nodejs爬虫实战(一):抽屉新热榜
什么是nodeJs
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境。Node.js 使用了一个事件驱动、非阻塞式 I/O 的模型,使其轻量又高效。Node.js 的包管理器 npm,是全球最大的开源库生态系统。
开启我们的第一个nodejs项目
首先可以去nodejs官网来下载nodejs并安装 http://nodejs.cn/ 。
安装完成后,通过npm来安装我们的express框架 npm install express --save 。
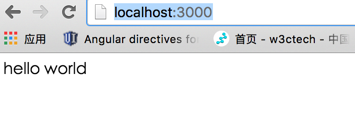
//app.js //引入 `express` 模块 var express = require('express'); //调用 express 实例并将这个变量赋予 app 变量。 var app = express(); // app 本身有很多方法,其中包括最常用的 get、post、put/patch、delete,在这里我们调用其中的 get 方法,为我们的 `/` 路径指定一个 handler 函数。 // 这个 handler 函数会接收 req 和 res 两个对象,他们分别是请求的 request 和 response。 // request 中包含了浏览器传来的各种信息,比如 query 啊,body 啊,headers 啊之类的,都可以通过 req 对象访问到。 // res 对象,我们一般不从里面取信息,而是通过它来定制我们向浏览器输出的信息,比如 header 信息,比如想要向浏览器输出的内容。这里我们调用了它的 #send 方法,向浏览器输出一个字符串。 app.get('/',function(req,res){ res.send('hello world'); }) // 定义好我们 app 的行为之后,让它监听本地的 3000 端口。这里的第二个函数是个回调函数,会在 listen 动作成功后执行,我们这里执行了一个命令行输出操作,告诉我们监听动作已完成。 app.listen(3000, function () { console.log('app is listening at port 3000'); }); 运行 node app.js 并且访问 http://localhost:3000/ 即可看到 hello world
爬虫依赖
所谓 工欲善其事必先利其器,完成nodejs爬虫还需要加两个库:
superagent( http://visionmedia.github.io/superagent/ ) 是个 http 方面的库,可以发起 get 或 post 请求。
cheerio( https://github.com/cheeriojs/cheerio ) 大家可以理解成一个 Node.js 版的 jquery,用来从网页中以 css selector 取数据,使用方式跟 jquery 一样一样的。
分别安装 npm install superagent --save npm install cheerio --save 。
抓取抽屉新热榜数据
先从简单的开始,我们来以抽屉新热榜为例子。访问 http://dig.chouti.com/ ,通过浏览器的调试器来看抽屉的dom结构,可以看到.part2的类上有用于分享的属性,我们就可以直接通过jquery的语法来读取标题,图片和超链接这几个属性
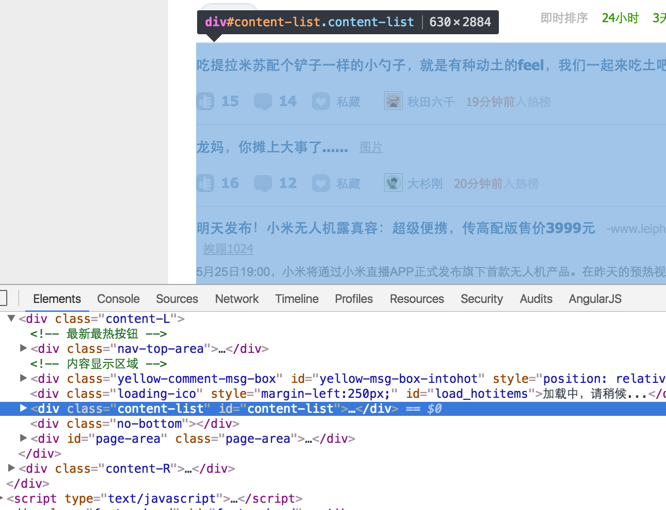 可以看到新热榜数据都在 id为'content-list'的div中,于是我们展开content-list来继续查看数据
可以看到新热榜数据都在 id为'content-list'的div中,于是我们展开content-list来继续查看数据
 发现有个class为'part2'的div里面有 share
发现有个class为'part2'的div里面有 share
app.js //引入 `express` 模块 var express = require('express'); //引入 `superagent` 库 var superagent = require('superagent'); //引入 `cheerio` 库 var cheerio = require('cheerio'); //调用 express 实例并将这个变量赋予 app 变量。 var app = express(); // app 本身有很多方法,其中包括最常用的 get、post、put/patch、delete,在这里我们调用其中的 get 方法,为我们的 `/` 路径指定一个 handler 函数。 // 这个 handler 函数会接收 req 和 res 两个对象,他们分别是请求的 request 和 response。 // request 中包含了浏览器传来的各种信息,比如 query 啊,body 啊,headers 啊之类的,都可以通过 req 对象访问到。 // res 对象,我们一般不从里面取信息,而是通过它来定制我们向浏览器输出的信息,比如 header 信息,比如想要向浏览器输出的内容。这里我们调用了它的 #send 方法,向浏览器输出一个字符串。 app.get('/', function (req, res, next) { // 用 superagent 去抓取 http://dig.chouti.com/ 的内容 superagent.get('http://dig.chouti.com/') .end(function (err, sres) { // 常规的错误处理 if (err) { return next(err); } // sres.text 里面存储着网页的 html 内容,将它传给 cheerio.load 之后 // 就可以得到一个实现了 jquery 接口的变量,我们习惯性地将它命名为 `$` // 剩下就都是 jquery 的内容了 var $ = cheerio.load(sres.text); var items = []; $('#content-list .part2').each(function (idx, element) { var $element = $(element); items.push({ title: $element.attr('share-title'), href: $element.attr('href'), img: $element.attr('share-pic') }); }); res.send(items); }); }); // 定义好我们 app 的行为之后,让它监听本地的 3000 端口。这里的第二个函数是个回调函数,会在 listen 动作成功后执行,我们这里执行了一个命令行输出操作,告诉我们监听动作已完成。 app.listen(3000, function () { console.log('app is listening at port 3000'); }); 运行 node app.js 访问: http://localhost:3000/ ,可以看到抓取的数据直接以json格式显示出来了。

正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

