
36大数据专稿,原文作者:Martyn Jones 本文由1号店-欧显东编译向36大数据投稿 ,并授权36大数据独家发布。转载必须获得本站及作者的同意,拒绝任何不标明作者及来源的转载!
引言:
为了带来一些类似的简单性,连贯性和完整性的大数据的辩论,我分享一个普遍信息架构和管理的进化模型。
这是对大数据到一个更通用的体系结构框架的调整和布局,架构集成了数据仓库(DW 2.0),商业智能和统计分析。
这个模型目前称为DW 3.0信息提供框架,简称DW 3.0。
回顾
在以前的一篇比较适用的博客名为“ Data Made Simple – Even ‘Big Data ‘ ”,里面主要有三个粗略类型的数据:企业运营数据;企业过程数据;以及企业信息数据。如下图:

图1-简要数据模型
简而言之数据的类型可以定义在以下几个:
企业运营数据:这是用于应用程序的数据,支持一个企业的日常运营。
企业过程数据:这是从企业系统是运行的测量和管理收集的数据。
企业信息数据:这主要是数据收集的来自内部和外部的数据源,通常最重要来源是企业运营数据。
这三个底层类型数据是DW 3.0基础。
主体
下面的图展示了DW 3.0总体框架::
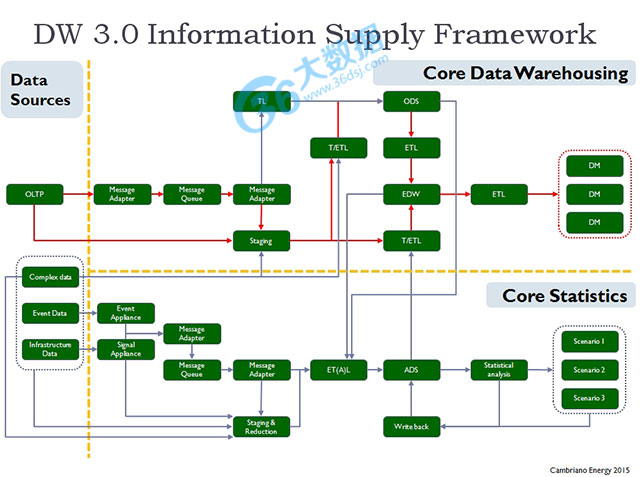
图2 -DW3.0信息框架
在这个图中有三个主要元素:数据来源,核心数据仓库和核心数据。
数据来源:这个元素涵盖所有当前的来源,可用的数据的品种和数量用来支持“挑战识别”,“选择定义”的过程和决策,包括统计分析方法和场景法
数据仓库:这是一个DW 2.0模型的演化路径。它扩展了数据仓库的范式不仅包括非结构化和复杂的数据,而且执行的信息和结果来源于统计分析之外的核心数据仓库的场景。
核心统计:这个元素涵盖了核心的统计能力,特别是但不限于对于进化的数据量,数据速度,数据质量和数据的多样性。
这模块的重点是核心统计。也将提及到三者的关系和合并的效果。
核心统计:
下图关注的核心元素模型:

图3 – DW3.0核心统计
上图说明了数据流和信息通过数据采集的过程然后到统计分析和结果的集成。
这个模型还引入了分析数据存储的概念。这可以说是最重要的建筑元素。
数据来源
为了简单起见图中有三个显式指定的数据源(当然依赖的企业数据仓库或数据集市也可以作为一个数据源),但是,我在这篇文章中主要有以下三个数据源:复杂的数据;事件数据;基础数据。
复杂数据:这是结构化或高度复杂的结构化数据文件和其他复杂的数据中包含的文物,如多媒体文件。
事件数据:这是企业过程数据的一个方面,通常在一个细粒度的抽象层次。下面是业务流程日志,互联网web活动日志和其他类似事件数据的来源。这些来源所产生的量往往会高于其他数据源,和那些目前与大数据相关的大量的信息通过追踪即使是最轻微的行为数据覆盖生成一样。例如,有人随意浏览网站。
基础数据:这方面的数据包含可能描述为信号类型数据。通过复杂的事件关联和组件分析产生的连续高速流或者高度动荡的的数据。
革命从这里开始
在这里我将稍微突出建筑元素背后的一些指导原则。
没有业务就没有理由这样做:这是什么意思呢?这意味着每一个重大行动,甚至是高度投机活动,必须有一个有形的和可信的业务支持。就和“奥马哈圣人”,和“圣诞老人”的区别一样清楚。
架构决策都是基于一个完整的和深刻的理解需要实现什么和所有可用的选择:例如,拒绝使用高性能的数据库管理产品必须是有原因的,即使这原因是成本。不应该基于技术意见,如“我不喜欢供应商”如果对Hadoop有感觉,然后使用它,如果对Exasol或Oracle或Teradata有感觉,然后使用它们。那么你一定是一个技术不可知论者,但不是一个有教条的技术论者。
统计和非传统的数据源是完全集成到数据仓库未来架构前景::建设更多的公司仓库,无论是通过行动或遗漏,将导致更大的效率低下,更大的误解和更大的风险。
架构必须连贯,连贯,可用和成本效益:如果没有,有什么意义,对吧?
没有技术,技艺或方法是短板:我们需要能够低成本纳入任何相关现有的新兴技术。
减少早期性和减少频繁性:大量的数据,特别是在高速运转的是存在问题的。减少它们的存储容量,即使我们不能在理论上减少的速度是绝对必要的。我将详细说明这一点区别。
减少早期性,减少频繁性
这里我扩大早期的主题数据减少过滤和聚合,我们可能会产生越来越多的大量的数据,但这并不意味着我们需要囤积所有它为了得到一些价值。
简单的来说这就是将初始数据进行ETL(提取和转换)尽可能靠近数据生成器。这是数据库适配器的概念,但它可以逆转的。
让我们看一个场景。
一个公司想要实施一些投机性分析每天的每一分钟收集的许多互联网网站活动日志数据成,他们运行大量的日志文件分布式平台减少数据映射。
然后他们可以分析结果数据。
面临的问题,与许多网站被黑客,设计师,而不是工程师、建筑师和数据库专家开发,是乱堆着极大的和笨拙的文物,如大量的日志文件的详细钝角和新鲜感添加数据。
我们需要确保这个挑战可以移除吗?
我们需要重新考虑网络日志,然后我们需要重新设计它。
我们需要能够进行语法分析日志数据,以减少产生的大量数据占用严重设计和详细数据。
我们需要的双重选择,能够不断地将数据发送给一个事件设备,可以用来降低数据量在一个事件会话的基础上。
如果我们必须使用日志文件,用许多小日志文件减少大量的日志文件和更多的日志周期减少几个日志周期。我们还必须最大化并行日志的好处。
所以现在,我们得到了日志数据的使用可以通过日志文件、日志文件由一个事件设备(如工具包的一部分分析数据收集适配器)或发送的设备通过消息传递信号点而来。
一旦数据已经传输(传统文件传输/共享或消息)我们可以进入下一个步骤:ET(A)L -提取、转换、分析和负载。
日志文件,我们通常采用ETL(A)但是当然我们不需要ETL中的E即提取,因为这是直接连接。
再次减少ET(AL)是另一种形式的机制,这就是为什么分析方面包括确保得到的数据通过需要的数据,而没有认可价值的垃圾和噪音,会尽早并且经常清理。
分析数据存储
分析数据存储(可以是一个分布式数据存储在某个云)支持统计分析的数据需求。这里的数据组织、结构、集成和丰富的持续波动,偶尔需要统计学家和科学家关注数据挖掘。分析数据存储中的数据可以累计或完全刷新。它可以有一个短寿命或有显著高寿命。
分析数据存储的核心是分析数据。不仅可以用于提供数据统计分析过程,但它也可以用来提供长期持久存储分析结果和场景,和未来的一些分析,因此具有“回馈”的能力。
分析数据存储中的数据和信息也可以使用、来源于数据仓库中存储的数据,它也可能受益于拥有自己的专用数据集市专门为这个目的而设计的。
在分析数据存储的统计分析的结果也可能导致反馈用于调优数据,过滤和浓缩的规则,无论是智能数据分析、复杂事件和歧视适配器或ET(AL)工作。
总结
这一定是非常短暂的对于目前的DW 3.0的标签
模型不寻求定义统计或统计分析是如何应用的,已经做了足够多,但如何适应统计在一个扩展的DW 2.0架构,和几乎不需要想出反动和不合身的问题解决方案,可以解决的更好、更有效的方法通过明智、健全的工程原则和适当的明智的应用方法,技术和技巧。
原文:Aligning Big Data
















![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

