如何自己搭建钓鱼网站检测系统
0×01基本系统架构
随着电子商务、互联网金融的快速发展,在利益的驱使下,从事“钓鱼攻击”的黑产呈逐渐上升趋势。“钓鱼攻击”不仅对企业的品牌形象造成严重损害,还对用户的账户安全、甚至资金安全构成了极大的威胁。
目前“钓鱼攻击”已经为了网络欺诈的重要一环,因此反钓鱼系统在电子商务、金融证券、电信运营商等企业的安全运营中起着越来越重要的地位。
反钓鱼系统一般有如下两种架构。
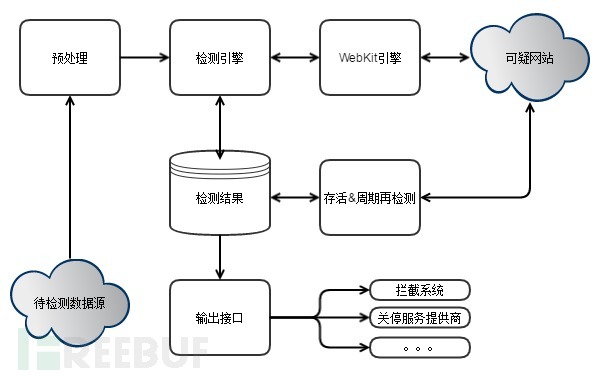
对于这种架构主要适用于缺乏终端控制力的企业。企业可以从各个渠道收集待检测的url,检测引擎调用利用WebKit引擎获取页面渲染后的有效内容,然后调用检测算法对页面内容进行检测。检测后将检测结果存至数据库,之后将检测结果输出至第三方的拦截系统、关停服务提供商等,最终遏制“钓鱼攻击”的发生。
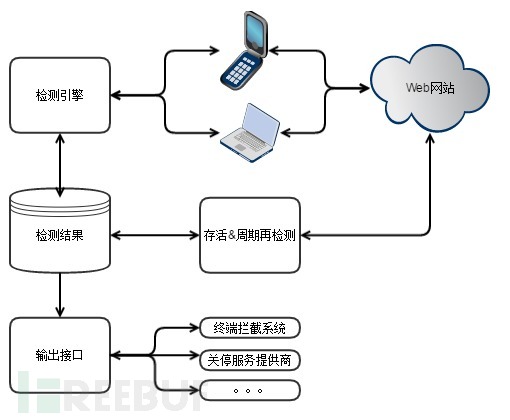
对于第二种架构,适用于拥有大量终端的企业,利用终端的能力代替了WebKit。终端直接将疑似页面的特征发回后端的检测引擎,检测引擎生成检测结果、产出黑名单,同时将检测结果的返回至终端。
0×02检测引擎
检测引擎做为反钓鱼系统的核心承担着识别页面是否为钓鱼网站的任务。针对钓鱼网站的检测手段主要有IP黑名单,url分析,域名注册信息分析,页面内容分析,图像识别等方法。
其中页面内容分析一直是钓鱼页面识别的主要手段。页面识别的主要算法有贝叶斯算法、机器学习算法、Html文档特征等算法。
下面介绍下如何使用贝叶斯算法进行页面识别。
贝叶斯算法简介
贝叶斯分类是一类分类算法的总称,是关于随机事件A和B的条件概率和边缘概率的一则定理。
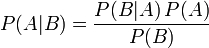
- P(A)是A的先验概率或边缘概率。之所以称为”先验”是因为它不考虑任何B方面的因素;
- P(A|B)是已知B发生后A的条件概率,也由于得自B的取值而被称作A的后验概率;
- P(B|A)是已知A发生后B的条件概率,也由于得自A的取值而被称作B的后验概率;
- P(B)是B的先验概率或边缘概率,也作标准化常量。
分类原理
我们用W来代表一个待分类的网页,用h+钓鱼网页,用h-代表正常网页。利用贝叶斯公式,判定页面是否为钓鱼网页可描述为:
- P(h+|W)=P(h+)*P(W|h+)/P(W)
- P(h-|W)=P(h-)*P(W|h-)/P(W)
P(W)为常量,可以暂时忽略。P(h+)、P(h-)为先验概率,即一个真实的网页集合中,钓鱼网页的比例与正常网页的比例。
为了求得P(W|h),我们可以将W进行分词,W={w1,w2,w3…}。如果我们假设w1,w2等是条件无关的,则P(W|h+)=P(w1|h+)*P(w2|h+)*P(w3|h+)。
P(wi|h+)经过Laplacean平滑处理后,P(wi|h+)=(1 + 特征词wi在h+训练集中的词频) / (全部特征词去重个数 + h+下所有词出现总数)。
这样我们便能计算出P(h+|W)与P(h-|W),比较大小可知页面属于哪一分类。
数据准备
为了获取待检测域名,我们可以从ICANN的Centralized Zone Data Service免费获取到全球的域名列表,做差量可得到全球的每日新增域名。之后将每日新增的域名导入到我们的待检测列表。
我们可以通过Python调用Phantomjs去获取页面中内容。
Phantomjs:
var webPage = require('webpage'); var system = require('system'); var page = webPage.create(); if (system.args.length === 1) { console.log("error"); phantom.exit(); } else { url = system.args[1]; page.open(url, function (status) { if (status == 'success') { var content = page.content; console.log(content); } else { console.log("error"); } phantom.exit(); }); }; Python:
def get_page_content(url): cmd = 'phantomjs getPageContent.js %s' % (url) stdout, stderr = subprocess.Popen(cmd, shell = True, stdout = subprocess.PIPE, stderr = subprocess.PIPE).communicate() return stdout 为了得到一个贝叶斯分类器,需要一个样本集对其进行训练。首先要对页面做打标分类,一类为钓鱼页面样本集,一类为正常页面样本集。样本集就是我们的原始训练素材。
建立模型
这里针对中文的钓鱼页面建立分类模型,我们先使用正则提取出原始页面中的中文字符。
def get_chinese_content(raw_page_content): content_list = re.findall(ur"[/u4e00-/u9fa5]+", raw_page_content) return "".join(content_list) 获取页面中文内容后,我们对其进行分词。
def get_seg_list(chinese_content): return jieba.cut(chinese_content) 有了基础数据后,就可以开始训练贝叶斯模型。我们需要一份停用词表,类似下面的无意义作为停用词,从样本集的分词结果中去掉。
一,一下,一个,一些,的,了,和,是,就,都,而,及,與,著,或,一何,一切...... 我们需要统计出在两个样本集中总共出现了多少个不同的词 all_unique_word_count。之后我们需要分别求出钓鱼样本集与正常样本集各自出现了多少词汇,all_phish_word_count, all_normal_word_count。
def count_all_unique_word(word_list): return len(set(word_list)) all_unique_word_count = count_all_unique_word(all_word_list) 接下来我们分别统计钓鱼网页样本集与正常网页样本集中各个词语的词频信息,phish_word_frenquency_dict, normal_word_frequency_dict。
def get_word_frequency(word_list): frequency_dict = dict() for w in word_list: if frequency_dict.has_key(w): frequency_dict[w] = frequency_dict[w] + 1 else: frequency_dict[w] = 1 return frequency_dict phish_word_frenquency_dict = get_word_frequency(phish_word_list) normal_word_frequency_dict = get_word_frequency(normal_word_list) 根据贝叶斯分类器原理推导的公式,可以计算出P(wi|h+)概率列表phish_word_probability_table与P(wi|h-)的概率列表normal_word_probability_table,这两个table就是贝叶斯模型的核心,需要保存下来。
def get_word_probability_table(word_frequency_dict, category_word_count, all_unique_word_count): probability_dict = dict() for key, value in word_frequency_dict.items(): probability_dict[key] = (1 + value) / (all_unique_word_count + category_word_count) return probability_dict phish_word_probability_table = get_word_probability_table(phish_word_frequency_dict, all_phish_word_count, all_unique_word_count) normal_word_probability_table = get_word_probability_table(normal_word_frequency_dict, all_normal_word_count, all_unique_word_count) P(h+)、P(h-)我们可以直接求出,即训练样本集中钓鱼网页数目与正常网页数目的比例probability_phish,probability_normal。
钓鱼检测
当有了训练好的模型后,只要获取了页面的内容,进行分词。查询phish_word_probability_table与P(wi|h-),计算出P(h+|W)与P(h-|W),比较大小,判定是否为钓鱼页面。
def analyse_page(raw_page_content, probability_phish, probability_normal, phish_word_probability_table, normal_word_probability_table): page_word_list = get_seg_list(get_chinese_content(raw_page_content)) p_phish = probability_phish p_normal = probability_normal for w in page_word_list: p_phish = p_phish * phish_word_probability_table[w] p_normal = p_phish * normal_word_probability_table[w] return True if p_phish > p_normal else False 0×03 策略、改进
“钓鱼攻击”者为了躲避反钓鱼系统的检测,常常采取屏蔽反钓鱼检测系统IP,屏蔽特定UA,页面使用js或flash进行动态渲染,全页面图片化等手段。
反钓鱼系统为了与之对抗,需要充分利用云端与终端的优势,突破钓鱼网站对检测系统的屏蔽,并采取动态渲染的方式加载js、flash获取页面内容。检测技术也从单一的文本分析进化到了大数据统计分析、机器学习分类算法、HTML特征、图像识别等手段,对可疑页面进行实时的分析。甚至是仅仅注册了钓鱼域名,钓鱼网站还未开通,就对高危域名做出了预判,对风险进行感知,以降低用户受到网络欺诈的风险。
*本文作者:阿里云誉反欺诈(企业帐号),转载须注明来自FreeBuf黑客与极客(FreeBuf.COM)
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

