IBM SPSS Modeler 客户端 vs 服务器的区别详解
IBM SPSS Modeler 的客户端与服务器的区别,从以下7个方面做对比:
1.功能
两者没有区别,都涵盖了数据挖掘整个生命周期的所有功能,包括数据整理、创建模型、评估模型到应用模型的所有功能。
2.模型共享
客户端所创建的数据流(Stream),模型等都是以文件形式保存在本地客户端上,而如果使用服务器,那么所有创建的数据流(Stream),模型等都是保存在服务器上,各个用户连接上服务器后,可以共享这些资源。
3.数据安全
由于客户端可以直接连接数据库,那么数据文件可以直接导出保存在客户端上,如果是比较机密的数据,会存在数据不安全的问题;如果是服务器,连接数据库是通过服务器连接,导出的数据也是保存在服务器上,用户没有办法下载到本地,保证了数据的安全。
4.自动调度任务执行
客户端不能自动调度任务运行,每次任务的执行都需要打开客户端,点击运行来执行任务。而服务器可以通过批处理(batch)的方式自动调度任务运行,客户只需要创建批处理文件,再通过Windows或Linux操作系统上的计划任务自定义运行周期,定时执行任务。一般情况下,会定义晚上执行任务,避免白天影响其它系统的正常工作。
5.性能
数据的分析处理性能是依赖于运行环境的硬件,数据量以及使用的算法,如果是客户端,无法支持大数据量的处理,而如果使用服务器,可以大大提升数据处理性能。比如原始数据量达到千万级数据量,如果使用客户端,基本上无法支撑。
6.对Hadoop数据源的支持
客户端不支持直接连接Hadoop数据源,因此如果需要连接Hadoop数据源,实现分布式计算,则必须同时配置以下三个模块,分别是Modeler 客户端、Modeler服务器以及IBM SPSS Analytics Server才能够实现。
7.支持的操作系统
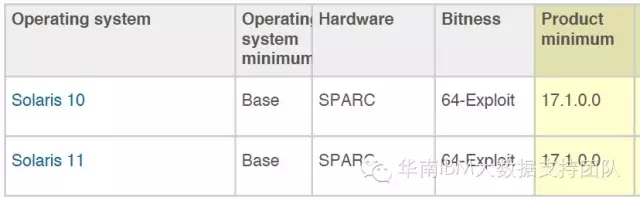
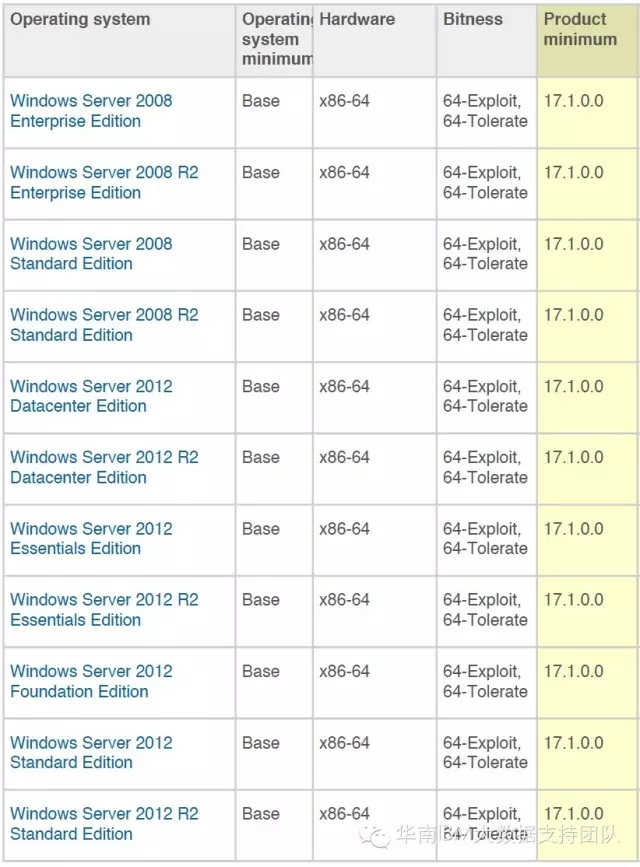
客户端只支持Windows操作系统,服务器则可以安装在多类系统上,包括Windows,Linux,Solaris,AIX等操作系统上。
以下列出客户端及服务器各自支持的操作系统:
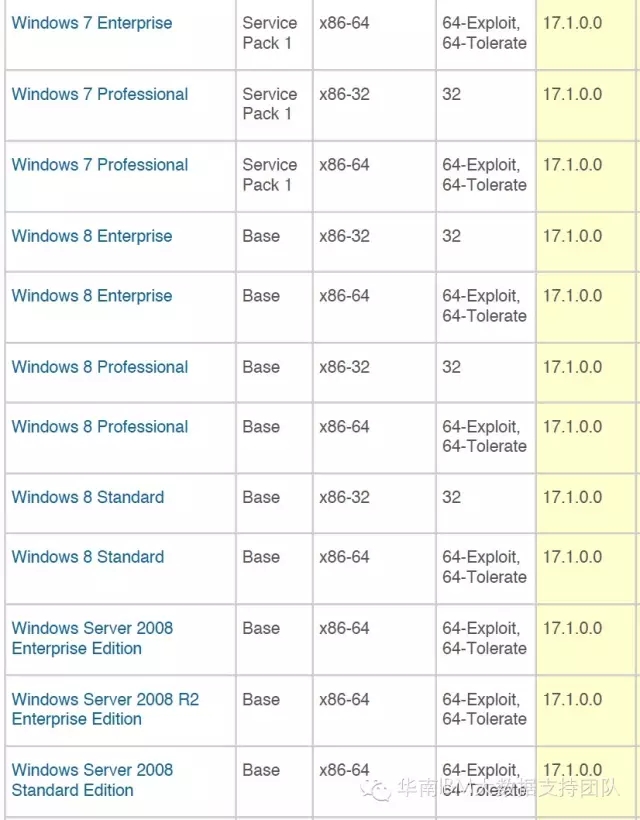
Modeler 客户端
PS:以下列出的Windows Server操作系统,命名用户(AuthorizedUser) 不支持,并发用户(Concurrent User)才支持。
Modeler 服务器
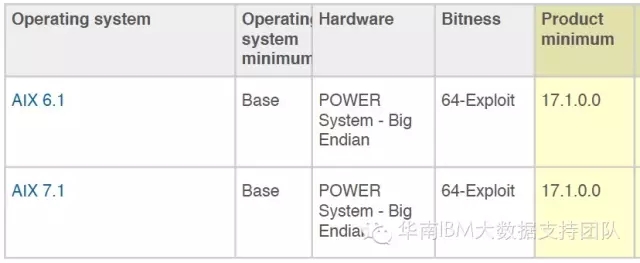
AIX
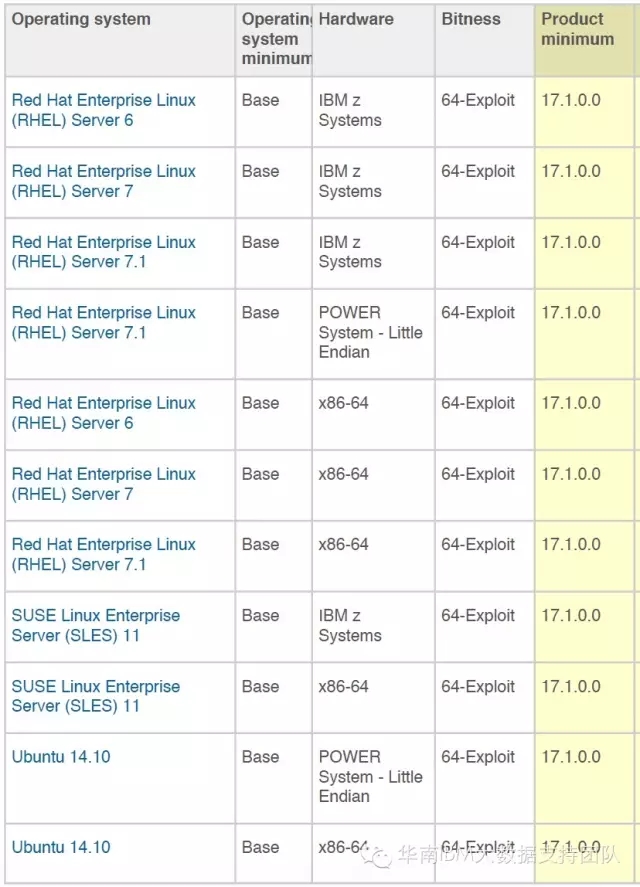
Linux
Solaris
Windows
总结
基于以上对比,虽然客户端与服务器在功能上区别不大,但客户端一般适用于个人学习使用,而对于企业级的应用,需要注重模型共享、数据安全、自动化任务执行以及处理性能,因此我们建议配置客户端与服务器共同使用,以保证项目的顺利进行。
IBM SPSS Modeler最新试用版请直接点击下载>>>
详情请咨询“ 在线客服 ”!
客服热线:023-66090381
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

