反欺诈架构中的数据架构及其技术挑战
反欺诈架构中的数据架构及其技术挑战
反欺诈系统架构方面的一半工作可能花在了稳健而灵活的数据基础设施上。要是没有数据,规则和模型就玩不转。许多时候,你需要从不同的角度和不同的距离来看待同一批数据,还需要能够不断以低成本获取新数据;你迟早会发现自己拥有海量数据,因此拥有一套可扩展、稳健的基础设施来管理这些数据是核心。
- 作者:布加迪编译 来源:51CTO.com | 2016-05-17 10:26
【51CTO.com快译】数据、规则和模型,这些是反欺诈软件系统的基本构建模块。我会在一系列文章中介绍这些基础模块。

关键:合适的数据在合适的时间以合适的格式呈现
反欺诈系统架构方面的一半工作可能花在了稳健而灵活的数据基础设施上。要是没有数据,规则和模型就玩不转。许多时候,你需要从不同的角度和不同的距 离来看待同一批数据,还需要能够不断以低成本获取新数据;你迟早会发现自己拥有海量数据,因此拥有一套可扩展、稳健的基础设施来管理这些数据是核心。
这么说可能过于简单了。下面我们来看看你要处理的一些常见类型的数据:
聚集
- 例子:客户的终生支出(合计)、SKU的争议数(计数)、客户使用的所有IP地址(聚集和重复数据删除),以及某国别的最新采购期(最小/最大)。
- 目的:对于迅速从不同角度了解某个帐户或实体很有用,你可以了解大局以及相应交易与之相比如何。
- 技术挑战:
-
·实时聚集,还是预聚集?
- “实时”的优点:可获得粒度更细的最新数据。
- “实时”的缺点:尤其是聚集的数据量很庞大时,操作开销很大;原始数据源与反欺诈决策紧密相关。
- 预聚集的优点:可以将开销很大的数据处理交给异步处理机制,那样决策时数据检索起来速度快,成本低;决策服务完全依赖聚集和专用的欺诈数据,而不是原始事务数据源。
- 预聚集的缺点:由于具有异步性,聚集的数据可能过时。
- 通 常来说,数据在决策时读取,但是因影响数据的活动而出现带外变更(添加、更新和删除)。比如说,在结账决策点,你可能想要评估这个用户退了多少次商品。退 货的流程有别于正常结账,而且本身有全然不同的生命周期。因此,结账时聚集退货数量没有意义。此外,某个正常用户帐户的退货数量应该远低于结账数量,所以 按结账数量计算退货数量是一种过分行为,浪费资源。
- 通常来说,预聚集比实时聚集更具扩展性。
-
- 尽可能使用增量聚集
- 简单的例子就是用户的最大采购量。一般来说,你会保存用户输入的最大数,如果新的数量大于之前的最大数,你就换成新的数量;不然,你就忽视。每当需要聚集时检索用户的所有交易,并从中找到最大数没有太多的意义。
- 一个比较复杂的例子是SKU的争议数。每当你收到一个新的争议,你可能只想为最后一个数+1,而不是查询SKU的所有争议。当然了,这需要触发系统(可能是消息分发框架)来保证分发,而且只分发一次。
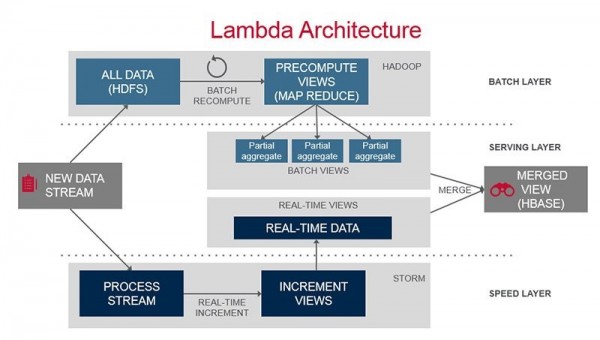
- Lambda架构
想要集两者之众长?使用Lambda架构怎么样?通过聚集批处理层(通常是旧数据,在“较慢”但更具可扩展的“大数据”基础设施上执行)和速度层(实时增量聚集最新数据,在Samza或Spark Streaming之类的流处理基础设施上执行),这就能同时获得可扩展性和新鲜度。
- 例子:在过去90秒内来自某个IP地址的企图登录次数;过去10分钟来自某个用户的企图“添加信用卡”的次数;过去24小时内来自同一个Geohash的新注册次数。
- 目的:骗子们常常采用蛮力恶意活动来攻击商家。比如说,蛮力登录攻击的症状是,同一个IP地址在短短的时间内多次企图登录。骗子们还在短短的时间内,通过未起疑心的商家的“增添信用卡”流程,测试窃取的信用卡号码。
- 速度与聚集有何不同?速度通常衡量某个活动在一段比较短的时间内(比如秒钟、分钟或小时)发生得多快,而聚集通常与更长的时间段有关。
- 技术挑战:
- 由于它处理较短的时间,可用性延迟是有待优化的主要方面。你也许能够使用同一个消息分发系统,就像在聚集使用场合下那样,以触发速度计算,但是要认真评估和监控端到端延迟。毕竟,60秒钟的延迟会让你的目标速度“过去60秒钟的登录次数”毫无用处。
- 如果异步处理系统带来了无法忍受的延迟,你可能需要考虑实时查询数据。没错,它存在与我们在上面聚集使用场合下谈论的同样缺点,不过幸好时间短,因而查询性能仍比较好。
- 速 度计算的另一个常见要求是,可以灵活地拥有不同的多个维度,也就是说可以交叉分析(slice and dice)。比如说,你可能想要知道在过去5分钟来自同一个IP地址的登录次数,但是可能还想知道在过去5分钟登录同一帐户的次数;那么,何不计算同一 IP地址登录到同一帐户的次数。这就需要你用预定义的维度/存储桶聚集数据(事先知道访问模式),或者以一种查询起来非常灵活的方式来存储原始数据(换句 话说,你没必要事先定义访问模式)。至于后一种实施方法,ElasticSearch之类的技术会行得通。
查询
- 例子:有了一个IP地址,找到地理位置信息(经度、纬度、国家和城市);从信用卡的BIN(银行识别号)到发卡行名称和银行所在国;从邮 政编码到地理位置信息。除了你免费获得(来自公共数据)或通过购买获得的外部查询数据外,许多内部生成的查询数据也非常有用,比如说来自IP地址的坏事务 在事务总数中的比例,来自某个国家的虚假注册数量,等等。
- 目的:查询数据(外部或内部)是合成的情报,它剖析了某些工具的风险状况,或者提供了可用于进一步评估的生成数据。从IP地址到地理位置的查询推导,以及从(开票)邮政编码到地理位置的推导,让你能够计算出交易地址与开票地址之间的距离。
- 技术挑战:
- 大多数查询数据并不经常变化。比如说,BIN查询可能每月最多更新一次,IP内部风险可能没必要为每个事务重新计算,但是可以每天重新计算。所以,这种类型的模式对批处理来说很理想。
- 许多数据会海量查询,比如说每笔事务。由于它们相对静态,缓存是一种出色的策略。内存提供的缓存显著缩短了延迟。视数据集的大小和延迟要求而定,它们可以与决策服务一同缓存(速度最快),或者通过集中式缓存层来缓存。
- 如果内存不适合缓存数据集,又需要文件系统,仍可以通过索引数据在内存中文件中位置来进行优化,那样第一轮是从内存获得数据的位置,然后直接访问文件中的该位置。查看mmap(https://en.wikipedia.org/wiki/Mmap)。
- 即便数据集在单个节点装不下,也可以进行分区后分发。数据可以在其中一个节点上,目录节点可以将查询请求转发给含有数据的那个节点。
- ·然查询数据不常变化,但是它们通常很庞大。这样一来,更新起来有难度。最笨拙的办法就是,更新期间,翻新整个数据集。你可能想要考虑创建一个全新版本的数据集,将它与工作版本并行上传,然后在新版本验证完毕后换掉。这确保更新过程中没有停机时间。
- 在外部,你可能想要简化自动获取更新的过程,通过通知新版本可用性来调度或触发。
- 在内部,计算查询数据对分析型数据基础设施来说是完美任务,比如数据仓库及/或Hadoop。同样,你需要一条管道,以尽可能少的人力,将生成数据传输到生产环境。
图形
- 例子:谁从同一个IP地址注册,谁使用同样的信用卡,谁是在你网站上展示同样异常浏览模式的用户。
- 目的:用户基本上是好的,骗子只是少数。不断回到你的平台来欺骗的是一小撮坏人,他们使用不同的身份(假冒或真实的身份)。检测谁是你所知道的骗子,是防止欺诈的一种有效方法。
- 技术挑战:
- 关系数据库并不以图形关系见长,尤其是需要多度关联的情况下(A与B关联,B与C关联,因而A与C关联)。
- 图形数据库(比如Neo4j)非常适合这个用途。或者,Triplestore又叫RDF(资源描述框架)也可以。
- 要考虑的方面:
- 为 你的图形关系正确建模。比如说,你可能试图通过将通过IP地址1.2.3.4与用户B关联的用户A建模成“A->B”, IP 1.2.3.4作为该链接的属性。然而,想添加同样使用1.2.3.4的用户C,你就需要表示A->C和B->C,这2个链接每个都有属性 1.2.3.4。这种情况下的IP地址“隐藏起来”或不是显式的。因而,同样的IP地址重复、单独表示。为这种场景建模的更好方法就是 A->IP(.2.3.4)、B->IP(1.2.3.4)、C->IP(1.2.3.4)。由于IP(1.2.3.4)是图形中的同 一个节点,A、B和C通过它关联起来。想发现谁通过IP地址与A关联起来,这是个简单图形,从A开始遍历,沿着外出到IP节点的边缘,然后从IP节点进入 到用户节点。
- 很难扩展图形数据库。传统的数据库扩展方法是分段(sharding)。由于图形的性质(互相关联的节点),几乎不可能对 图形分段。你可能想要考虑根据你的独特数据进行分区。比如说,如果欺骗攻击由特定的国家来区别,或受制于特定的国家,也许可以把属于同一个国家的实体扔入 到单一图形数据库节点,每个国家及/或地区有各自的节点。
日志
- 例子:决策时的所有数据点及数值;用户的会话和点击流数据。
- 目的:值得关注的活动发生时,可以深入了解状态信息非常重 要,因为事后,数据点可能被新的数值覆盖。知道时间点的数值有助于a)调查研究和b)训练你的模型。用户如何使用你的服务和网站,他们访问哪些页面,访问 顺序怎样,他们花了多少时间,这些都是值得关注的数据,可以区别正常使用模式和欺诈使用模式。
- 技术挑战:
- 数据库可以用来跟踪这些数据点,但是这些是日志数据,从不变化,支持事务的联机数据库是大材小用。
- 日志系统是非常适合于此的完美工具。可以将它们记入到文件系统日志文件,让它们定期传输到长期存储系统,比如Flume和HDFS;或者使用Kafka将它们发布到数据流,让它们在处理后,永久性保存到长期存储系统。
至于规则和模型,敬请关注下几期文章。
原文标题: Data Architecture in an Anti-Fraud Architecture
【51CTO.com独家译文,合作站点转载请注明来源】
【编辑推荐】
- 移动大数据在互联网金融反欺诈领域的应用
- 京东11.11:商品搜索系统架构设计解密
- 热点推荐:秒杀系统架构分析与实战
- 指点迷津的现代数据架构之道
- 极光推送许俊:大数据架构下的可视化智能运维监控
【责任编辑:Ophira TEL:(010)68476606】
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

