快速入门Scrapy--打赏用什么措辞最吸金?
Scrapy是一款网络爬虫框架,官方文档的描述如下:
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
以前写小型爬虫的话还可以自己写,用urllib,BeautifulSoup,Requests什么的就能解决了,后来我发现遇到一个新问题又得重新来一遍这些代码,又得去看前面是怎么写的,而且自己写容易怎么高兴怎么来,代码写的太乱,不好维护,过段时间再来看又要花时间才能看懂。
用框架的好处就是代码结构清晰,代码重用,不用对新的问题又重新来一遍代码,而且功能更强大,能快速解决自己手写代码所不能短时间解决的问题。
平台
- Windows 8.1
- Python 2.7.10
- 简书
Scrapy安装
Scrapy完美支持Python 2.x,虽然现在已经慢慢在支持Python 3.x了,但是可能还会遇到不少情况。我刚开始学习Scrapy想用Python 3.5的,都安装好了,但是运行的时候还是有引包错误:
ImportError: cannot import module '_win32stdio'
搜了一些,也没有解决,而且后面可能还会有很多问题,就暂时等一等它们的更新吧,先用回2.7,解决问题再说。
(By the way,看到了下面这个)

在Windows,Python 3.x下不能简单的 pip install scrapy 来一条龙安装scrapy,因为中间会出一些错误。
我参考了 【1】 以及 【2】 ,采用安装wheel文件的方式极其有效。
Python 3.5下Scrapy安装步骤:
1.安装Python,这个不说了
2.去 http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml 下载合适你的Python版本的lxml的wheel文件,我下载的是 lxml-3.4.4-cp35-none-win32.whl ,下载3.6.0版本好像不得行,在我的平台上报错:
lxml-3.6.0-cp35-cp35m-win32.whl is not a supported wheel on this platform ,不支持我的平台。
下载完后,将whl文件拷贝到Python安装目录下,然后cmd进入到你的Python安装目录,运行
pip3 install lxml-3.4.4-cp35-none-win32.whl
然后运行:
pip3 install scrapy
在cmd中输入scrapy,如果输出版本信息并没有报错,那么恭喜你,搞定了,是不是很爽!
Python 2.7下Scrapy的安装
Python2.7下直接 pip install scrapy ,如果报错,看报错的内容是什么,找出问题出在哪个依赖包上,在网上搜索该包的whl文件(符合版本),直接pip install whl文件 来安装就好了。我是问题处在twisted包上,所以去网上下载了老版本的twisted安装的。
开始项目
项目目的
我们将所学的马上利用到实际问题中来。[5]
爬取简书首页文章的打赏描述和打赏数,以企获得打赏描述对打赏数的影响
其实打赏数这个东西和文章的质量是最相关的,但是通过大量数据的挖掘统计,是否能将这种相关性弱化一下,从而显露出打赏描述和打赏数的关系呢?这就有趣了,值得研究。而且还可以同时学习框架和做有趣的事,岂不是人生一大乐趣。
创建Scrapy项目
通过如下语句创建Scrapy项目:
scrapy startproject jianshu2
然后会生成一个目录jianshu,目录结构如下:
jianshu/
scrapy.cfg
jianshu/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
- spiders目录存放主爬取代码,是整个项目的核心。需要在spider下自己新建自己的爬取程序。
- scrapy.cfg是项目的配置文件。
- settings.py是项目的设置文件。
- items.py定义我们要爬取的字段信息。
- pipelines.py是项目的管道文件。
定义items.py
首先定义我们需要爬取的字段:
# -*- coding: utf-8 -*-
import scrapy
class Jianshu2Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = scrapy.Field()
likeNum = scrapy.Field()
编写真正的Spider主爬程序
import scrapy
class postSpider(scrapy.spiders.Spider):
name = 'post'
start_urls = ['http://www.jianshu.com']
def parse(self, response):
articles = response.xpath('//ul[@class="article-list thumbnails"]/li')
for article in articles:
url = article.xpath('div/h4/a/@href').extract()
likeNum = article.xpath('div/div/span[2]/text()').extract()
print(url,likeNum)
然后试着运行:
scrapy crawl post
来运行我们的爬虫,中间又报了一次”No module named win32api”错误,直接pip install pypiwin32即可。
然后可以看到正确运行了,爬取了20篇文章后,爬虫自动停止,cmd中打印正常。
中间用到了XPath来解析HTML,找到元素具体的位置,我们找到首页的HTML的第一篇文章:

articles = response.xpath('//ul[@class="article-list thumbnails"]/li')
这句找到所有文章的HTML段,response是我们爬取时服务器返回的HTML。
我们看到所有文章都包含在 <ul class="article-list thumbnails"> 中,并且以 <li class=have-img> 开头,所以就不难理解XPath中为什么这么写了。
有BeautifulSoup基础的同学应该很好理解XPath了。
使用Item
我们爬取数据肯定不是为了打印出来看一下就算了,而是想要保存数据,一般来说,Spider爬取到数据之后通过items返回,还记得我们之前定义的items么,这时候就可以派上用场了。
写出完整代码:
import scrapy
from jianshu2.items import Jianshu2Item
class postSpider(scrapy.spiders.Spider):
name = 'post'
start_urls = ['http://www.jianshu.com']
def parse(self, response):
articles = response.xpath('//ul[@class="article-list thumbnails"]/li')
for article in articles:
url = article.xpath('div/h4/a/@href').extract()
likeNum = article.xpath('div/div/span[2]/text()').extract()
item = Jianshu2Item()
item['url'] = 'http://www.jianshu.com/'+url[0]
if likeNum == []:
#print(url,likeNum)
item['likeNum'] = 0
else:
#print(url,int(likeNum[0].split(' ')[-1]))
item['likeNum'] = int(likeNum[0].split(' ')[-1])
yield item
执行 scrapy crawl post -o items.json 就把数据保存到json中了。
yield 语句提交item。
注意打赏有可能没有,所以span也没有,这里判断一下。
数据如下:
[
[
{"url": "http://www.jianshu.com//p/6d7bf7d611aa", "likeNum": 1},
{"url": "http://www.jianshu.com//p/e47d86ce78d4", "likeNum": 0},
{"url": "http://www.jianshu.com//p/e69606806d6c", "likeNum": 0},
{"url": "http://www.jianshu.com//p/d7159874c59c", "likeNum": 2},
{"url": "http://www.jianshu.com//p/d38e8074ae94", "likeNum": 0},
{"url": "http://www.jianshu.com//p/6c8a0d0447cd", "likeNum": 0},
{"url": "http://www.jianshu.com//p/beff4ff80b25", "likeNum": 0},
{"url": "http://www.jianshu.com//p/d7e626cf02d7", "likeNum": 0},
{"url": "http://www.jianshu.com//p/524b13db9ce3", "likeNum": 1},
{"url": "http://www.jianshu.com//p/39449bcf9c28", "likeNum": 0},
{"url": "http://www.jianshu.com//p/970412b3c34d", "likeNum": 0},
{"url": "http://www.jianshu.com//p/2f98170f6eda", "likeNum": 1},
{"url": "http://www.jianshu.com//p/e91ab8e7a517", "likeNum": 0},
{"url": "http://www.jianshu.com//p/59a6caf3d965", "likeNum": 1},
{"url": "http://www.jianshu.com//p/ee5432e57dd3", "likeNum": 0},
{"url": "http://www.jianshu.com//p/00b7662bd335", "likeNum": 0},
{"url": "http://www.jianshu.com//p/1815b4071362", "likeNum": 1},
{"url": "http://www.jianshu.com//p/b00f7a2f0295", "likeNum": 0},
{"url": "http://www.jianshu.com//p/7f5fc5a01b75", "likeNum": 0},
{"url": "http://www.jianshu.com//p/84c10f2cf100", "likeNum": 0}
]
我们想将数据直接存在CSV这样的文件中怎么办呢?方法就是使用 Feed exports ,在settings.py文件中添加:
FEED_URI=u'D:/Python27/jianshu2/jianshu2/spiders/data.csv'
FEED_FORMAT='CSV'
第一次运行 scrapy crawl post -o data.csv ,然后后面不用加-o data.csv,即可输出到data.csv中。
获取求打赏声明
我们已经获得了url和打赏数,这已经是一个巨大的进步了。
然而我们还需要根据这个url再进一步爬到文章里面去,并且我们希望在一个爬虫里面就解决了,不想搞很多爬虫。
这时候问题转化为: 如何爬取需要的属性在不同页面的items?
这时候我们加一个属性’quote’,这个属性在打开url的页面中。
这时候,看到 这里 ,仿照它的写法,通过meta传递item参数,即相当于
主函数先确定一些参数(‘url’,’likeNum’),剩下的交给另一个函数去做,然后另一个函数算出’quote’参数后把item还给主函数,主函数整合一下item,然后yield生成就好了。
部分代码:
request = Request(posturl,callback=self.parse_donate)
request.meta['item'] = item
yield request
...
def parse_donate(self, response):
donate = response.xpath('//div[@class="support-author"]/p/text()').extract()
item = response.meta['item']
if len(str(donate)) == 0:
item['quote'] = ""
else:
item['quote'] = str(donate[0].encode('utf-8'))
return item
爬取多页
这时候我们发现爬的太少了,只有20篇。又看到首页下面有一个【点击查看更多】按钮,我们试着在代码中‘按下’这个按钮,然后获取下面内容的url,递归调用parse即可添加更多的文章。
next_link = selector.xpath('//*[@id="list-container"]/div[@class="load-more"]/button/@data-url').extract()[0]
if next_link:
next_link = self.url + str(next_link)
yield Request(next_link,callback=self.parse)
通过Pipeline写入json文件
有了item之后,item会被传递给Item Pipeline,我们可以在pipelines.py中对item做一些操作。
Item Pipeline的典型应用如下,更多见中文文档。
- 清洗HTML数据
- 验证item中的数据
- 查重或者丢弃
- 保存结果到文件(json,数据库,csv等)
于是我们编写pipelines.py如下:
import json
import codecs
class Jianshu2Pipeline(object):
def __init__(self):
self.file = codecs.open('items.json','wb','utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "/n"
self.file.write(line.decode("unicode_escape"))
return item
不得不用codecs来解决编码问题。Python在Windows下的编码真让人头疼。
这时候我们写道json中,其实url都可以去掉了,我们并不关心。
效果如下:
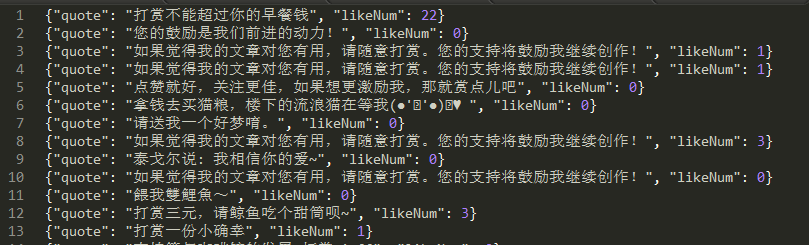
合并打赏描述,根据打赏数排序
修改pipelines.py文件,用一个全局的字典dict记录每种语句的打赏数之和,然后根据打赏数排序,写到新的csv文件中。
# -*- coding: utf-8 -*-
import json
import codecs
from operator import itemgetter
class Jianshu2Pipeline(object):
def __init__(self):
self.file = codecs.open('items.json','wb','utf-8')
self.quote = {}
self.filecsv = codecs.open('items.csv','w','utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "/n"
self.file.write(line.decode("unicode_escape"))
if item['quote'] in self.quote.keys():
self.quote[item['quote']] += item['likeNum']
else:
self.quote[item['quote']] = item['likeNum']
self.filecsv.seek(0)
lis = sorted(self.quote.items(),key=itemgetter(1),reverse=True)
for i in range(len(lis)):
line2 = lis[i][0] + '/t' + str(lis[i][1]) + '/r/n'
self.filecsv.write(line2.decode("utf-8"))
return item
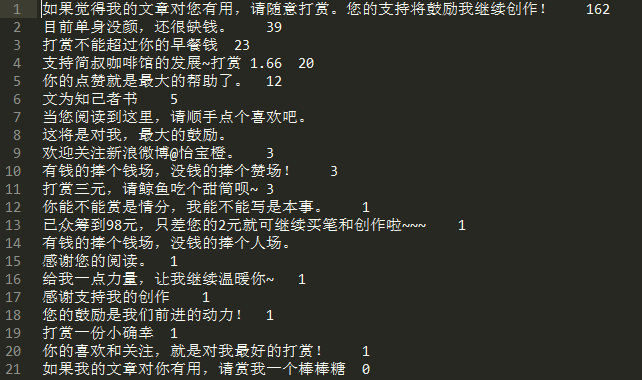
结语
由结果可以看出,第一条打赏数最多,不难理解,因为这句是默认的打赏描述,所以使用的基数很大,所以不能说明什么。由于数据量太少,只能爬6页,所以还不是很能说明问题。但是学习scrapy,了解scrapy的目的已经初步达到了,虽然还只是初步学习。但是找出统计上相对能够吸引人打赏的描述的目的还没有达到,需要加大数据量。
由结果还可以看出,其实打赏描述的个性化挺强的,很多都是个人信息。所以呢,还是要大数据。
查看源码点击进入我的Github: 本文源码
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

