次渡假。
尽管有如此多的知名人物从事这方面的研究,但是,数字助理和聊天机器人远不够完美。因为,解决自然语言理解的潜在技术远不够完美。Facebook M 只是部分依赖人工智能,更多地还是依靠人类帮助完成复杂任务,帮助训练人工智能。
Parsey McParseface 和 SyntaxNet 并不是最终解决方案,谷歌也只是将之视为迈向更好的人工智能语义分析工具的第一步。
类似真实人类的数字化助理,远非现实。但是,我们正在一步步靠近。Pereira 说,路漫漫,其修远。但是,我们的确正在打造可以更加准确理解人类的技术。
参考资料:
https://www.technologyreview.com/s/601440/googles-algorithms-decode-language-like-a-trained-linguist/#/set/id/601443/
http://thenextweb.com/dd/2016/05/12/google-just-open-sourced-something-called-parsey-mcparseface-change-ai-forever/
http://www.techinsider.io/googles-newest-software-is-named-parsey-mcparseface-no-seriously-2016-5
http://www.wired.com/2016/05/google-open-sourced-syntaxnet-ai-natural-language/
http://googleresearch.blogspot.jp/2016/05/announcing-syntaxnet-worlds-most.html
http://www.zdnet.com/article/google-open-sources-its-english-language-parser-parsey-mcparseface
https://github.com/tensorflow/models/tree/master/syntaxnet
https://www.quora.com/How-does-Googles-open-source-natural-language-parser-SyntaxNet-compare-with-Spacy-io-or-Stanfords-CoreNLP
https://spacy.io/
https://segmentfault.com/a/1190000000365547
欢迎加入本站公开兴趣群
商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

