高效使用 JavaScript 闭包
在 Node.js 中,广泛采用不同形式的闭包来支持 Node 的异步和事件驱动编程模型。通过很好地理解闭包,您可以确保所开发应用程序的功能正确性、稳定性和可伸缩性。
闭包是一种将数据与处理数据的代码相关联的自然方式,它使用 continuation passing(后继传递) 作为主要的语义风格。使用闭包时,您在一个封闭范围内定义的数据源可供该范围内创建的函数访问,甚至在已经从逻辑上退出这个封闭范围时也是如此。在函数是一等 (first-class) 变量的语言中(比如 JavaScript),此行为非常重要,因为函数的生命周期决定了函数可以看到的数据元素的生命周期。在此环境中,很容易由于疏忽而在内存中保留比期望的多得多的数据,这样做很危险。
本教程将介绍在 Node 中使用闭包的 3 种主要用例:
- 完成处理函数
- 中间函数
- 监听器函数
对于每种用例,我们都提供了示例代码,并指出了闭包的预期寿命和在寿命内保留的内存量。此信息可在设计 JavaScript 应用程序时帮助您深入了解这些用例如何影响内存使用,从而避免应用程序中的内存泄漏。
阅读: 了解 JavaScript 应用程序中的内存泄漏
阅读: JavaScript 中的内存泄漏模式
阅读: 针对 IBM SDK for Node.js 的核心转储调试
闭包和异步编程
如果您熟悉传统的顺序编程,那么在首次尝试了解异步模型时,您可能会问以下问题:
- 如果异步调用一个函数,您如何确保在调用时它后面(或周围)的代码可以处理该范围内的可用数据?或者换句话说,您如何实现依赖于异步调用的结果和副作用的剩余代码?
- 执行异步调用后,程序继续执行与异步调用无关的代码,您如何在异步调用完成后返回到最初的调用范围来继续运行?
闭包和回调可以回答这些问题。在最常见和最简单的用例中,异步方法采用了一个回调方法(具有一个关联的闭包)作为一个参数。此函数通常是在异步方法的调用位置上以内联方式进行定义的,而且该函数能访问围绕调用位置的范围的数据元素(局部变量和参数)。
举例而言,看看以下 JavaScript 代码:
function outer(a) { var b= 20; function inner(c) { var d = 40; return a * b / (d c); } return inner; } var x = outer(10); var y = x(30); 这是一个实时调试会话中的同一段代码的快照:
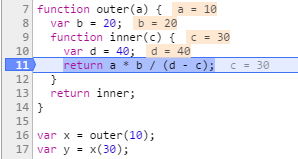
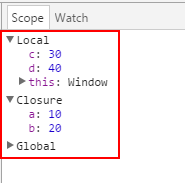
inner 函数在第 17 行调用(前面清单中的第 11 行)并在第 11 行上执行(该清单的第 5 行)。在第 16 行(清单中第 10 行),调用了 outer 函数 — 它返回 inner 函数。如屏幕截图所示,在第 17 行调用了 inner 函数并在第 11 行执行时,它能够访问它的局部变量( c 和 d ) 和 outer 函数中定义的变量( a 和 b ) — 尽管在第 16 行完成对 outer 函数的调用时已退出 outer 函数的范围。
“ 要避免内存泄漏,了解回调方法何时和在多长时间内保持可访问性很重要。 ”
回调方法处于一个可调用它的状态(也就是说,从垃圾收集角度,可以访问它),所以它保持它能访问的所有数据元素处于活动状态。要避免内存泄漏,了解回调方法何时和在多长时间内保持该状态很重要。
总体上讲,闭包通常在至少 3 种用例中很有用。在所有这 3 种用例中,基本前提都是一样的:一小段可重用的代码(一个可调用的函数)能够处理并可选地保留一个上下文。
用例 1:完成处理函数
在完成处理函数模式中,将一个函数 ( C1 ) 作为参数传递给某个方法 ( M1 ),并在 M1 完成后调用 C1 作为完成处理函数。作为该模式的一部分, M1 的实现可确保在不再需要 C1 后,它保留的对 C1 的引用会被清除。 C1 常常需要调用 M1 的范围中的一个或多个数据元素。提供对此范围的访问能力的闭包在创建 C1 时定义。常见的一种方法是使用在调用 M1 的地方以内联方式定义的匿名方法。结果会得到一个 C1 闭包,它提供了访问可供 M1 使用的所有变量和参数的能力。
一个示例是 setTimeout() 方法。计时器过期后,调用完成函数 (completion function),并清除为计时器保留的完成函数 ( C1 ) 引用:
function CustomObject() { } function run() { var data = new CustomObject() setTimeout(function() { data.i = 10 }, 100) } run() 完成函数使用来自调用 setTimeout 方法的上下文的 data 变量。甚至在 run() 方法完成后,为完成处理函数创建的闭包仍有可能引用 CustomObject ,而不会对它进行垃圾收集。
内存保留
闭包上下文是在定义完成函数 ( C1 ) 时创建的,该上下文由可在创建 C1 的范围中访问的变量和参数组成。 C1 闭包会保留到以下时刻:
- 完成方法被调用并完成运行, 或者 计时器被清除。
- 不会发生对
C1的其他引用。(对于匿名函数,如果满足此列表中的前述条件,则不会发生任何其他引用。)
通过使用 Chrome 开发者工具 ,我们可以看到表示计时器的 Timeout 对象通过 _onTimeout 字段而拥有完成函数(传递给 setTimeout 的匿名方法)的引用:

尽管计时器已过期,但 Timeout 对象、 _onTimeout 字段 和闭包函数都通过对它们的一个引用而保留在堆中 — 在系统中挂起的超时事件。激活计时器且后续回调完成时,会删除事件循环中的挂起事件。所有 3 个对象都无法再访问,而且它们符合在后续垃圾收集周期中收集的条件。
清除计时器时(通过 clearTimeout 方法),会从 _onTimeout 字段中删除完成函数,而且,即使由于主函数保留了对 Timeout 对象的引用而保留了该对象,(只要不再发生对该函数的其他引用)该函数仍然可以在后续垃圾收集周期中收集。
在此屏幕截图中,将会对比触发计时器之前和之后获取的 堆转储 :

#New 列显示了在转储之间添加的新对象,#Deleted 列显示了在转储之间收集的对象。突出显示的部分显示, CustomObject 存在于第一个转储中,但已被收集且未包含在第二个转储中,因此释放了 12 字节内存。
在此模式下,自然的执行流程使内存仅保留到完成处理函数 ( C1 ) 将其 “完成” 该方法 ( M1 ) 的工作处理完之时。结果是(只要及时完成应用程序调用的方法)您不需要特别注意避免内存泄漏。
设计实现此模式的函数时,请确保在触发回调时清除了对回调函数的所有引用。这样,即可确保满足使用您的函数的应用程序的内存保留预期。
用例 2:中间函数
在某些情况下,您需要能够以更加反复、迭代式和出乎意料的方式处理数据,无论数据是以异步创建还是同步方式创建的。对于这些情况,您可返回一个 中间函数 ,可调用该函数一次或多次来访问所需的数据或完成所需的计算。与完成处理函数一样,您在定义函数时创建闭包,闭包提供了访问定义该函数的范围中包含的所有变量和参数的能力。
此模式的一个例子是数据流处理,其中服务器返回一大块数据,每收到一个数据块,就会调用客户端的数据接收器回调。因为数据流是异步的,所以操作(比如数据积累)必须是迭代式的,并以一种出乎意料的方式执行。下面的程序演示了此场景:
function readData() { var buf = new Buffer(1024 * 1024 * 100) var index = 0 buf.fill('g') //simulates real read return function() { index++ if (index < buf.length) { return buf[index-1] } else { return '' } } } var data = readData() var next = data() while (next !== '') { // process data() next = data() } 在这种情况下,只要 data 变量仍在范围中,就会保留 buf 。 buf 缓冲区的大小会导致保留大量内存,即使这对应用程序开发者而言不那么明显。我们可以使用 Chrome 开发者工具查看此效果,如在完成 while 循环后获得的快照所示:保留了更大的缓冲区,尽管不再使用它。
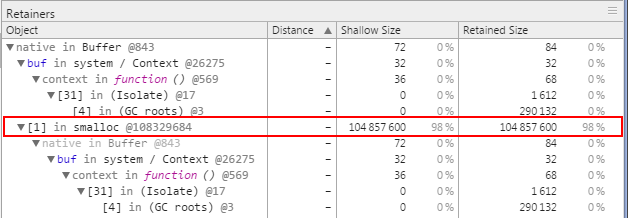
内存保留
甚至在应用程序完成中间函数后,对该函数的引用仍会让关联闭包保持活动状态。要让该数据变得可以收集,应用程序必须重写此引用 — 例如按下列方式设置对中间函数的引用:
// Manual cleanup data = null;
此代码允许对闭包上下文进行垃圾收集。下面这个来自堆转储的屏幕截图(在将 data 设置为 null 后获取)表明可以通过手动废弃对保留的数据执行垃圾收集:

突出显示的行表明,缓冲区已被收集,它的关联内存已被释放。
通常,可以构造中间函数来限制潜在的内存泄漏。例如,一个允许增量读取大数据集的中间函数,可以删除对返回的数据部分的引用。但在这些情况下,一定要注意此方法不得给应用程序中采用非中间函数方式访问该数据的其他部分带来问题。
创建实现中间模式的 API 时,请小心地记录下内存保留特征,以便用户了解确保所有引用都被废弃的需求。更好的方法是,尽可能实现您的 API,使保留的数据可在中间函数中不再需要它时被释放。
例如,本节中的前一个示例中的函数可重写为:
return function() { index++; if (index < buf.length) { return buf[index-1] } else { buf = null return } } 此版本可确保在不再需要大型缓冲区时,可以收集它们。
用例 3:监听器函数
一种常见模式是注册函数来监听特定事件的发生情况。但问题是,监听器函数的生命周期通常是无限期的,或者不为应用程序所知。因此,监听器函数最可能导致内存泄漏。
“ 监听器函数最可能导致内存泄漏。 ”
大多数流处理/缓冲方案都使用该机制来缓存或积累一个外部方法中定义的瞬时数据,而在一个匿名闭包函数中进行访问。您无法控制安装的监听器的生命周期或对其一无所知时,就会出现风险,如下面的示例所示:
var EventEmitter = require('events').EventEmitter var ev = new EventEmitter() function run() { var buf = new Buffer(1024 * 1024 * 100) var index = 0 buf.fill('g') ev.on('readNext', function() { var ret = buf[index] index++ return ret }); } 内存保留
下面的屏幕截图(在调用 run() 方法后获取)展示了如何为大型缓冲区 buf 保留内存。通过支配树可以看到,这个大型缓冲区由于与该事件的关联而保持活动:
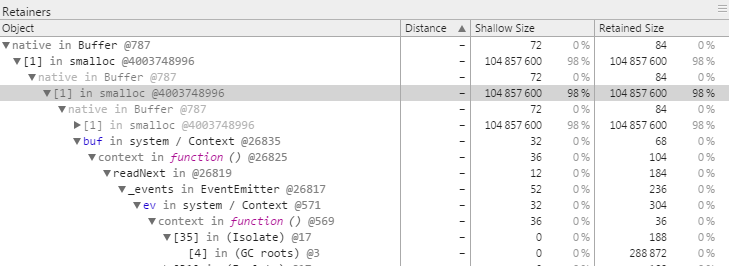
回调函数(监听器)保留的数据会在撤销注册处理函数之前一直保持活动状态 — 甚至在读取了所有数据后仍会保持活动状态。在某些情况下,对监听器的各次回调之间可能不再需要数据。如果可能,通常最好根据需要分配数据,而不是在各次调用之间保留它。
在其他情况下,您无法避免在监听器的各次调用之间保留数据。解决方案是确保 API 提供了一种途径来在不再需要回调时撤销注册它们。这是一个示例:
// Because our closure is anonymous, we can't remove the listener by name, // so we clean all listeners. ev.removeAllListeners()
此用例的一个著名的例子是一种典型的 HTTP 服务器实现:
var http = require('http'); function runServer() { /* data local to runServer, but also accessible to * the closure context retained for the anonymous * callback function by virtue of the lexical scope * in the outer enclosure. */ var buf = new Buffer(1024 * 1024 * 100); buf.fill('g'); http.createServer(function (req, res) { res.end(buf); }).listen(8080); } runServer(); 尽管此示例展示了一种使用内部函数的便捷方式,但请注意,只要服务器对象处于活动状态,回调函数(和缓冲区对象)就都是活动的。只在服务器关闭后,该对象才符合收集条件。在下面的屏幕截图中可以看到,由于服务器请求监听器使用了缓冲区,所以该缓冲区将保持活动状态:
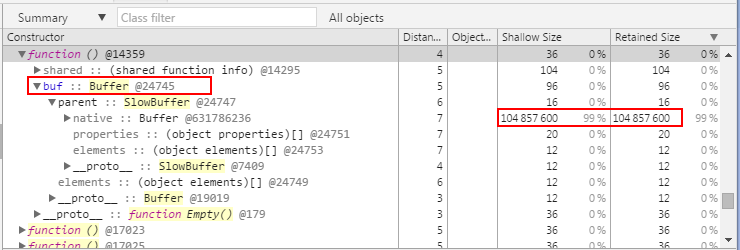
由此得出的教训是,对于任何保留大量数据的监听器,都需要理解并记录监听器的必要寿命,确保在不再需要监听器时注销它。另一种明智的方法是,确保监听器在各次调用之间保留最少量的数据,因为它们通常具有很长的寿命。
结束语
闭包是一种强大的编程结构,能够以更加灵活的、出乎意料的方式在代码和数据之间实现绑定。但是,习惯于 Java 或 C++ 等旧式语言的程序员可能不熟悉它的范围语义。为了避免内存泄漏,一定要理解闭包的特征和它们的生命周期。
相关主题: Web 开发 Node.js
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

