Python全栈开发之正则表达式
版权声明:此文章转载自博客园
如需转载请联系听云College团队成员阮小乙,邮箱:ruanqy#tingyun.com
正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串,在文本处理方面功能非常强大,也经常用作爬虫,来爬取特定内容,Python本身不支持正则,但是通过导入re模块,Python也能用正则表达式,下面就来讲一下python正则表达式的用法。
一、匹配规则
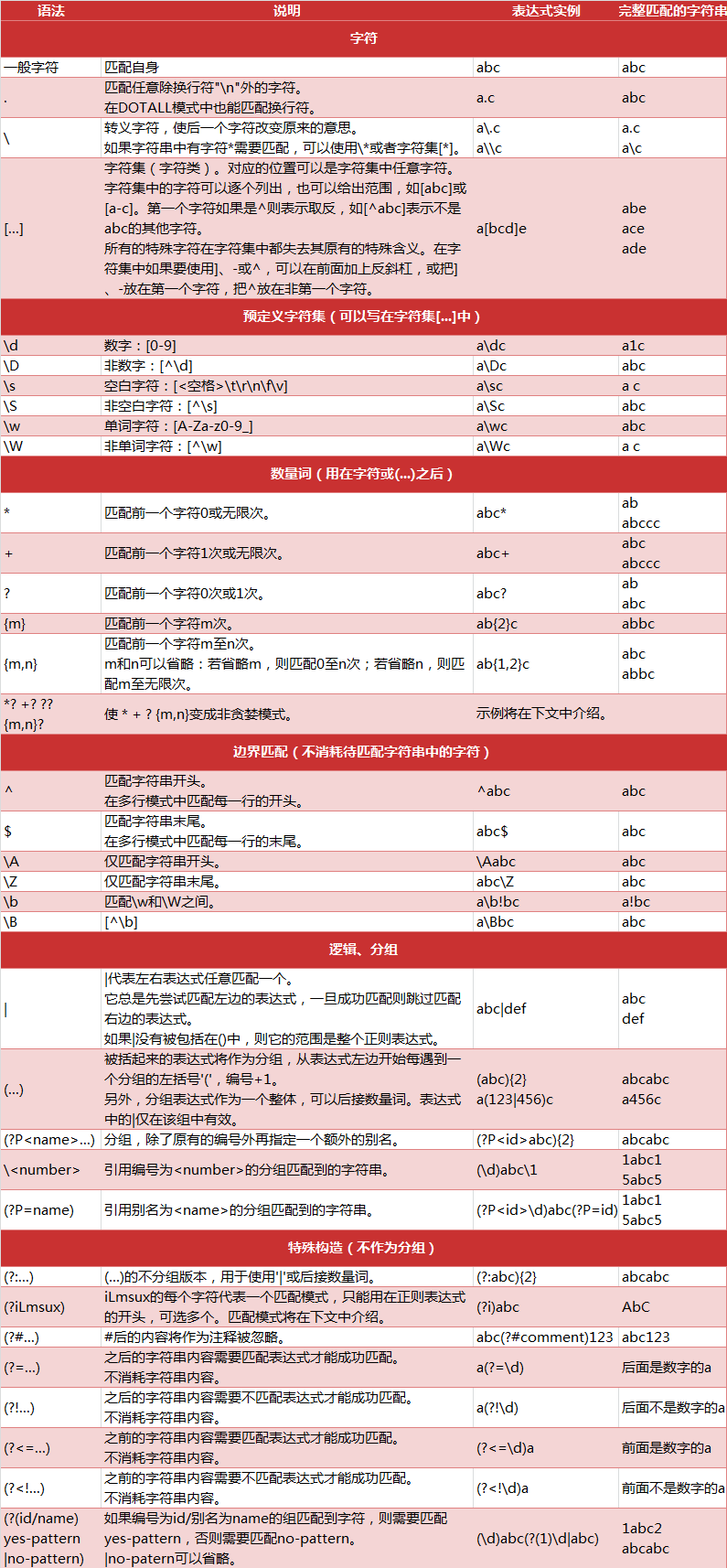
大家先看下面这张图,里面把python正则表达式的匹配规则都列举出来了,除了图中分组那部分,其他的都需要非常熟悉。
二、findall
findall(),可以将匹配到的结果以列表的形式返回,如果匹配不到则返回一个空列表,下面来看一下代码中的使用
import re l=re.findall(r'/d','4g6gggg9,9') # /d代表数字,将匹配到的元素放到一个列表里 print(l) # ['4', '6', '9', '9'] print(re.findall(r'/w','ds.._ 4')) # ['d', 's', '_', '4'],匹配字母数字下划线 print(re.findall(r'^sk','skggj,fd,7')) # 以sk开头的,['sk'] print(re.findall(r'^sk','kggj,fd,7')) # [] print(re.findall(r'k{3,5}','ffkkkkk')) # 取前面一个字符‘k'的3到5次,['kkkkk'] print(re.findall(r'a{2}','aasdaaaaaf')) # 匹配前一个字符a两次,['aa', 'aa', 'aa'] print(re.findall(r'a*x','aaaaaax')) # ['aaaaaax'] 匹配前面一个字符0次或多次,贪婪匹配 print(re.findall(r'/d*', 'www33333')) # ['', '', '', '33333', ''] print(re.findall(r'a+c','aaaacccc')) # ['aaaac'] 匹配前面一个字符的一次或多次,贪婪匹配 print(re.findall(r'a?c','aaaacccc')) # ['ac', 'c', 'c', 'c'] 匹配前面一个字符的0次或1次 print(re.findall(r'a[.]d','acdggg abd')) # .在[]里面失去了意义,所以结果为[] print(re.findall(r'[a-z]','h43.hb -gg')) # ['h', 'h', 'b', 'g', 'g'] print(re.findall(r'[^a-z]','h43.hb -gg')) # 取反,['4', '3', '.', ' ', '-'] print(re.findall(r'ax$','dsadax')) # 以'ax'结尾 ['ax'] print(re.findall(r'a(/d+)b','a23666b')) # ['23666'] print(re.findall(r'a(/d+?)b','a23666b')) # ['23666']前后均有限定条件,则非贪婪模式失效 print(re.findall(r'a(/d+)','a23b')) # ['23'] print(re.findall(r'a(/d+?)','a23b')) # [2] 加上一个?变成非贪婪模式 三、match和search
match从要匹配的字符串的开头开始,尝试匹配,如果字符串开始不符合正则表达式,则匹配失败,函数返回None,匹配成功的话用group取出匹配的结果,search和mach很像,search是匹配整个字符串直道匹配到一个就返回。下面看下代码。
import re print(re.match(r'a/d','a333333a4').group()) # a3,匹配到第一个返回 print(re.match(r'a/d','ta333333a4')) # 字符串开头不满足要求,返回一个None print(re.search(r'a/d','ta333333a4').group()) # a3 整个字符串匹配不需要从开头匹配 print(re.search(r'a(/d+)','a23b').group()) # a23 这里需要注意的是group()返回的是整个匹配到的字符串,如果是group(1)的话就只返回 23 了 print(re.search(r'a(/d+?)','a2366666666666b').group()) # a2 非贪婪模式 print(re.search(r'a(/d+)b','a23666b').group(1)) # 23666 group(1)返回第一个组
四、split、sub和subn
split能够将匹配的子串分割后返回列表,sub能将匹配到的字段用另一个字符串替换返回替换后的字符串,subn还返回替换的次数,下面再代码上看一下他们的用法
import re print(re.split(r'/d','sd.4,r5')) # 以数字分割,注意第二次以'5'分割的时候,后面有一个空格 ['sd.',',r',''] print(re.sub(r'/d','OK','3,4sfds.6hhh')) # OK,OKsfds.OKhhh print(re.sub(r'/d','OK','3,4sfds.6hhh',2)) # 2表示指定替换两次 OK,OKsfds.6hhh print(re.subn(r'/d','OK','3,4sfds.6hhh')) # ('OK,OKsfds.OKhhh', 3) 将替换的次数也返回了 五、原生字符串、编译、分组
1、原生字符串
细心的人会发现,我每一次在写匹配规则的话,都在前面加了一个r,为什么要这样写,下面从代码上来说明,
import re #“/b”在ASCII 字符中代表退格键,/b”在正则表达式中代表“匹配一个单词边界” print(re.findall("/bblow","jason blow cat")) #这里/b代表退格键,所以没有匹配到 print(re.findall("//bblow","jason blow cat")) #用/转义后这里就匹配到了 ['blow'] print(re.findall(r"/bblow","jason blow cat")) #用原生字符串后就不需要转义了 ['blow'] 你可能注意到我们在正则表达式里使用“/d”,没用原始字符串,也没出现什么问题。那是因为ASCII 里没有对应的特殊字符,所以正则表达式编译器能够知道你指的是一个十进制数字。但是我们写代码本着严谨简单的原理,最好是都写成原生字符串的格式。
2、编译
如果一个匹配规则,我们要使用多次,我们就可以先将其编译,以后就不用每次都在去写匹配规则,下面来看一下用法
import re c=re.compile(r'/d') #以后要在次使用的话,只需直接调用即可 print(c.findall('as3..56,')) #['3', '5', '6'] 3、分组
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用()表示的就是要提取的分组,可以有多个组,分组的用法很多,这里只是简单的介绍一下
import re #findall返回的是列表,不能用group获取组 print(re.findall(r'(/d+)-([a-z])','34324-dfsdfs777-hhh')) # [('34324', 'd'), ('777', 'h')] print(re.search(r'(/d+)-([a-z])','34324-dfsdfs777-hhh').group(0)) # 34324-d 返回整体 print(re.search(r'(/d+)-([a-z])','34324-dfsdfs777-hhh').group(1)) # 34324 获取第一个组 print(re.search(r'(/d+)-([a-z])','34324-dfsdfs777-hhh').group(2)) # d 获取第二个组 print(re.search(r'(/d+)-([a-z])','34324-dfsdfs777-hhh').group(3)) # IndexError: no such group print(re.search(r"(jason)kk/1","xjasonkkjason").group()) #/1表示应用编号为1的组 jasonkkjason 五、综合练习
检测一个IP地址,比如说192.168.1.1,下面看下代码怎么实现的
c=re.compile(r'((1/d/d|2[0-4]/d|25[0-5]|[1-9]/d|/d)/.){3}(1/d/d|2[0-4]/d|25[0-5]|[1-9]/d|/d)') print(c.search('245.255.256.25asdsa10.11.244.10').group()) # 10.11.244.10 这里来解释下上面的匹配规则,先看 (1/d/d|2[0-4]/d|25[0-5]|[1-9]/d|/d)/.) 1/d/d表示匹配100-199的 | 代表或的意思,2[0-4]/d代表匹配100-249,25[0-5]代表匹配250-255,[1-9]/d|/d)代表匹配10-99和0-9,/.代表匹配一个点,{3}代表将前面的分组匹配3次,后面的一部分类似就不说明了。要匹配一个ip重要的是先理解ip每个字段的形式,然后再来写匹配规则。
想阅读更多技术文章,请访问听云技术博客,访问听云官方网站感受更多应用性能优化魔力。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

