性能优化那些事
写在之前的话,最近一年多来几乎没更新博客,更多的原因是自知资历尚潜,要学习的东西太多,要接触的东西也太多,没有足够的精力投入到博客上,或许有一天时机成熟会再提高更新频率吧,但有一点不会变的是,学习的路上数十年如一日,我会一直坚持,争取有更多的机会可以走出来,但前提是我有了足够的深度和广度。
谢谢大家的支持。
——————————————————————————————————————————————————————————-从今年一月份开始,我们团队陆续完成了邮件服务的架构升级。新平台上线运行的过程中也发生了一系列的性能问题,即使很多看起来来微不足道的点也会让整个系统运行得不是那么平稳,今天就将这段时间的问题以及解决方案统一整理下,希望能起到抛砖的作用,让读者在遇到类似问题的时候能多一个解决方案。
新平台上线后第一版架构如下:
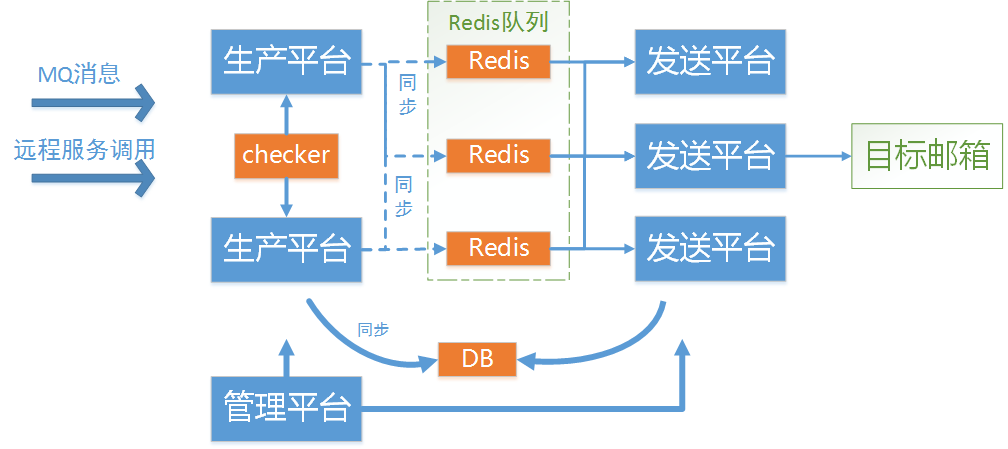
整个平台的数据流程是:
- 数据通过MQ消息和远程服务调用进入新平台;
- 通过生产平台生成邮件发送任务数据,同步Push进Redis队列中;
- 发送平台轮询Redis队列并Pull消息到本地,然后连接邮件服务商服务器进行邮件发送,发送完毕后将结果更新回数据库;
- 有一个全局的Checker扫表,将待发送的邮件任务投递到Redis队列中(包括发送失败,需要重试的任务)。
这版架构上线后,我们遇到的第一个问题:数据库读写压力过大后影响整体服务稳定。
表现为:
- 数据库主库压力高,同时伴有大量的读,写操作。
- 远程服务接口性能不稳定,业务繁忙时数据库的插入操作延迟升高,接口响应变慢,接口监控频繁报警,影响业务方。
经过分析后,我们做了如下优化:
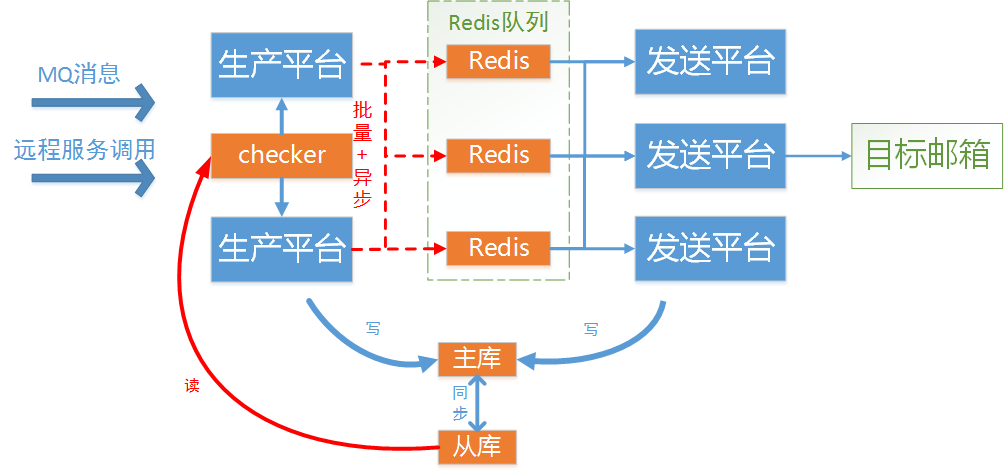
- 数据库做读写分离,将Checker的扫表操作放到从库上去(主从库中的同步延迟不影响我们发送,这次扫描不到的下次扫表到即可,因为每条邮件任务上有版本号控制,所以也不担心会扫描到“旧记录”的问题)。
- 将Push到Redis的操作变成批量+异步的方式,减少接口同步执行逻辑中的操作,主库只做最简单的单条数据的Insert和Update,提高数据库的吞吐量,尽量避免因为大量的读库请求引起数据库的性能波动。
这么做还有一个原因是经过测试,对于Redis的lpush命令来说每次Push1K大小的元素和每次Push20K的元素耗时没有明显增加。
因此,我们使用了EventDrieven模型将Push操作改成了定时+批量+异步的方式往Redis Push邮件任务,这版优化上线后数据库主库CPU利用率基本在5%以下。
总结: 这次优化的经验可以总结为:用异步缩短住业务流程 +用批量提高执行效率+数据库读写分离分散读写压力。
优化后的架构图:
优化上线后,我们又遇到了第二个问题:JVM假死。
表现为:
- 单位时间内JVM Full GC次数明显升高,GC后内存居高不下,每次GC能回收的内存非常有限。
- 接口性能下降,处理延迟升高到几十秒。
- 应用基本不处理业务。
- JVM进程还在,能响应jmap,jstack等命令。
- jstack命令看到绝大多数线程处于block状态。
堆信息大致如下(注意红色标注的点):
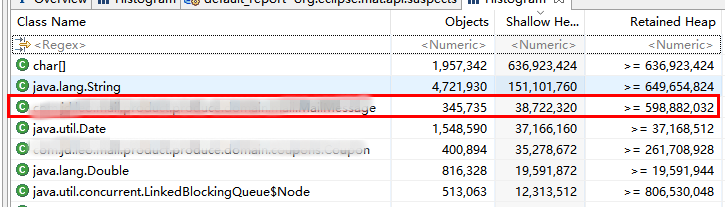
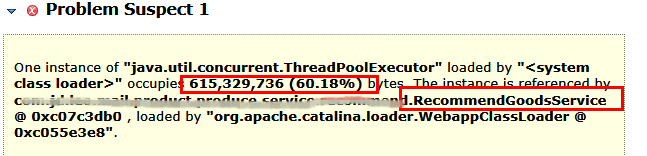
如上两图,可以看到RecommendGoodsService 类占用了60%以上的内存空间,持有了 34W 个 “邮件任务对象”,非常可疑。
分析后发现制造平台在生成“邮件任务对象”后使用了异步队列的方式处理对象中的推荐商品业务,因为某个低级的BUG导致处理队列的线程数只有5个,远低于预期数量, 因此队列长度剧增导致的堆内存不够用,触发JVM的频繁GC,导致整个JVM大量时间停留在”stop the world ” 状态,JVM响应变得非常慢,最终表现为JVM假死,接口处理延迟剧增。
总结:
- 我们要尽量让代码对GC友好,绝大部分时候让GC线程“短,平,快”的运行并减少Full GC的触发机率。
- 我们线上的容器都是多实例部署的,部署前通常也会考虑吞吐量问题,所以JVM直接挂掉一两台并不可怕,对于业务的影响也有限,但JVM的假死则是非常影响系统稳定性的,与其奈活,不如快死!
相信很多团队在使用线程池异步处理的时候都是使用的无界队列存放Runnable任务的,此时一定要非常小心,无界意味着一旦生产线程快于消费线程,队列将快速变长,这会带来两个非常不好的问题:
- 从线程池到无界队列到无界队列中的元素全是强引用,GC无法释放。
- 队列中的元素因为等不到消费线程处理,会在Young GC几次后被移到年老代,年老代的回收则是靠Full GC才能回收,回收成本非常高。
经过一段时间的运行,我们将JVM内存从2G调到了3G,于是我们又遇到了第三个问题:内存变大的烦恼
JVM内存调大后,我们的JVM的GC次数减少了非常多,运行一段时间后加上了很多新功能,为了提高处理效率和减少业务之间的耦合,我们做了很多异步化的处理。更多的异步化意味着更多的线程和队列,如上述经验,很多元素被移到了年老代去,内存越用越小,如果正好在业务量不是特别大时,整个堆会呈现一个“稳步上升”的态势,下一步就是内存阀值的持续报警了。

所以, 无界队列的使用是需要非常小心的。
我们把邮件服务分为生产邮件和促销邮件两部分,代码90%是复用的,但独立部署,独立的数据库,促销邮件上线后,我们又遇到了老问题:数据库主库压力再次CPU100%
在经过生产邮件3个月的运行及优化后,我们对代码做了少许的改动用于支持促销邮件的发送,促销的业务可以概括为:瞬间大量数据写入,Checker每次需要扫描上百万的数据,整个系统需要在大量待发送数据中维持一个较稳定的发送速率。上线后,数据库又再次报出异常:
- 主库的写有大量的死锁异常(原来的生产邮件就有,不过再促销邮件的业务形态中影响更明显)。
- 从库有大量的全表扫描,读压力非常高。
死锁的问题,原因是这样的:
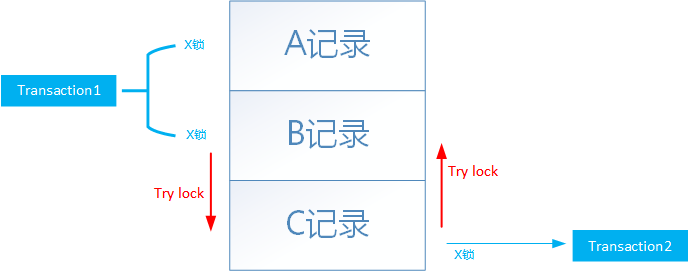
条件1.如果有Transaction1需要对ABC记录加锁,已经对A,B记录加了X锁,此刻在尝试对C记录枷锁。
条件2.如果此前Transaction2已经对C记录加了独占锁,此刻需要对B记录加X锁。
就会产生dead lock。实际情况是:如果两条update语句同一时刻既需要扫描ABC又需要扫描DCB,那么死锁就出现了。
尽管Mysql做了优化,比如增加超时时间:innodb_lock_wait_timeout,超时后会自动释放,释放的结果是Transaction1和Transaction2全部Rollback(死锁问题并没有解决,如果不幸,下次执行还会重现)。再如果每个Transaction都是update数万,数十万的记录(我们的业务就是),那事务的回滚代价就非常高了。
解决办法很多, 比如先select出来再做逐条做update,或者update加上一个limit限制每次的更新次数,同时避免两个Transaction并发执行等等。我们选择了第一种,因为我们的业务对于时间上要求并不高,可以“慢慢做”。
全表扫表的问题发生在Checker上,我们封装了很多操作邮件任务的逻辑在不同的Checker中,比如:过期Checker,重置Checker,Redis Push Checker等等。他们负责将邮件任务更新为业务需要的各种状态,大部分时候他们是并行执行的,会产生很多select请求。严重时,读库压力基本维持在95%上长达数小时。
全表扫描99%的原因是因为select没有使用索引,所以往往开发同学的第一反应是加索引,然后让数据库“死扛”读压力 ,但索引是有成本的,占用硬盘空间不说,insert/delete操作都需要维护索引,
其实我们还有另外好几种方案可以选择,比如:是不是需要这么频繁的执行select? 是不是每次都要select这么多数据?是不是需要同一时间并发执行?
我们的解决办法是: 合理利用索引+降低扫描频率+扫描适量记录。
首先,将Checker里的SQL统一化,每个Checker产生的SQL只有条件不同,使用的字段基本一样,这样可以很好的使用索引。
其次,我们发现发送端的消费能力是整个邮件发送流程的制约点,消费能力决定了某个时间内需要多少邮件发送任务,Checker扫描的量只要刚刚够发送端满负荷发送就可以了,因此,Checker不再每个几分钟扫表一次,只在队列长度低于某个下限值时才扫描,
并且一次扫描到队列的上限值,多一个都不扫。
经过以上优化后,促销的库也没有再报警了。
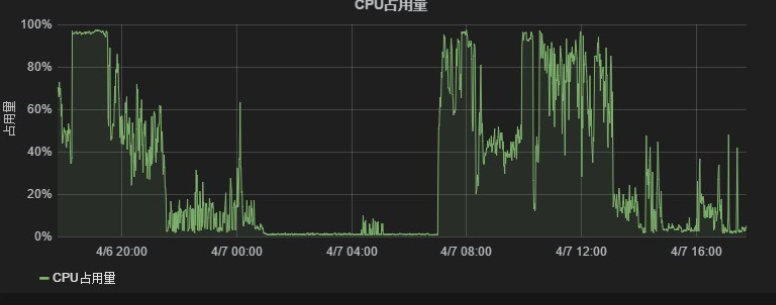
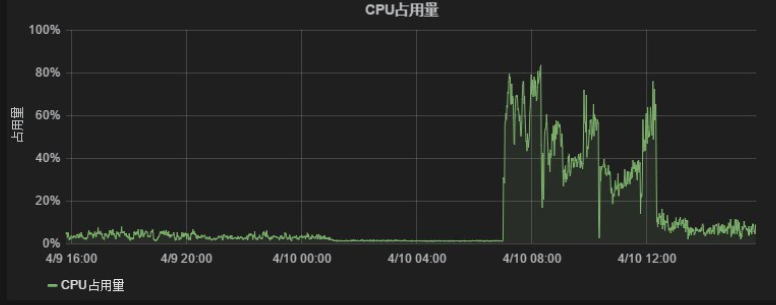
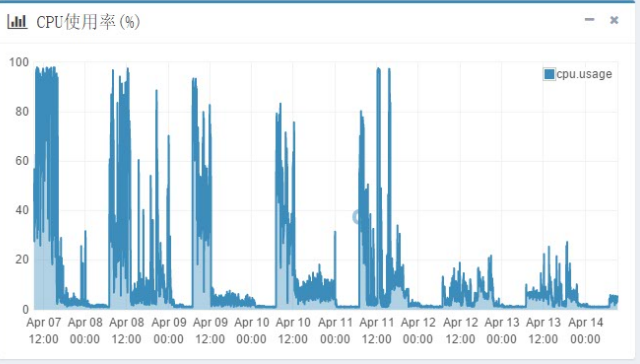
直到两周以前,我们又遇到了一个新问题:发送节点CPU100%.
这个问题的表象为:CPU正常执行业务时保持在80%以上,高峰时超过95%数小时。监控图标如下:
在说这个问题前,先看下发送节点的线程模型:
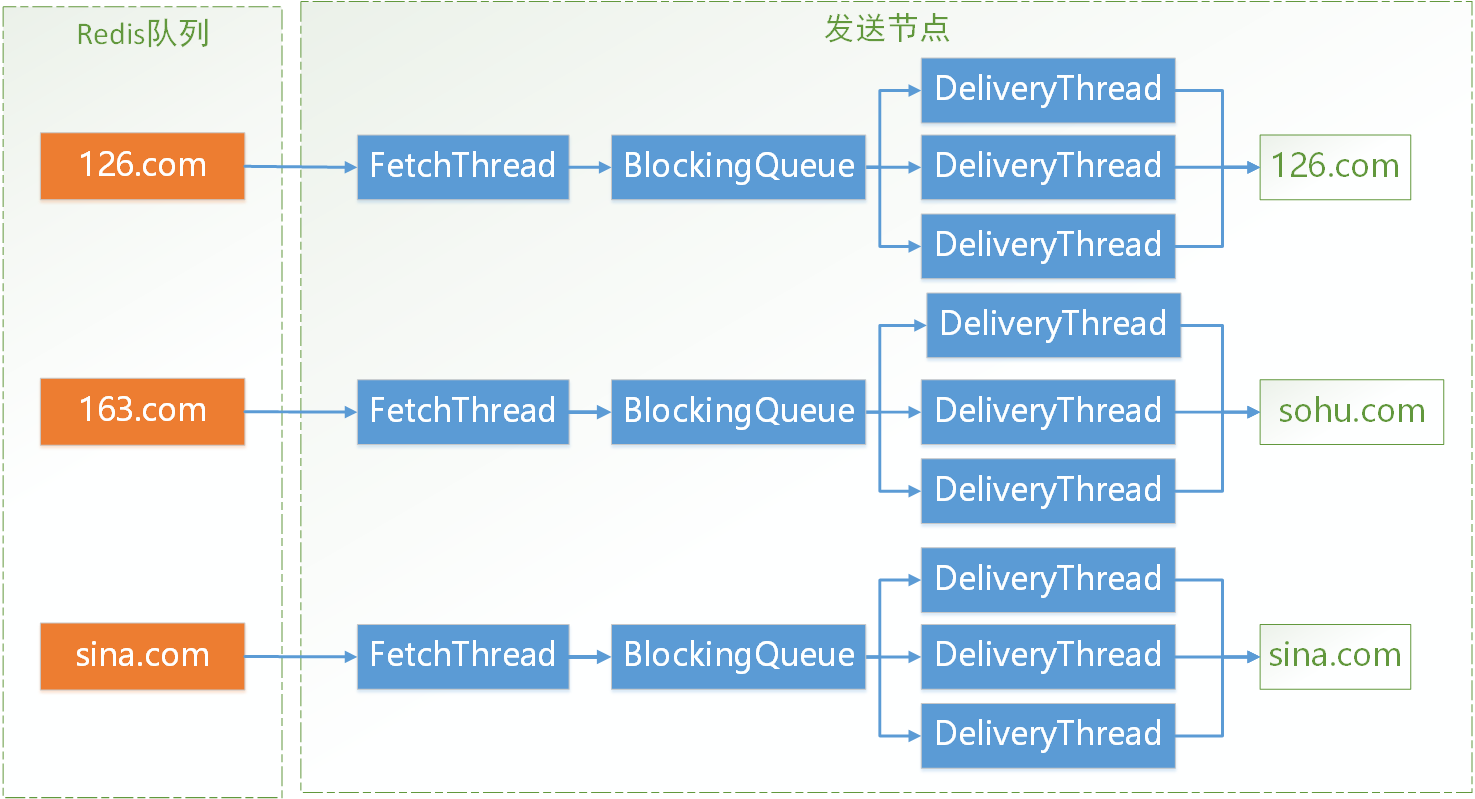
Redis中根据目标邮箱的域名有一到多个Redis队列,每个发送节点有一个跟目标邮箱相对应的FetchThread用于从Redis Pull邮件发送任务到发送节点本地,然后通过一个BlockingQueue将任务传递给DeliveryThread,DeliveryThread连接具体邮件服务商的服务器发送邮件。考虑到每次连接邮件服务商的服务器是一个相对耗时的过程,因此同一个域名的DeliveryThread有多个,是多线程并发执行的。
既然表象是CPU100%,根据这个线程模型,第一步怀疑是不是线程数太多,同一时间并发导致的。查看配置后发现线程数只有几百个,同时一时间执行的只有十多个,是相对合理的,不应该是引起CPU100%的根因。
但是在检查代码时发现有这么一个业务场景:
- 由于JIMDB的封装,发送平台采用的是轮询的方式从Redis队列中Pull邮件发送任务,Redis队列为空时FetchThread会sleep一段时间,然后再检查。
- 从业务上说网易+腾讯的邮件占到了整个邮件总量的70%以上,对非前者的FetchThread来说,Pull不到几率非常高。
那就意味着发送节点上的很多FetchThread执行的是不必要的唤醒->检查->sleep的流程,白白的浪费CPU资源。
于是我们利用事件驱动的思想将模型稍稍改变一下:
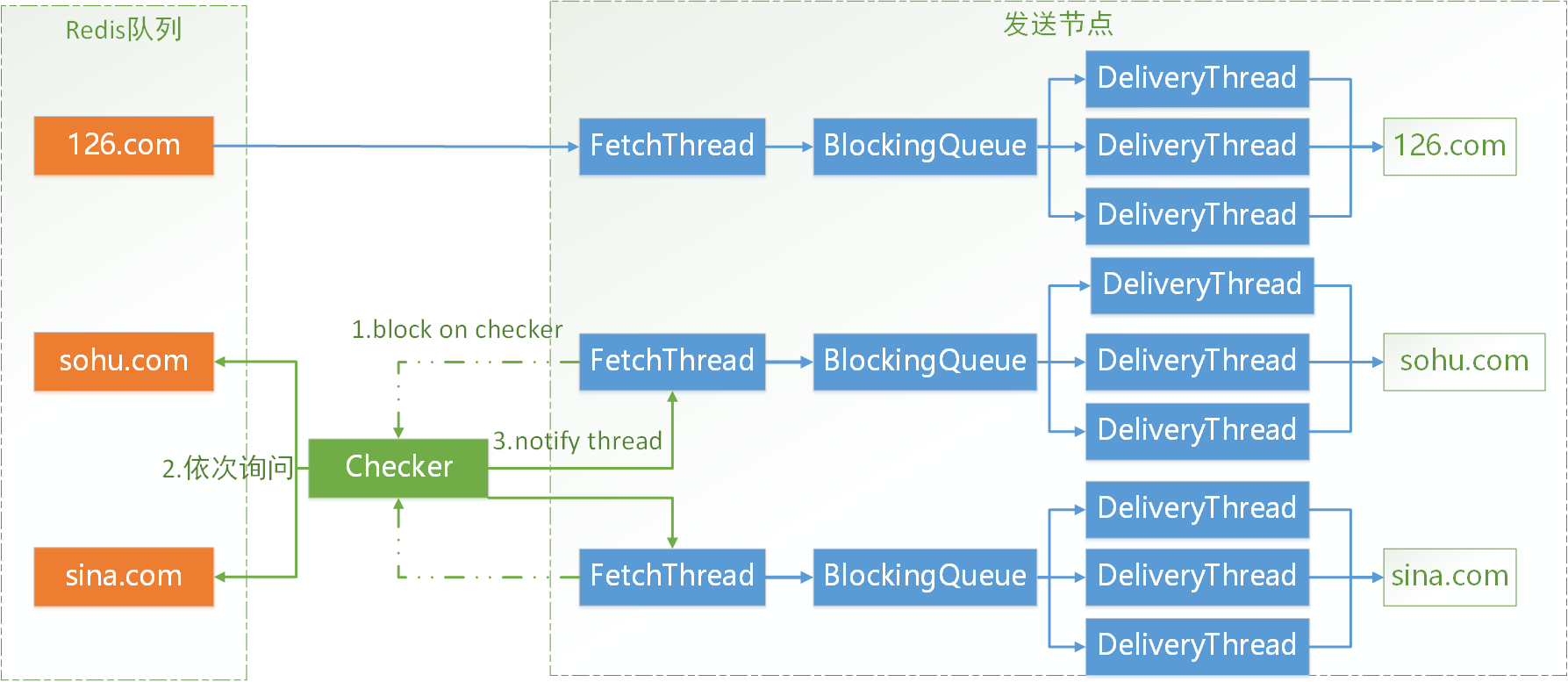
每次FetchThread对应的Redis队列为空时,将该线程阻塞到Checker上,由Checker统一对多个Redis队列的Pull条件做判断,符合Pull条件后再唤醒FetchThread。
Pull条件为:
1.FetchThread的本地队列长度小于初始长度的一半。
2.Redis队列不为空。
同时满足以上两个条件,视为可以唤醒对应的FetchThread。
以上的改造本质上还是在降低线程上下文切换的次数,将简单工作归一化,并将多路并发改为阻塞+事件驱动和降低拉取频率,进一步减少线程占用CPU的时间片的机会。
上线后,发送节点的CPU占用率有了20%左右的下降,但是并没有直接将CPU的利用率优化为非常理想的情况(20%以下),我们怀疑并没有找到真正的原因。
于是我们接着对邮件发送流程做了进一步的梳理,发现了一个非常奇怪的地方,代码如下:

我们在发送节点上使用了Handlebars做邮件内容的渲染,在初始化时使用了Concurrent相关的Map做模板的缓存,但是每次渲染前却要重新new一个HandlebarUtil,那每个HandlebarUtil岂不是用的都是不同的TemplateCache对象?既然如此,为什么要用Concurrent(意味着线程安全)的Map?
进一步阅读源码后发现无论是Velocity还是Handlebars在渲染先都需要对模板做语法解析,构建抽象语法树(AST),直至生成Template对象。构建的整个过程是相对消耗计算资源的,因此猜想Velocity或者Handlebars会对Template做缓存,只对同一个模板解析一次。
为了验证猜想,可以把渲染的过程单独运行下:
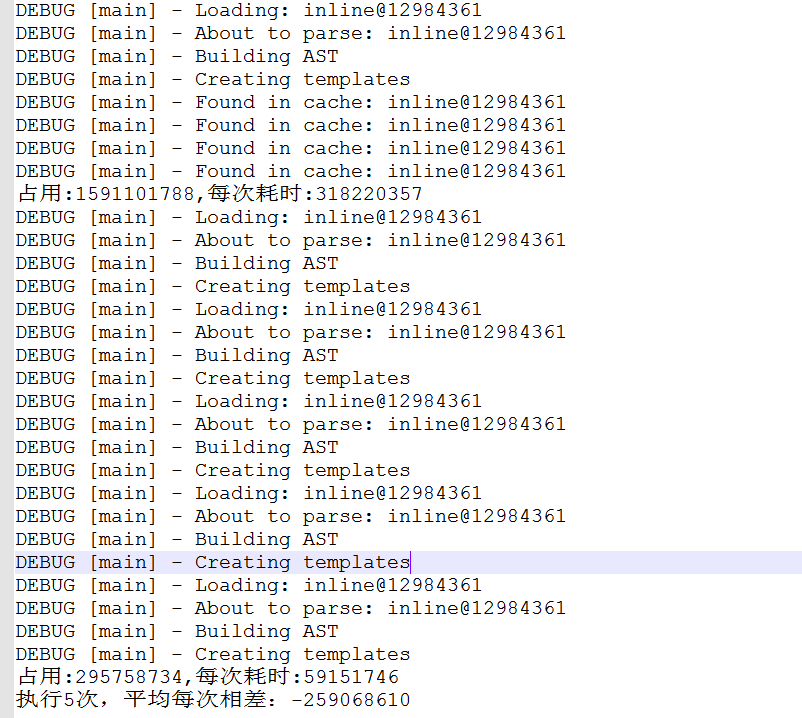
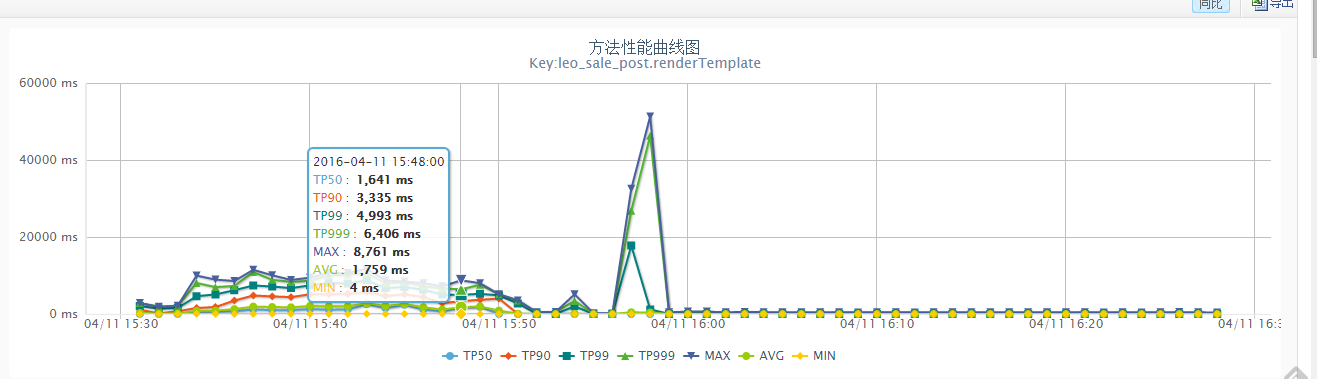
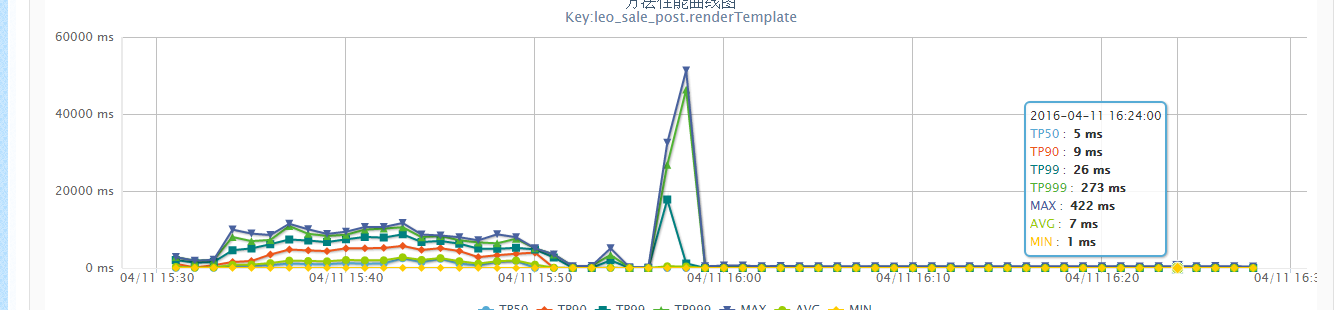
可以看到Handlebars的确可以对Template做了缓存,并且每次渲染前会优先去缓存中查找Template。而除了同样执行5次,耗时开销特别大以外,CPU的开销也同样特别大,上图为使用了缓存CPU利用率,下图为没有使用到缓存的CPU利用率:
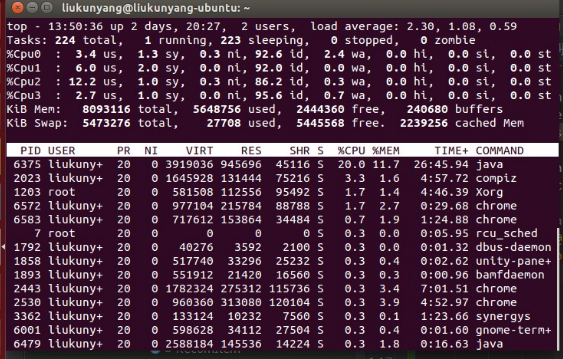
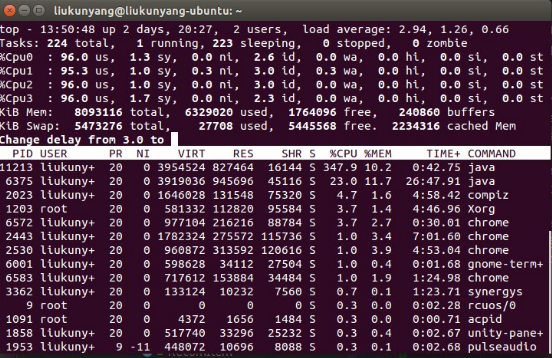
找到了原因,修改就比较简单了保证handlebars对象是单例的,能够尽量使用缓存即可。
上线后结果如下:
至此,整个性能优化工作已经基本完成了,从每个案例的优化方案来看,有以下几点经验想和大家分享:
- 性能优化首先应该定位到真正原因,从原因下手去想方案。
- 方案应该贴合业务本身,从客观规律、业务规则的角度去分析问题往往更容易找到突破点。
- 一个细小的问题在业务量巨大的时候甚至可能压垮服务的根因,开发过程中要注意每个细节点的处理。
- 平时多积累相关工具的使用经验,遇到问题时能结合多个工具定位问题。
谢谢大家。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

