中国Spark技术峰会见闻
来自腾讯广点通的同学介绍了Spark Streaming在广点通上的应用。该分享重点介绍了Spark Streaming的几个特性及其针对性的应用,包括excatly-once保证、可靠状态和快速batch调度三个特性。
其中exactly-once特性对于广告计费和反作弊这种对一致性要求很高的场景非常的合适,可以让使用者专心于业务,而不用操心数据是否一致。而由于可靠状态特性的存在,使得我们可以将一个业务放心地根据需要分批次(batch)做处理,而不用担心批次之间的聚合一致性问题,该特性将广点通原本实现复杂的微额记账功能大大简化了。最后介绍了一个利用Spark Streaming进程常驻特点来进行快速调度的特性,巧妙地绕过了MapReduce一级调度时无法规避的overhead和最小时间间隔限制,将调度间隔从10分钟减少到了秒级别,提高了调度的灵活性。
此外广点通的演讲还介绍了一些实战得来的Spark优化经验,包括内存限流,无编译增加特性,尽量使用SparkSQL替代RDD,以及远程调试等等。
新浪微博
来自新浪微博的同学介绍了Spark在微博feed排序中的应用,该演讲介绍了在当下火热的feed排序场景中如何使用Spark来提升效率,解决问题。微博Feed排序是一个典型的推荐+机器学习应用,其主要流程可简单分为以下几部分:
候选物料生成和召回
排序模型训练
训练样本、特征实时抽取收集。
模型训练。
排序模型预测
预测样本、特征实时抽取。
模型预测。
具体可见下图:
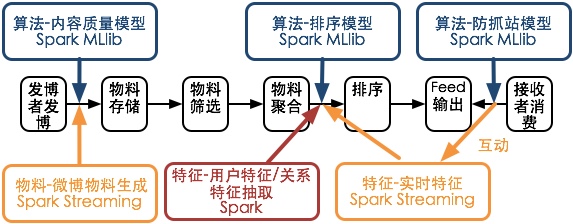
可以看出,在整个流程中,很多地方都可以使用Spark来进行处理,其中Spark MLLib中的各种算法可以用来做召回和模型训练,Spark Streaming可以用来做实时的特征处理和物料生成。可以说Spark和这样一个应用框架是非常的契合,如果算上家族里的Hadoop和HDFS,几乎可以渗透到流程中的每一个环节。而这一切并非偶然,参考该次大会上的其他分享演讲,我们有理由相信,这种紧贴大数据+机器学习应用的特性风格,是Spark一个刻意努力的发展方向。
此外该演讲还介绍了Spark Streaming与Storm这两个实施大数据分析平台的差异:
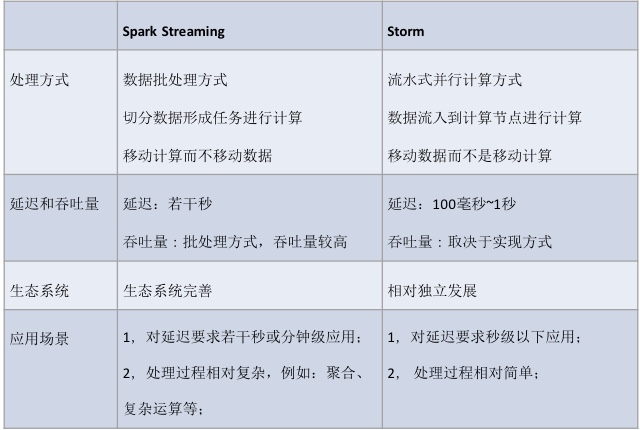
从这些对比中,可以大致得出如下结论:Storm适用于延迟要求高而计算逻辑简单的应用,例如之前春节时大家见到的春运地图;而Spark Streaming更适用于对延迟要求没那么高,但是计算逻辑较复杂,对一致性要求较高的应用,典型的如广告计费系统和大规模机器学习系统。当然Spark Streaming还有一个明显的优势就是与Spark&Hadoop生态圈的无缝结合,使得数据依赖和复杂流程的问题可以更好地得到解决。
AdMaster
AdMaster介绍了他们对Spark、Yarn和Elasticsearch的应用实践。Spark应用方面,介绍了实时数据监控的案例,可以做到13万个事件/秒的处理能力,但是要充分发挥Spark的计算能力,需要对Kafka等上游系统和Spark本身都做针对性调优,例如将数据尽量打散,以及使用网卡独占一个CPU等等。此外还介绍了使用Spark和Elasticsearch做跨屏分析的案例,使用Spark将通过多种数据源(微博、微信、新闻、论坛等),多种方式(流式、实时、离线)汇总来的海量数据进行聚合、处理、分析,之后用Spark来进行NLP和机器学习等算法服务,用Elasticsearch来提供数据分析和报表服务。
值得注意的是,Spark/Hadoop和Elasticsearch的结合使用的模式已经渐渐浮现,多个演讲中都进行了针对性的分析,典型的分工就是用Spark/Hadoop来进行复杂计算,而用Elasticsearch来进行分析和报表服务。
小结
通过以上几家公司的分享不难看出,Spark已经成为大数据处理,尤其是广告、推荐这样的复杂逻辑大数据处理应用的事实标准平台,尤其是在Spark Streaming被引入之后,Spark已经可以渗透到大数据处理的各个环节中,连同其他生态伙伴一起逐渐重塑着大数据处理的行业标准流程。
Spark功能/性能增强
来自Databricks和Hortonworks的几位技术专家分别介绍了Spark的若干更新和改进,改进涵盖了Yarn,Dataset,机器学习库以及实时计算等多个方面,代表了Spark未来版本的发展方向。
Yarn
虽然Mesos等其他调度工具都可以用来调度管理Spark,但是Yarn无疑是目前最为广泛使用的,某种程度上也算是一种事实标准了。来自Hortonworks的工程师在本次大会上介绍了用Yarn来管理Spark的若干优势,包括:
基于CGroups的容器资源隔离技术,该技术可以阻止某些应用占据过多的CPU资源,导致其他应用无法正常运行。
Yarn支持基于label的指定调度,通过label的方式将节点和应用进行匹配,可以让某些应用运行在指定的节点上,例如可以将计算密集的作业指定到高性能机器上去运行。
Yarn支持根据应用的运行情况来动态分配资源,减少资源浪费,例如一些长期运行的Spark Shell可以在其不活跃的时候减少其Executor资源占用。此外Yarn还可以根据数据存放位置来尽量将计算资源分配到数据存储所在的节点,虽然只是一种best-effort的方式,仍然可以通过减少数据移动来加快计算速度。
通过Yarn调度的任务在ResourceManager或NodeManager重启/失败后都可以自动恢复,这极大地增强了Spark在异构集群环境下的健壮性。
其他特性。
Dataset
在Spark的早期版本中,RDD一直是程序操作的主要对象,所有的操作都是围绕RDD上定义的各种函数来进行的。这种自由度给了刚从Hadoop冗长的计算流程中解放出来的程序员们耳目一新的感觉,但是慢慢地RDD的问题也在不断曝露出来,例如:
RDD处理的数据多为非结构化数据,导致中间数据多为各种形式的tuple。
RDD上面的各种Lambda操作对Spark不可见,导致Spark无法优化运行效率。
RDD上的各种Map/Reduce操作常常不够直观,程序可读性差。
针对以上种种问题,Spark正在走一条“数据结构化”的转变道路,经历着“RDD->Spark SQL->DataFrames->Dataset”的道路,在这个链条上,数据渐渐从非结构化走向结构化,从弱类型走向强类型,运行效率也在随之逐步提高,因为Spark可以通过执行引擎对执行计划做细致的性能调优,就像DBMS里面的查询引擎一样。虽然结构化的数据约束在某些情况下会有不灵活的问题,但是相比较带来的巨大的效率提升,还是建议大家尽量把数据往结构化的方向上靠拢,已换取更高的运行效率。数据结构化和类型安全带来的另一个好处,就是很多问题可以在编译期进行检查,避免了程序运行一段时间忽然崩溃的问题,这对开发效率来讲无疑也是一种提升。具体差异可见下面两张图的对比。
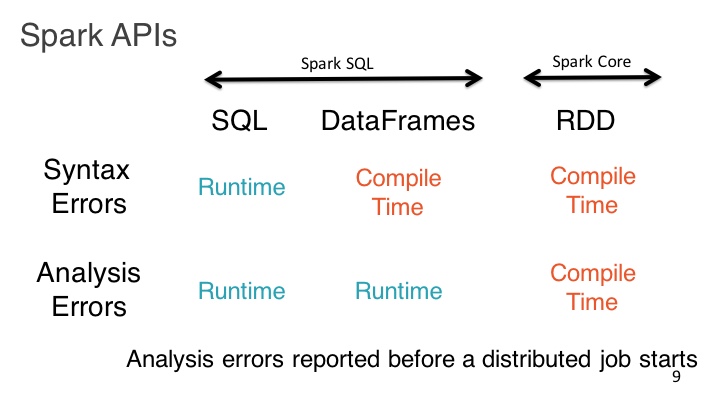
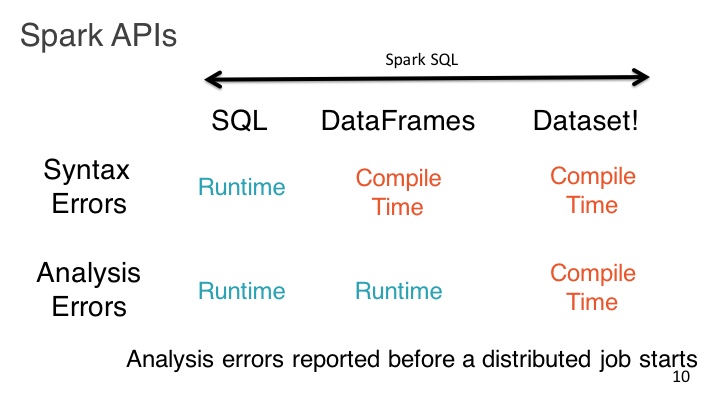
可以看出,Dataset是这个进化链条上最新的成果,根据Databricks工程师的说法,Dataset可以看做是“类型安全版本的DataFrame”,同时也是“结构化的RDD”。从这两个类比我们可以看出Spark正在通过加强对数据的约束来换取运行效率和安全性的提升。
机器学习库
大规模机器学习一直都是大数据的典型应用,因此人们对于Spark之上的机器学习工具库一直都抱有很高的期望和要求。本次大会上来自Hortonworks的工程师介绍了GLM(广义线性模型)在Spark中的支持和实现。
我们常用的线性回归和逻辑回归等模型,都可以归为GLM,从而可以使用同一套优化方法进行求解。除了线性回归和逻辑回归这两个常用模型以外,还有很多问题都可以抽象为GLM,具体可见下表:
ModelDistributionLink
linear regressiongaussianidentity, log, inverse
logistic regressionbinomiallogit, probit, cloglog
poisson regressionpoissonlog, identity, sqrt
gamma regressiongammainverse, identity, log
可以看出,通过定义不同的error distribution和link函数,可以在GLM的框架内构造出各种模型,从而可以用同一套优化方法来进行优化,例如梯度下降类方法、牛顿类方法等。Spark的机器学习库中包含了L-BFGS和OWL-QN的分布式实现,采用的是数据和模型同时分部式的结构,使得对海量数据模型的优化成为可能。如下所示,通过指定family(上表中的Distribution)和link function,就可以轻松得到一个GLM模型,之后一切可以方便的训练和预测模型了:
# Load training data
dataset = spark.read.format("libsvm").load("data/mllib/sample_linear_regression_data.txt")
test = dataset
glr = GeneralizedLinearRegression(family=“gaussian”, link=“identity”, maxIter=10, regParam=0.3)
# Fit the model
model = glr.fit(dataset)
# Make predictions by calling transform predictions = model.transform(test)
GLM最早的经典实现来自于R,R中方便的公式表示方法以及对参数的详细解读信息一直是R中最受欢迎的特性。现在R用户现在也可以通过SparkR中的GLM接口,像在R中一样使用公式,并且也能够得到R中一样的模型结果,具体如下:
df <- createDataFrame(sqlContext, iris)
model <- spark.glm(df, Sepal_Width ~ Sepal_Length + Species)
summary(model)
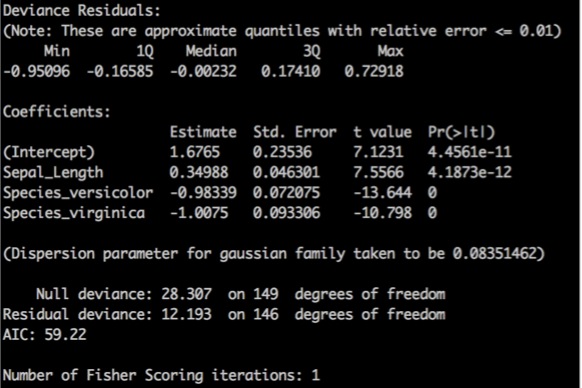
R的简洁语法和Spark的强大计算能力相结合,给R语言带来了第二春。
实时计算
Spark Streaming自从被引入到Spark以来,受到的重视和应用日渐增长,但是虽然人们对其应用场景的不断拓展,Spark Streaming也暴露出了一些问题。
一个典型的问题就是事件延迟,该问题指的是需要和其他数据做汇总的某个数据点在相隔很长时间之后才发送过来,导致的数据汇总不准确问题,例如我们在坐飞机前在使用一个APP,上了飞机之后关闭手机,下了飞机才将手机打开,这时手机上APP里的数据与上飞机之前的数据就会有一个比较大的延迟,导致一些计算不准确。
还有一个更大的问题,就是Spark Streaming应用往往都不是一个单独运行的程序,而是需要和很多数据源、计算资源进行频繁交互,而目前Spark Streaming对这类应用的支持还不够好。Databricks工程师在演讲中将这种应用叫做持续应用(Continuous Application),指的是持续运行的,并且在运行过程中需要频繁和其他系统交互的应用。
Spark对以上问题提出的解决方案是结构化流处理(Structured Streaming),其核心思想是用户不需要关心一个应用处理的究竟是静态数据还是动态的流数据,其示意图如下:
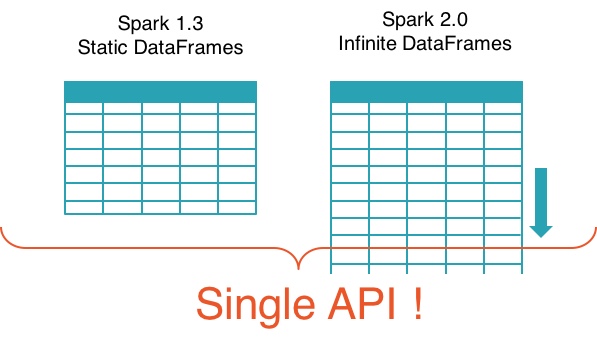
该技术通过将静态数据和动态数据进行统一抽象,并加入时间维度,使得程序员无需关心所处理的数据究竟是静态数据还是动态数据,简化了编程模型,也增强了复用性。用户可以通过简单的接口修改,使用同一套代码处理两种数据模式。这一思想显然是受到了Linux命令管道式设计的启发,Linux的很多命令,例如grep、sed、awk等,本身就可以无差异地处理静态文件和管道文件。
小结
从这几个演讲可以看出,Spark的发展是紧跟应用、紧跟需求的,发展的方向都是切实解决开发者实际问题的,和使用者形成了很好的反馈回路。相信这种“接地气”的发展方式一定会为Spark带来更多的用户和更广泛的应用。
总结
经过近年来的发展,Spark已经从单纯的取代部分Hadoop任务,发展到现在对大数据应用的无孔不入,已经成为了行业内的事实标准,并且自身也在以很快的速度不断发展着,未来可谓不可限量。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

