手把手教你扩展个人微信号
现在的日常生活已经离不开微信,难免会生出微信有没有什么API可以使用的想法。
那样就可以拿自己微信做个消息聚合、开个投票什么的,可以显然没有这种东西。
不过还好,有网页版微信不就等于有了API么,这个项目就是出于这个想法出现的。
目标
看完这一系列教程,你就能从头开始实现自己关于微信以及类似工具的想法,例如一个 完善的微信机器人 。
当然,如果你只对使用微信的API感兴趣,可以直接跳到下一篇教程,直接使用我已经完成的 API 。
本文为该教程的第一部分,主要讲述抓包与伪造,将会以最简单的方法介绍使用Python模拟登陆抓取数据等内容。
Python与基本的网络基础都不困难,所以即使没有这方面基础辅助搜索引擎也完全可以学习本教程。
关于本教程有任何建议或者疑问,都欢迎邮件与我联系,或者在 github上提出 (i7meavnktqegm1b@qq.com)
教程流程简介
教程将会从如何分析微信协议开始,第一部分将教你如何从零开始获取并模拟扩展个人微信号所需要的协议。
第二部分将会就这些协议进行利用,以微信机器人为例介绍我给出的项目基本框架与存储、任务识别等功能。
第三部分就项目基本框架开发插件,以消息聚合等功能为例对框架做进一步介绍与扩展。
简单成果展示:
目前的样例微信号被扩展为了能够完成信息上传下载的机器人,用于展示信息交互功能。
其支持文件、图片、语音的上传下载,可以扫码尝试使用。

本部分所需环境
本文是这一教程的第一部分,需要配置抓包与Python环境。
本教程使用的环境如下:
-
Windows 8.1
-
Python 2.7.11 (安装Image, requests)
-
Wireshark 2.0.2
-
微信版本6.3.15
Wireshark配置
Wireshark是常见的抓包软件,这里通过一些配置抓取微信网页端的流量。
由于微信网页端使用https,需要特殊的配置才能看到有意义的内容,具体的配置见 这里 。
配置完成以后开始抓包,载入 https://www.baidu.com 后若能看到http请求则配置成功。
分析并模拟扫码,并获取登录状态
微信网页端登陆分为很多步,这里以第一步扫码为例讲解如何从抓包开始完成模拟。
分析过程
在抓包以前,我们需要先想清楚这是一个什么样的过程。
我们都登录过网页端微信,没有的话可以现在做一个尝试: 微信网页端 。
这个过程简单而言可以分为如下几步:
-
向服务器提供一些用于获取二维码的数据
-
服务器返回二维码
-
向服务器询问二维码扫描状态
-
服务器返回扫描状态
有了这些概念以后就可以开始将这四步和包对应起来。
对应过程与实际的包
开启wireshark抓包后登陆网页端微信,完成扫码登陆,然后关闭wireshark抓包。
筛选http请求(就是菜单栏下面输入的那个http),可以看到这样的界面。
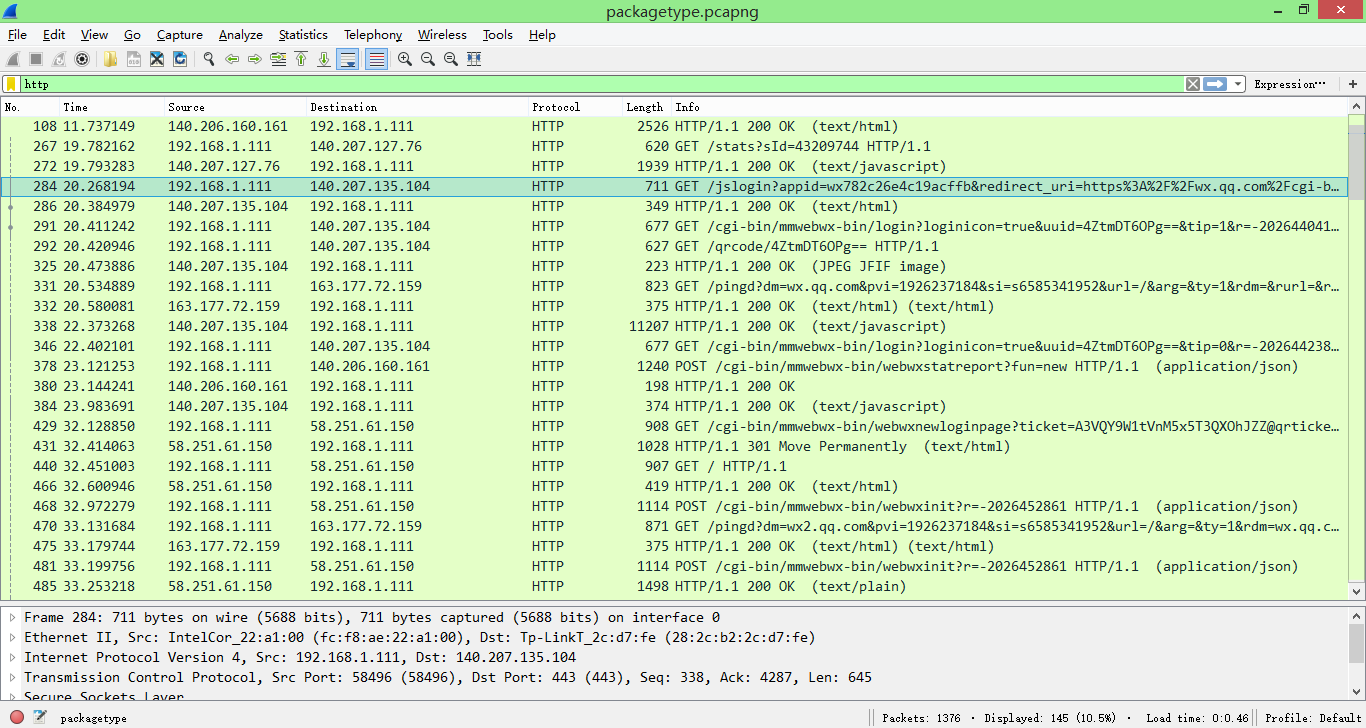
这里需要讲的就是第一列“No.”列的数字就是后文说的几号包,例如第一行就是30号包。数据包的类型则在Info列中可以看到,是GET,POST或是别的请求。
那么我们可以开始分析抓到的包了,我们先粗略的浏览一下数据包。
第325号包引起了我的注意,因为登陆过程当中非常有特征的一个过程是二维码的获取,所以我们尝试打开这一数据包的图片的内容。

325号包是由292号包的请求获取的,292号包又是一个普通的get请求,所以我们尝试直接在浏览器中访问这一网址。(访问自己抓到的网址)
具体的网址通过双击打开292号包即可找到。如需要可以点击 这里 看图。
我们发现直接在浏览器中获取了一张二维码,所以这很有可能就是上述一、二步的过程了。
那么我们是向服务器提供了哪些数据获取了二维码呢?
-
每次我们登录的二维码会变化,且没有随二维码传回的标识,所以我们肯定提供了每次不同的信息
-
网址中最后一部分看起来比较像标识: https://login.weixin.qq.com/qrcode/4ZtmDT6OPg==
-
为了进一步验证猜想,再次抓包,发现类似292号包的请求url仅最后一部分存在区别
-
所以我们提供了
4ZtmDT6Opg==获取到了这一二维码。
那么这一标识是随机生成的还是服务器获取的呢?
-
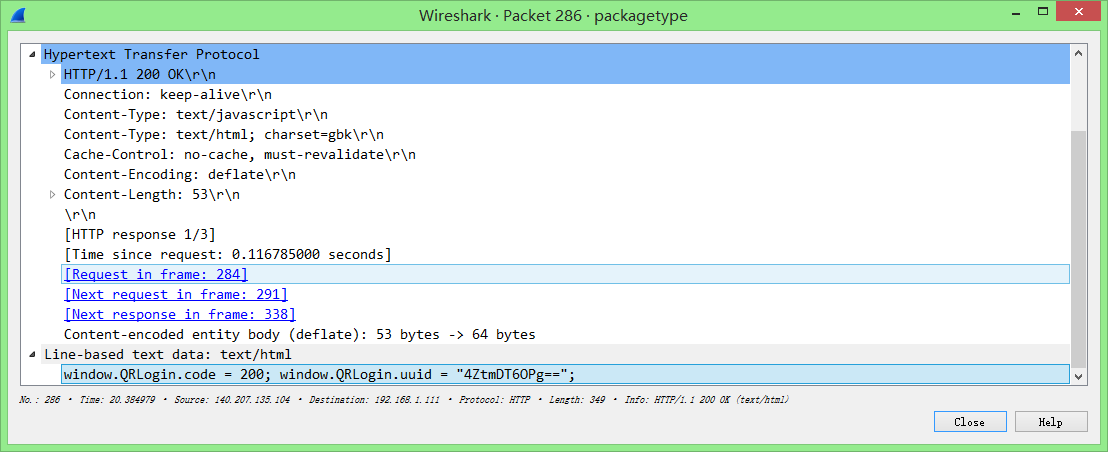
从最近的包开始分析服务器传回的数据(Source是服务器地址的数据),发现就在上一行,286号包有我们感兴趣的数据。
-
打开这个包,可以看到其返回的数据为
window.QRLogin.code = 200; window.QRLogin.uuid = "4ZtmDT6OPg==";(见下方截图) -
显然导致服务器返回这一请求的284号包就是我们获取标识(下称uuid)所需要伪造的包。
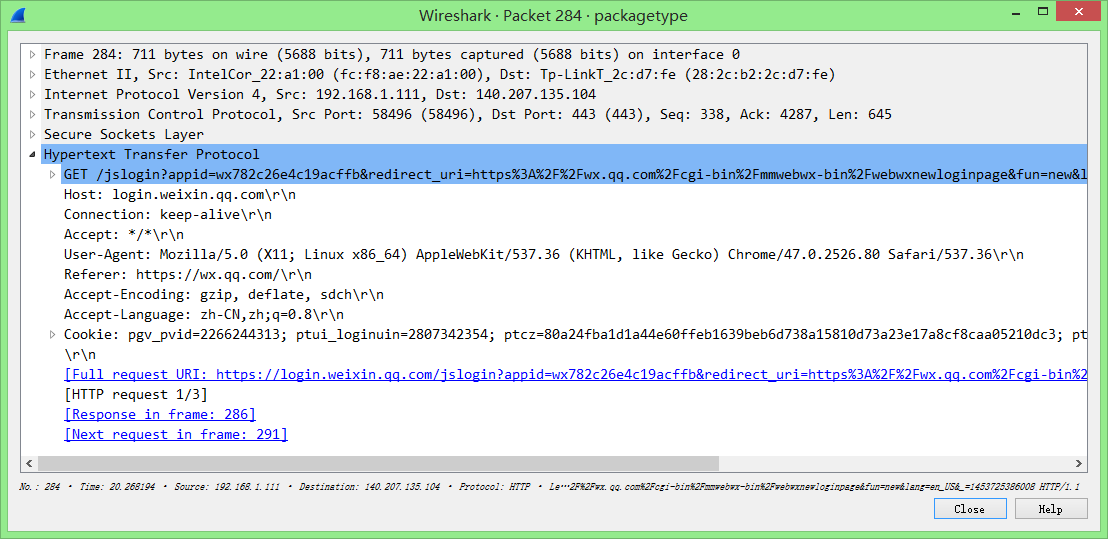
那么284号包需要传递给服务器哪些数据?
-
这是一个get请求,所以我们分析其请求的url:
https://login.weixin.qq.com/jslogin?appid=wx782c26e4c19acffb&redirect_uri=https%3A%2F%2Fwx.qq.com%2Fcgi-bin%2Fmmwebwx-bin%2Fwebwxnewloginpage&fun=new&lang=en_US&_=1453725386008。 -
可以发现需要给出五个量
appid, redirect_uri, fun, lang, _。 -
其中除了appid其余都显然是固定的量(_的格式显然为时间戳)。
-
然而搜索284号包之前的包也没有发现这一数值的来源,所以暂且认为其也是固定的量,模拟时如果出现问题再做尝试。
到了这里,1,2步的过程我们已经能够对应上相应的包了。
3,4部的最显著特征是在扫描成功以后会获取扫描用的微信号的头像。
我们还是首先大致的浏览一下服务器返回的数据包,试图找到包含图片的数据包。
-
从325号包(微信头像肯定在二维码之后获取)开始浏览。
-
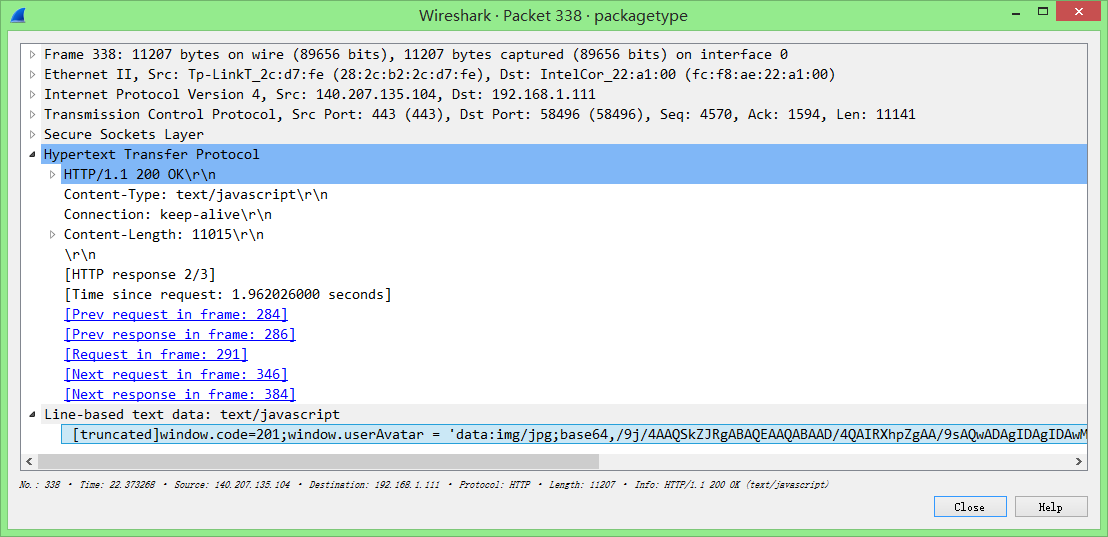
我们发现338号包中包含一个base64加密的图片, 解压 后可以看到自己的头像。
-
所以这个数据包就是服务器返回的扫描成功的数据包了,而前面那部分
window.code=201显然就是表示状态的代码。(见下方截图) -
经过尝试与再次抓包,我们理解状态码的涵义:
200:登陆成功 201:扫描成功 408:图片过期 -
那么第四部我们已经能够完全的理解
我们很容易的找到了在登录过程当中不断出现的请求,那么要怎么模拟呢?
-
首先这是一个简单的get请求,url为: https://login.weixin.qq.com/cgi-bin/mmwebwx-bin/login?loginicon=true&uuid=4ZtmDT6OPg==&tip=1&r=-2026440414&_=1453725386009
-
可以发现需要给出五个量
loginicon, uuid, tip, r, _ -
通过多次抓包发现除了r以外都可以找到简单的规律,那么r的规律等待模拟时再尝试处理
至此你应该已经能将四个过程全部与具体的数据包对应。为了避免有遗漏的过程,我们将没有使用到的与服务器交互的数据包标识出来(右键Mark)。经过简单的浏览,认为其中并没有必须的数据包交互。但值得注意的是,如果之后模拟数据包没有问题却无法登陆的话应当再回到这些数据包中搜寻。
这里做一个简单的小结,这一部分简单的介绍了分析数据包的基本思路,以及一些小的技巧。当然这些仅供参考,在具体的抓包中完全可以根据具体的交互过程自由发挥。而目前留下来的问题有:第一步时的appid与第三步时的r,留待模拟时在做研究。
使用Python模拟扫码
这一部分我们使用python的requests模块,可以通过 pip install requests 安装。
我们先来简单的讲述一下这个包。
import requests # 新建一个session对象(就像开了一个浏览器一样) session = requests.Session() # 使用get方法获取https://www.baidu.com/s?wd=python url = 'https://www.baidu.com/s' params = { 'wd': 'python', } r = session.get(url = url, params = params) with open('baidu.htm') as f: f.write(r.content) # 存入文件,可以使用浏览器尝试打开 # 举例使用post方法 import json url = 'https://www.baidu.com' data = { 'wd': 'python', } r = session.get(url = url, data = json.dumps(data)) with open('baidu.htm') as f: f.write(r.content) # 以上代码与下面的代码不连续如果想要更多的了解这个包,可以浏览 requests快速入门 。
你可以尝试获取一个你熟悉的网站来测试使用requests,在测试时可以打开抓包,查看你发送的数据包与想要发送的数据包是否一样。
那么我们开始模拟第一、二个过程,向服务器提供一些用于获取二维码的数据,服务器返回二维码。
-
向服务器提交284,292号包
-
从服务器返回数据中提取出uuid与二维码图片
284号包
我们需要模拟的地址为: https://login.weixin.qq.com/jslogin?appid=wx782c26e4c19acffb&redirect_uri=https%3A%2F%2Fwx.qq.com%2Fcgi-bin%2Fmmwebwx-bin%2Fwebwxnewloginpage&fun=new&lang=en_US&_=1453725386008 ,所以我们模拟的代码如下:
#coding=utf8 import time, requests session = requests.Session() url = 'https://login.weixin.qq.com/jslogin' params = { 'appid': 'wx782c26e4c19acffb', 'redirect_uri': 'https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxnewloginpage', 'fun': 'new', 'lang': 'en_US', '_': int(time.time()), } r = session.get(url, params = params) print('Content: %s'%r.text)当然,将模拟的地址全部写在url里面效果完全一样。
值得一提的是requests会帮我们自动urlencode,如果不需要urlencode(/变为了%2F)可以将所有内容都写在url里面。
提取出uuid
这里使用re,如果不了解正则表达式的话可以直接拿来用,毕竟和这一个教程并不相关。
# 上接上一段程序 import re regx = r'window.QRLogin.code = (/d+); window.QRLogin.uuid = "(/S+?)";' # 我们可以看到返回的量是上述的格式,括号内的内容被提取了出来 data = re.search(regx, r.text) if data and data.group(1) == '200': uuid = data.group(2) print('uuid: %s'%uuid)如果没能成功获取到uuid可以尝试再运行一次。
292号包
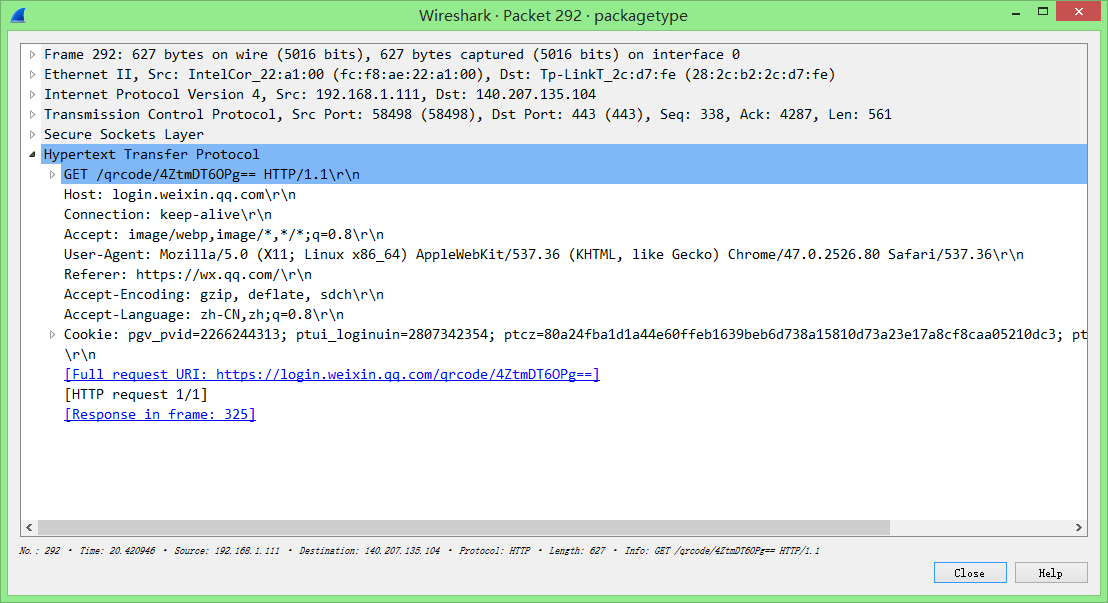
我们需要模拟的url为: https://login.weixin.qq.com/qrcode/4ZtmDT6OPg== ,所以我们模拟的代码如下:
# 上接上一段程序 url = 'https://login.weixin.qq.com/qrcode/' + uuid r = session.get(url, stream = True) with open('QRCode.jpg', 'wb') as f: f.write(r.content) # 现在你可以在你存储代码的位置发现一张存下来的图片,用下面的代码打开它 import platform, os, subprocess if platform.system() == 'Darwin': subprocess.call(['open', 'QRCode.jpg']) elif platform.system() == 'Linux': subprocess.call(['xdg-open', 'QRCode.jpg']) else: os.startfile('QR.jpg') 由于我们需要获取图像,所以需要以二进制数据流的形式获取服务器返回的数据包,所以增加 stream = True 。
而将二进制数据流写入也需要在打开文件时设定二进制写入,即 open('QRCode.jpg', 'wb') 。
当然,如果获取失败可以再运行一次。
同理的三、四步也可以按照这个方法写出,这里就不再赘述,只给出代码。
而经过测试我们发现,第一步时的appid实际是一个固定的量,第三步时的r甚至不输入也可以登录。
# 上接上一段代码 import time while 1: url = 'https://login.weixin.qq.com/cgi-bin/mmwebwx-bin/login' # 这里演示一下不使用自带的urlencode params = 'tip=1&uuid=%s&_=%s'%(uuid, int(time.time())) r = session.get(url, params = params) regx = r'window.code=(/d+)' data = re.search(regx, r.text) if not data: continue if data.group(1) == '200': # 下面一段是为了之后获取登录信息做准备 uriRegex = r'window.redirect_uri="(/S+)";' redirectUri = re.search(uriRegex, r.text).group(1) r = session.get(redirectUri, allow_redirects=False) redirectUri = redirectUri[:redirectUri.rfind('/')] baseRequestText = r.text break elif data.group(1) == '201': print('You have scanned the QRCode') time.sleep(1) elif data.group(1) == '408': raise Exception('QRCode should be renewed') print('Login successfully')当你看到 Login successfully 时,说明至此我们已经成功从零开始,通过抓包分析,用python成功模拟了python登陆。
不过是不是看上去没有什么反馈呢?那是因为我们还没有模拟会产生反馈的包,但其实差的只是研究发文字、发图片什么的包了。
为了体现我们已经登陆了,加上后面这段代码就可以看到登陆的账号信息:
# 上接上一段代码 import xml.dom.minidom def get_login_info(s): baseRequest = {} for node in xml.dom.minidom.parseString(s).documentElement.childNodes: if node.nodeName == 'skey': baseRequest['Skey'] = node.childNodes[0].data.encode('utf8') elif node.nodeName == 'wxsid': baseRequest['Sid'] = node.childNodes[0].data.encode('utf8') elif node.nodeName == 'wxuin': baseRequest['Uin'] = node.childNodes[0].data.encode('utf8') elif node.nodeName == 'pass_ticket': baseRequest['DeviceID'] = node.childNodes[0].data.encode('utf8') return baseRequest baseRequest = get_login_info(baseRequestText) url = '%s/webwxinit?r=%s' % (redirectUri, int(time.time())) data = { 'BaseRequest': baseRequest, } headers = { 'ContentType': 'application/json; charset=UTF-8' } r = session.post(url, data = json.dumps(data), headers = headers) dic = json.loads(r.content.decode('utf-8', 'replace')) print('Log in as %s'%dic['User']['NickName'])这里做一个简单的小结:
-
模拟数据包总体而言是以寻找未知的必须数据为线索,辅助一些技巧,串联起整个过程。
-
首先需要用python初始化一个session,否则登录过程的存储将会比较麻烦。
-
模拟数据包的时候首先区分get与post请求,对应session的get与post方法。
-
get的数据为url后半部分的内容,post是数据包最后一部分的内容。
-
get方法中传入数据的标示为params, post方法中传入数据的标示为data。
-
session的get,post方法返回一个量,可以通过r.text自动编码显示。
-
存储图片有特殊的方式与配置。
小结
到现在为止我展示了一个完整的抓包、分析、模拟的过程完成了模拟登陆,其他一些事情其实也都是类似的过程,想清楚每一步要做些什么即可。
这里用到的软件都只介绍了最简单的一些方法,进一步的内容这里给出一些建议:
-
wireshark可以直接浏览官方文档,有空可以做一个了解。
-
requests包的使用通过搜索引擎即可,特殊的功能建议直接阅读源码。
那么做一个小练习好了,测试一下学到的东西:读取命令行的输入并发送给自己。(这部分的源码放在了文末)
-
在分析包的过程中记得抓好位置的必要数据这个线索,练习之前提到过的一些技巧。
-
把大的过程拆分成一个一个小的任务可能会让分析简单很多。
-
如果发现登录过程意料之外的断了,分析不出原因,可以尝试多抓几次包再比较分析。
具体运用时可能遇到的难点
命令行登录一段时间后无法与服务器正常交互
这是因为微信网页端存在心跳机制,一段时间不交互将会断开连接。
另外,每次获取数据时(webwxsync)记得更新SyncKey。
某个特定请求不知道如何模拟
在项目中已经模拟好了几乎所有的请求,你可以通过参考我的方法与数据包。
如果之后微信网页版出现更新我会在本项目中及时更新。
项目中的微信网页端接口见 这里
无法上传中文文件名的文件与图片
这是因为使用requests包会自动将中文文件名编码为服务器端无法识别的格式,所以需要修改requests包或者使用别的方法上传文件。
最简单的方法即将requests包的packages/urlib3中的fields.py中的 format_header_param 方法改为如下内容:
def format_header_param(name, value): if not any(ch in value for ch in '"///r/n'): result = '%s="%s"' % (name, value) try: result.encode('ascii') except UnicodeEncodeError: pass else: return result if not six.PY3: # Python 2: value = value.encode('utf-8') value = email.utils.encode_rfc2231(value, 'utf-8') value = '%s="%s"' % (name, value.decode('utf8')) return value登录时出现不安全的提示
建议更新Python版本至2.7.11
小练习答案
源码可在该地址下载: 这里
结束语
希望读完这篇文章能对你有帮助,有什么不足之处万望指正(鞠躬)。
有什么想法或者想要关注我的更新,欢迎来 Github 上 Star 或者 Fork 。
160426
LittleCoder
EOF
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

