
Web爬虫:多线程、异步与动态代理初步
0×00 前言
在采集数据的时候,经常会碰到有反采集策略规则的WAF,使得本来很简单事情变得复杂起来。黑名单、限制访问频率、检测HTTP头等这些都是常见的策略,不按常理出牌的也有检测到爬虫行为,就往里注入假数据返回,以假乱真,但为了良好的用户体验,一般都不会这么做。在遇有反采集、IP地址不够的时候,通常我们想到的是使用大量代理解决这个问题,因代理具有时效、不稳定、访问受限等不确定因素,使得有时候使用起来总会碰到一些问题。
进入正题,使用Python3简单实现一个单机版多线程/异步+多代理的爬虫,没有分布式、不谈高效率,先跑起来再说,脑补开始。。。
0×01 基础知识
1.1 代理类型
使用代理转发数据的同时,代理服务器也会改变 REMOTE_ADDR 、 HTTP_VIA 、 HTTP_X_FORWARDED_FOR 这三个变量发送给目标服务器,一般做爬虫的选择优先级为 高匿 > 混淆 > 匿名 > 透明 > 高透
- 高透代理(High Transparent Proxy):单纯地转发数据
REMOTE_ADDR = Your IP HTTP_VIA = Your IP HTTP_X_FORWARDED_FOR = Your IP - 透明代理(Transparent Proxy):知道你在用代理,知道你IP
REMOTE_ADDR = Proxy IP HTTP_VIA = Proxy IP HTTP_X_FORWARDED_FOR = Your IP - 匿名代理(Anonymous Proxy):知道你用代理,不知道你IP
REMOTE_ADDR = Proxy IP HTTP_VIA = Proxy IP HTTP_X_FORWARDED_FOR = Your Proxy - 高匿代理(High Anonymity Proxy):不知道你在用代理
REMOTE_ADDR = Proxy IP HTTP_VIA = N/A HTTP_X_FORWARDED_FOR = N/A - 混淆代理(Distorting Proxies):知道你在用代理,但你的IP是假的
REMOTE_ADDR = Proxy IP HTTP_VIA = Proxy IP HTTP_X_FORWARDED_FOR = Random IP 1.2 代理协议
一般有HTTP/HTTPS/Socks类型,Web爬虫一般只用到前面两者。
1.3 动态代理
实现动态代理一般是建立代理池,使用的时候通常有以下几种方式
- 本地存储调用,将代理保存到数据库中,需要时载入,爬虫可以作为验证代理的一部分,但代理不佳的情况下效率并不高
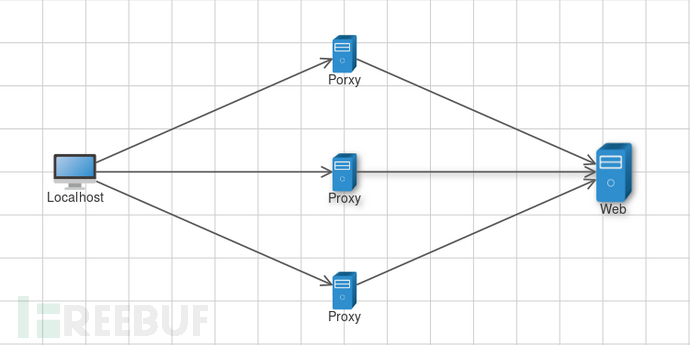
- 代理集中转发,通过建立本地代理自动切换转发,调用方便,但需要做额外的代理验证程序
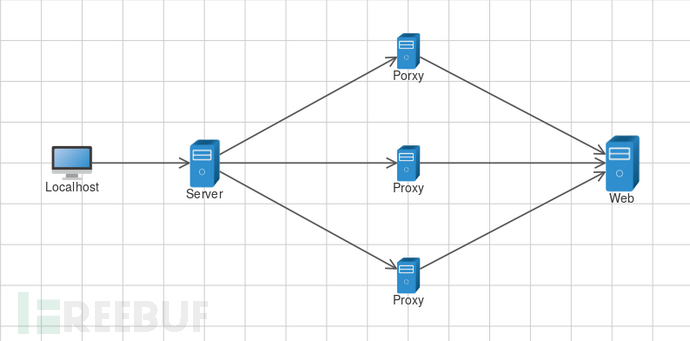
- 通过接口获取,一般通过购买服务获取,代理质量较佳,可以结合以上两种方式使用
1.4 多线程
多线程是实现任务并发的方式之一。在Python中实现多线程的方案比较多,最常见的是队列和线程类
que = queue.Queue() def worker(): while not que.empty(): do(que.get()) threads = [] nloops = 256 # start threads for i in range(nloops): t = threading.Thread(target=worker) t.start() threads.append(t) # wait for all for i in range(nloops): threads[i].join() 另外也可以使用map实现,map可以通过序列来实现两个函数之间的映射,并结合 multiprocessing.dummy 实现并发任务
from multiprocessing.dummy import Pool as ThreadPool urls = ['http://www.freebuf.com/1', 'http://www.freebuf.com/2'] pool = ThreadPool(256) # pool size res = map(urllib.request.urlopen, urls) pool.close() pool.join() 似乎更简洁,多线程实现还有其他方式,具体哪一种更好,不能一概而论,但多线程操作数据库可能会产生大量的数据库TCP/socket连接,这个需要调整数据库的最大连接数或采用线程池之类的解决。
1.5 异步IO
asyncio是在Python3.4中新增的模块,它提供可以使用协程、IO复用在单线程中实现并发模型的机制。async/await这对关键字是在Python3.5中引入的新语法,用于协成方面的支持,这无疑给写爬虫多了一种选择,asyncio包括一下主要组件:
- 事件循环(Event loop)
- I/O机制
- Futures
- Tasks
一个简单例子:
que = asyncio.Queue() urls = ['http://www.freebuf.com/1', 'http://www.freebuf.com/2'] async def woker(): while True: q = await que.get() try: await do(q) finally: que.task_done() async def main(): await asyncio.wait([que.put(i) for i in urls]) tasks = [asyncio.ensure_future(self.woker())] await que.join() for task in tasks: task.cancel() loop = asyncio.get_event_loop() loop.run_until_complete(main()) loop.close() 使用队列是因为后面还要往里面回填数据,注:asyncio中的队列Queue不是线程安全的
0×02 获取与存储数据
2.1 加代理的GET请求
- 多线程
代理类型支持http、https,其他类型没有去测试
pxy = {'http': '8.8.8.8:80'} proxy_handler = urllib.request.ProxyHandler(pxy) opener = urllib.request.build_opener(proxy_handler) opener.addheaders = [('User-agent', 'Mozilla/5.0'),('Host','www.freebuf.com')] html = opener.open(url).read().decode('utf-8','ignore') - 异步
aiohttp中的代理类型目前好像只支持http,测试https会抛处异常
conn = aiohttp.ProxyConnector(proxy="http://some.proxy.com") session = aiohttp.ClientSession(connector=conn) async with session.get('http://python.org') as resp: print(resp.read().decode('utf-8','ignore')) POST请求实现也类似
2.2 解码
有时候网页中夹有一些特殊的字符导致无法正常解码而掉丢整条记录,可以加ignore参数忽略掉
>>> b'freebuf.com/xff'.decode('utf8') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 11: invalid start byte >>> b'freebuf.com/xff'.decode('utf8', 'ignore') 'freebuf.com' >>> 2.3 HTML解析
- BeautifulSoup
from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'lxml') - re
使用正则匹配时应使用懒惰模式使匹配结果更准确
import re re.compile(r'<div>(.*?)</div>').findall(html) 2.4 保存副本
在采集的同时建议保存一份副本在本地,如有某个元素匹配错了,可以从本地快速获取,而无须再去采集。
with open('bak_xxx.html', 'wt') as f: f.write(html) 2.5 数据存储
以MySQL为例,一般分3张表
- data 存放要采集的数据
- proxy 存放代理
- temp 临时表,一般用来存放无效的任务id
2.6 连接数据库
- 多线程时使用pymysql
import pymysql conn = pymysql.connect(host='127.0.0.1', user='test', passwd='test', db='test' ,unix_socket='/var/run/mysqld/mysqld.sock', charset='utf8') - 异步使用aiomysql
import aiomysql pool = await aiomysql.create_pool(host='127.0.0.1', db='test', user='test', password='test' ,unix_socket='/var/run/mysqld/mysqld.sock', charset='utf8' ,loop=loop, minsize=1, maxsize=20) 0×03 维持爬虫
所谓维持,就是得保证爬虫能正常地进行任务,而不会被异常中断而重启无法续抓、低代理情况下无法继续进行等情况。
3.1 整体流程
循环任务队列至空,代理循环载入,一个任务配一个代理,丢弃无法使用的代理并将任务填回队列,一个简单的图
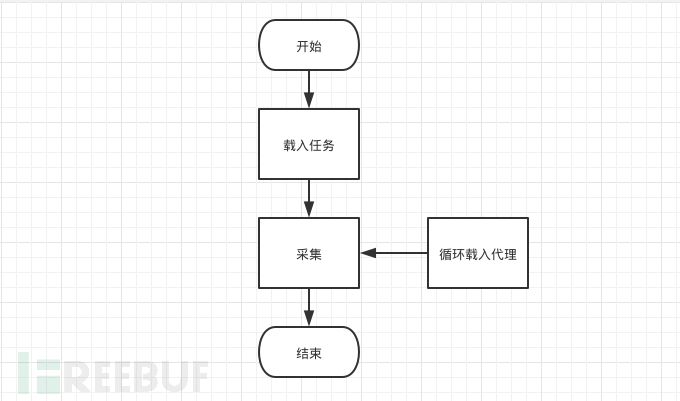
3.2 更新代理
将代理记录存到MySQL数据库,每隔一定时间脚本就去数据库抽取载入脚本。更新代理一般可以通过以下两种方式
- 加锁堵塞线程载入
为了防止在在proxy队列为空时其他线程也进入造成多次加载,使用加锁堵塞线程加载完毕再释放
lock = threading.Lock() if lock.acquire(): if pxy_queue.empty(): await load_proxy() lock.release() - 将任务分割循环启动
有点类似于执行完sleep(100)后再次初始化执行从而将代理更新进去,直到结束exit掉进程
while True: main() time.sleep(100) 3.3 验证代理
使用代理一般会有以下几种情况
- 无法建立连接
- 可以连接,请求超时
- 正常返回(包括200,30x,40x,50x)
你看到的未必是真的,先来看个例子
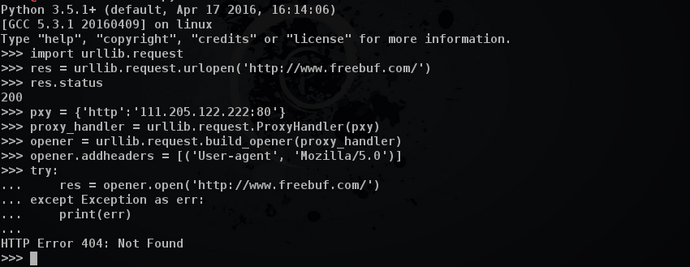
明明有资源,代理却给你来个404,为了解决这个问题,在采集前先对代理进行首次测试,通过了再次使用
# pxy['test'] 为数据表字段值 if pxy['test']: data = get_html(test_url, pxy) if data['status']==200 and test_txt in data['html']: pass else: return 3.4 保持代理
代理较少时,通过时间延时使代理隔30~60秒去访问一次目标,这样就不会触发拦截。
另外一种情况代理的稳定性较差,代理数量较少的情况,可以通过计数的方式维持代理,比如:一个代理连续三次出现不可连接或超时再做排除,成功返回从新计算,不至于一下子把代理全部干掉了。
3.5 快速启动
中途中断重启脚本,为了将已经获取的和已经排除的目标id快速去除,可以一次性查询出来用集合差获取未完成的任务id,举个栗子:
pid_set = set([r['pid'] for r in res]) if res else set() task_set = set([r for r in range(1, max_pid)]) # 取集合差为剩余任务pid task_set = task_set - pid_set 差集s-t的时间复杂度是O(len(s)),这比使用for和x in s再append()要快许多。
3.6 异常记录
脚本运行在可能出错的地方加try…except,在logging记录时加exc_info参数记录异常信息到日志,以便分析
try: pass except: logger.error(sql, exc_info=True) 0×04 案例演示
脑补完毕,我以采集Freebuf.COM所有文章为例
4.1 分析
在FB首页展现文章的链接都是经过分类的,像这样:
- http://www.freebuf.com/articles/terminal/93851.html
- http://www.freebuf.com/articles/database/101110.html
这就不太符合爬虫可遍历规则,毕竟不知道文章id属于哪个分类,总不能把分页爬一次再抓一次,可再寻找寻找。投过搞的童鞋都知道有个文章预览功能,它的链接是这样的:
- http://www.freebuf.com/?p=101110&preview=true
它并没有分类,经过测试,已经发表的文章依然可以使用预览功能,也可以通过文章ID遍历去提前查看哪些未发表的文章
4.2 提取数据
把HTML源码GET回来后,那就是提取所要的数据了
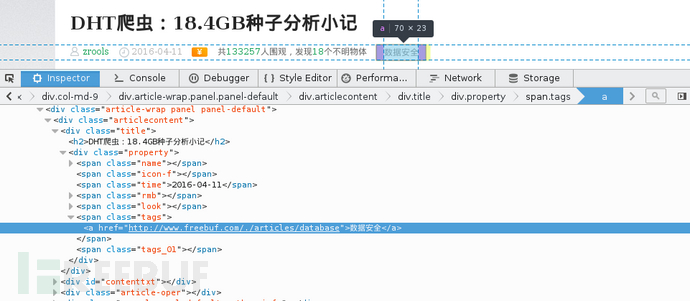
使用BeautifulSoup对数据进行查找提取,从一篇文章页面可以获得
- 文章ID
- 文章作者
- 文章标题
- 发表时间
- 文章分类
- 是否金币/现金奖励
- 文章主体内容
其他数据按需要而定,数据表结构按以上设计,数据解析部分
soup = BeautifulSoup(html, 'lxml') arct = soup.find(class_='articlecontent') head = arct.find(class_='title') title = head.find('h2').get_text().strip() # 文章标题 content = str(arct.find(id='contenttxt')).strip() # 主题内容,HTLM格式 ...... 4.3 排除错误
200、301、302、404、500这几个一般是常用的,错误也有可能是通过200返回的
# 正常返回,排除该pid if status in (301, 302, 404): return await self.insert_temp(pid, status) # 一般为代理不能用或400,403,502由代理原因引起的,将文章pid填回任务队列 if status != 200: await asyncio.wait([self.pid_queue.put(pid)]) return await self.update_proxy('status', 'status+1', pxy) 4.4 结果分析
采集数据大多情况下是做统计分析,从而得到些什么有价值的信息,比如哪些文章比较受欢迎、每月发布数量走势等等。有时还需要过滤掉不需要的数据,比如从抓取的数据中看有大量测试的、未审核的文章
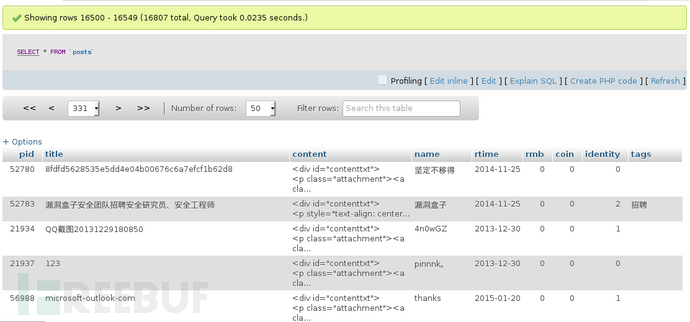
判断文章是否已经审核/发表的一个简单技巧是:该文章是否有分类
4.5 可视化展示
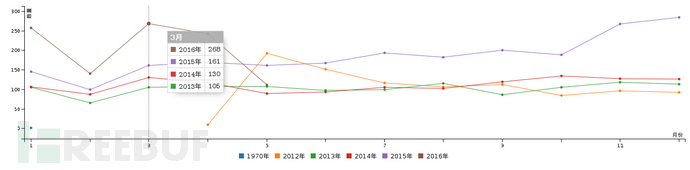
有时候数据太多的时候,进行可视化展示更直观,可以使用Excel,前端D3.js、C3.js等工具生成图表,以下是抓取到的数据FB历年每个月发布文章数量展示图(测试量:105,000,获取有效数量:16,807,有分类数量::6,750,下图为有分类文章统计,数据不一定准确,以官方的为准)
0×05 总结
本文只是记录我的一些想法和实践,以及碰到的问题采取的一些解决办法,很多地方可能写的不完善或不妥,或有更好的解决方案,只有把话题引出来了,才有机会去发现、改进。脚本是前段时间准备离职的时候采用多线程去抓某勾网数据时候写的,不常写爬虫,总会遇到或忽略某些问题。异步方式是写文章时临时码的,写得也比较简陋,只是想简单说明下多代理的一种实现方式,毕竟没有涉及Cookie、验证码、Token、动态解析等内容。
Python,人家用来做科学计算,而我却用来采集数据…
0×06 参考
- [Python之asyncio] https://vvl.me/2016/03/12/python-coroutines/
- [透明代理、匿名代理、混淆代理、高匿代理有什么区别] 出处不详、源于网络
本文中涉及的脚本: GitHub ,存放在freebuf_spider目录。
*本文作者:zrools,本文属FreeBuf黑客与极客(FreeBuf.COM)原创奖励计划,未经许可禁止转载
正文到此结束
- 本文标签: 数据库 lib Logging 数据 源码 解析 https final 安全 http update 时间 db XML find dist 文章 黑客 测试 HTML git 锁 标题 ask rmi GitHub remote URLs tar client python UI 协议 App ip 参数 进程 统计 queue 目录 多线程 tab DOM build map ACE 服务器 CTO mina 分页 线程 src 线程池 mysql IDE unix 遍历 js 总结 sql Word web TCP 质量 Excel
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

