度量认知服务性能

Stefan van der Stockt
认知数据科学家,IBM Watson

Anna Chaney
认知架构师,IBM Watson

Alex Block
认知解决方案工程师,|IBM Watson

Tom Wall
Watson 原型工程师,IBM Watson
认知系统(比如机器学习系统)的好坏取决于用于训练它们的数据质量。认知系统使用精心设计(有时高度复杂)的人工智能算法来训练系统。更糟的是,有无数的认知服务 — 我们如何掌握每种服务在不同操作场景中的工作情况?幸运的是,通过将认知系统视为 黑盒 ,可以度量和理解认知系统的行为。就像您无需准确知道发动机的工作原理也能驾驶汽车一样,无需准确知道算法的工作原理就能训练出良好的认知系统。
IBM Watson Annotation Assist 是一个开源的 Web 应用程序,用于对认知系统对人类的响应提供几乎零接触的评估。在本教程中,学习如何在 IBM Bluemix™ 上创建和使用一个 Annotation Assist 实例,迭代式地训练和评估认知系统性能。
认知开发周期
开发人员采用的方法一定要能让他们:
- 启动(“引导”)和部署认知系统
- 收集用户与系统的交互数据
- 判断和评估这些交互
- 调整数据和算法设置
- 重新培训系统的下一个版本
下图展示了如何将这些步骤组织到一个认知开发周期中。
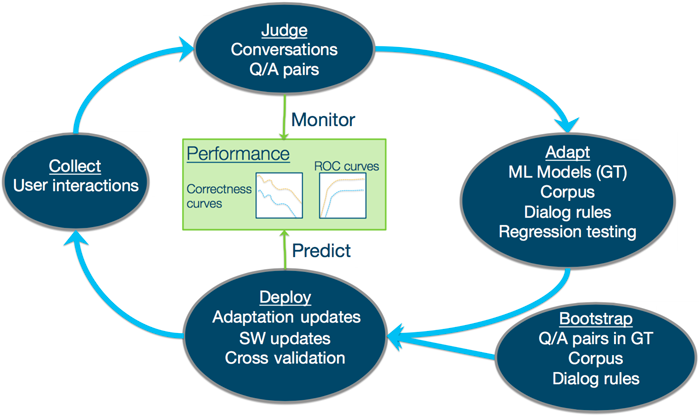
该周期中最单调乏味的步骤,大概就是判断和评估任务。其他大多数任务都可以在一定程度上进行脚本化和自动化,但需要获取人类输入来评估系统处理看不见的真实数据(我们称之为 野数据 )的有效性。举例而言,在我们的初步研究中,需要 3 个人花费约 6 周的时间来检查和标记 5000 个问题和答案对,以形成部分地面真值 (ground truth),地面真值是机器学习中的使用的一个术语,表示用于监督用于训练模型的机器学习算法的已知正面示例。他们需要使用电子表格和文本编辑器来仔细检查和评估数据。除了需要花费时间之外,工作本身也非常单调乏味、容易出错,而且是单线程的(人们无法同时处理相同的数据)。相对而言,通过使用 Watson Annotation Assist,我们团队的工作量将大大减少,减少到每 1000 个问题 20 个工时。
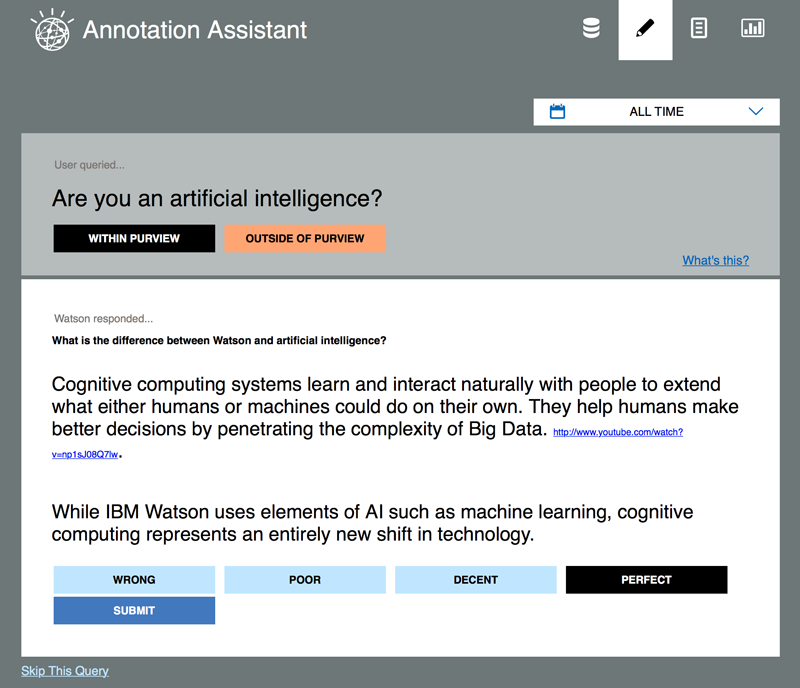
您可以使用 Watson Annotation Assist 快速评估来自认知系统的问题和答案 (Q/A) 对的正确性。Annotation Assist 基于 Web,允许多个用户同时检查和注释来自单一数据存储的问题。Annotation Assist 会提供尽可能少的不必要信息,同时最大限度减少评估一个 Q/A 对所需的用户交互量。下图展示了 Annotation Assist 用户界面。
运行 Annotation Assist 需要做的准备工作
- 一个 Bluemix 帐户。(您可以在此处申请一个 免费试用版帐户 。或者您是否知道 developerWorks Premium 提供了 IBM Bluemix 的 12 个月订阅和 Bluemix 上的 240 美元云贷款?)
- Cloud Foundry CLI
- 访问 DB2 实例的能力
部署 Watson Annotation Assist
Watson Annotation Assist 是一个开源 Python CF Web 应用程序,是为在 IBM Bluemix 上运行而设计的。以下步骤展示了如何将 Annotation Assist 和所有必备服务部署到 Bluemix 上。
获取代码
- 如果还没有安装 Cloud Foundry 命令行接口 (cf CLI)
cf工具,请安装它。 - 使用以下命令登录到您的 Bluemix 帐户。
cf api https://api.ng.bluemix.net cf login -u <ibmid> -o <ibmid> -s dev
- 克隆 Annotation Assist GitHub 存储库。
- 在您的计算机上为该项目创建一个文件夹。我们选择了一个名为 “demo-aa” 的文件夹。
- 转到该文件夹,使用 cf 命令行工具克隆该存储库:
git clone https://github.com/cognitive-catalyst/annotation-assist.git
- 在 manifest.yml 文件中分配一个唯一的主机名和应用程序名称。
-
确保您能够访问 DB2 实例。
您可以使用想要的任何 DB2 实例。轻松获取 DB2 实例的一种方法是在 Bluemix 上部署一个 DB2 容器。具体的步骤取决于您的本地计算机的操作系统。您可以按照刚克隆的 Git 存储库中 README.md 文件中的步骤操作;例如 demo-aa/annotation-assist/db2container/README.md。
-
使用 DB2 连接信息修改 properties.ini 文件。
properties.ini 文件位于 demo-aa/annotation-assist/config/properties.ini,必须使用 DB2 连接信息进行修改。您还可以在此文件中设置用户用于登录应用程序的凭证信息。
[properties] username (application level username) password (application level password) [db2] hostname (the hostname of your db2) username (the db2 user) password (the password for the db user) port (the port to access the database, default 50000) db (name of database)
-
使用 cf 命令行工具将应用程序推送到 Bluemix。
cf push
此过程之多会花 15 分钟。部署完成后,Annotation Assist 应用程序会在您在第 4 步中创建的 URL 上正常运行。
评估系统性能
Annotation Assist 运行后,您必须准备您的数据并启动注释过程。
准备您的数据
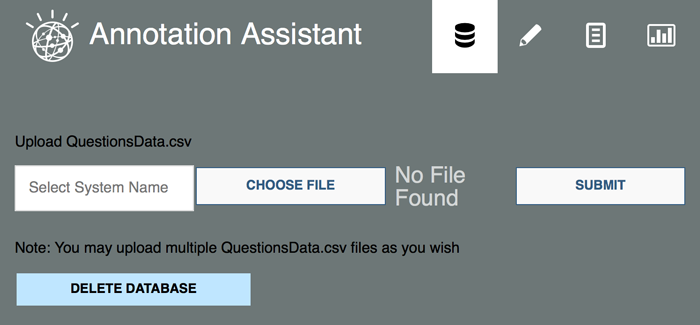
Annotation Assist 应用程序需要一个包含以下标头的 CSV 文件:
QuestionText | TopAnswerText | TopAnswerConfidence |
|---|---|---|
| ... | ... | ... |
使用您最喜欢的数据清洗 (data wrangling) 工具(比如 R 或 Pandas)格式化您的 Q/A 数据。您可以有多个文件,每个文件对应您想要对比的一个系统或系统版本。上传可直接在该工具内完成。
注释问题
单击应用程序中的铅笔图标转到注释界面。注释由两个步骤组成:
- 问题在范围内还是范围外?
- 如果问题在范围内,答案的正确度是多少?
在大部分情况下,每个问题都将遵循此模式。有时,Annotation Assist 会询问一个问题是否是一个类似问题的改述。如果是,您可以单击 “yes”,减少进一步单击的次数。
获取中间和最终结果
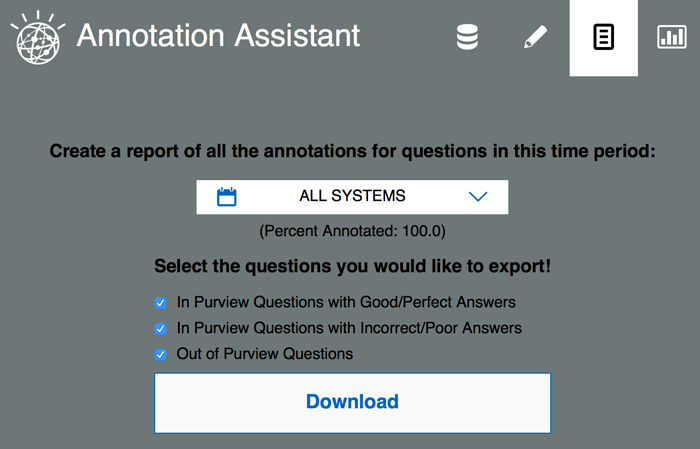
页面图标(第 3 个图标)允许您查看您的注释进度。它还允许您下载中间结果。在完成注释后,您还可以可从此页面下载最终结果。
您可以将所有系统的结果下载为单个文件,也可以选择仅下载针对某个输入文件的已注释问题。您可以基于注释数据来选择要包含哪些问题,例如仅选择在范围内或范围外的问题,以及正确或错误的问题。
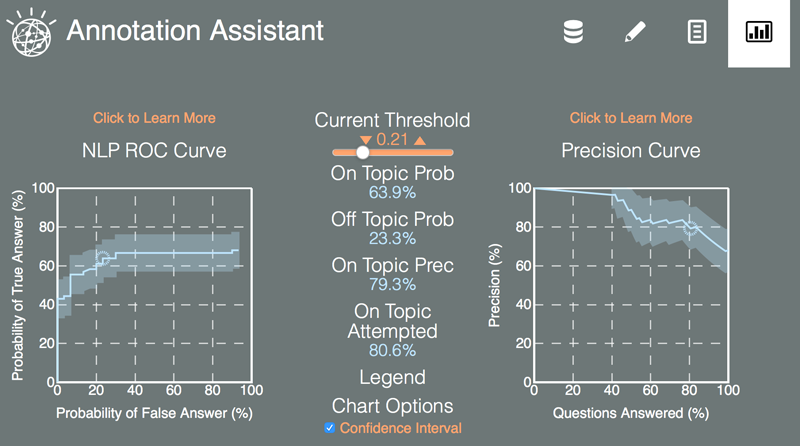
使用 ROC 和精度曲线评估性能
您可以在图形页面上查看注释结果(第 4 个图标)。大多数认知系统通常都有一个置信度截止阈值。置信度低于这个阈值的答案回被视为不明确的答案。例如,如果阈值设置为 20%,而一个认知系统提供了一个具有 19% 的置信度的答案,那么该系统会使用一条类似 “我不确定” 的语句作为响应。置信度临界值对系统的性能和认知智能具有很大的影响。
Receiver Operating Characteristic (ROC) 和精度曲线对判断认知系统的临界阈值对系统准确性和行为的影响很有用。ROC 曲线对比可以正确地回答某个主题内问题的概率,以及错误地响应某个主题外答案的概率。ROC 曲线的左上角表示最佳性能,而从左下角到右上角的对角线表示随机猜测的性能。精度曲线显示了已正确回答且拥有高于阈值的置信度值的问题占已回答问题总数的百分比。
使用这些曲线,您可以分析置信度临界阈值的更改对性能的影响。您可以选择最佳的阈值,得到一个让系统的行为符合您的预期的操作点。一个不错的指导原则是将操作点设置的离左上角尽可能近,以得到平衡的性能,但您可能希望试验一下。
注释最佳实践
注释大量数据可能让人望而生畏。我们推荐我们的团队在使用 Watson Annotation Assist 时遵循的一些最佳实践:
- 以团队形式执行注释: 如果只有一个人执行注释,您的结果可能存在偏见或曲解。如果可能,请以团队形式执行注释。
- 许多较短的会议胜过少量大型的会议: 注释问题很消耗脑力,可能导致不知不觉间产生判断错误。我们发现持续 45 分钟的会议的效果不错。
- 经常沟通: 有时一个 Q/A 对存在歧义。我们通过组队(但单独)注释来解决这个问题,无论是面对面还是通过电话组队。分享您对困难示例的想法,可以使每个人决定最佳的行动过程,确保在未来的 Q/A 对中达成一致。
结束语
通过安装 Annotation Assist 应用程序,可以让 Watson 项目轻松地收集对 “问题/答案” 对的判断。有了这些判断,现在您可以:
- 对比 Watson 系统的以前版本与当前版本的相对性能。
- 调整表示 Watson 将基于 Watson 系统的期望性能来回答问题的时刻的操作点阈值。
- 将被判断为 “良好” 或 “完美” 的所有 Q/A 对添加到地面真值中。
- 专注于对被判断为 “错误” 或 “差” 的 Q/A 对的系统改进。对于此类别中的每个问题,如果语料库中包含合适的答案,您可以将正确的 Q/A 对添加到地面真值中。如果未在语料库中找到答案,您可以使用合适的材料扩充语料库,然后使用正确的 Q/A 对扩充地面真值。
- 使用新的地面真值重新训练您的 Watson 系统,重新部署,然后开始认知开发旅程的下一个周期。
在新的认知计算模式中,收集高质量的数据来训练您的 Watson 实例,这对提升您的服务性能是不可或缺的。Annotation Assist 应用程序是一种完美的补充,可帮助您改进地面真值,在持续跟踪您的系统所基于的机器学习模型和语料库的过程中跟踪 Watson 系统的性能。祝您拥有愉快的认知计算旅程!
相关主题: IBM Bluemix Cloud Foundry cf 工具 认知计算专区
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

