当AlphaGo战胜李世石以后,我们来聊聊深度学习
大家好,我是黄文坚,今天给大家讲讲深度学习。我不讲技术原理,讲讲技术应用。
深度学习是我们明略重要的研究方向,是未来实现很多令人惊叹的功能的工具,也可以说是通向人工智能的必经之路。
1.深度学习的丰富应用
Google研究的无人驾驶 ,其组件由两个部分组成,一个是眼睛,一个是大脑,眼睛是激光测距仪和视频摄像头,汽车收集到这些视频信号之后,并不能很好的识别,为了让汽车能理解我们需要一个大脑,这个大脑就是深度学习,通过深度学习我们可以告诉我们的车载的计算机,现在前面有什么样的物体,并且结构化的抽取出来。
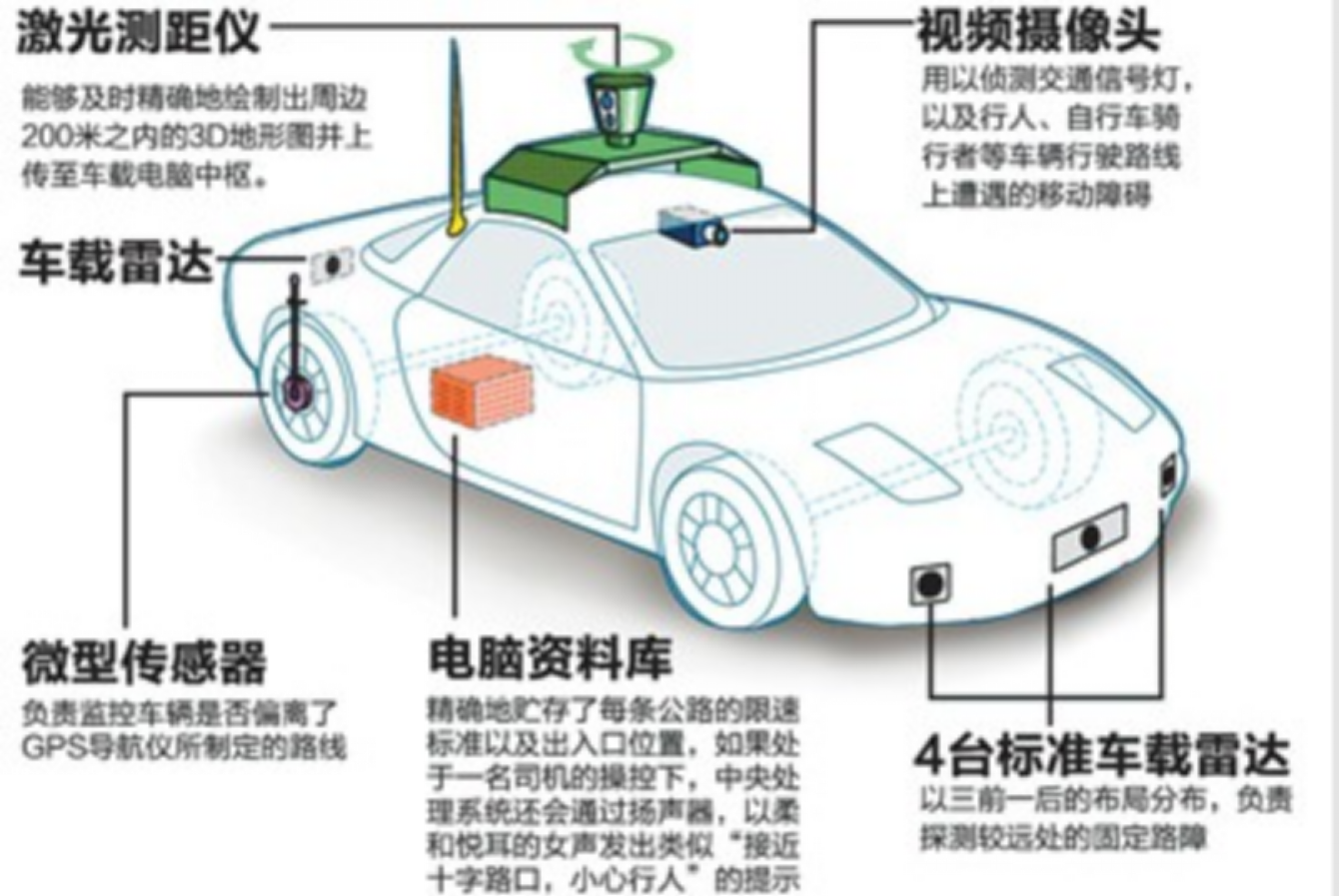

比如说这个是通过挡风玻璃看到的画面,让机器理解,必须要判断视野内的物体是移动还是静止,如果是静止的话,可以当作是安全的物体,只需避让即可,如果是移动的物体,那么还需要我们判断他的速度和行驶方向进行相应的路线规划。

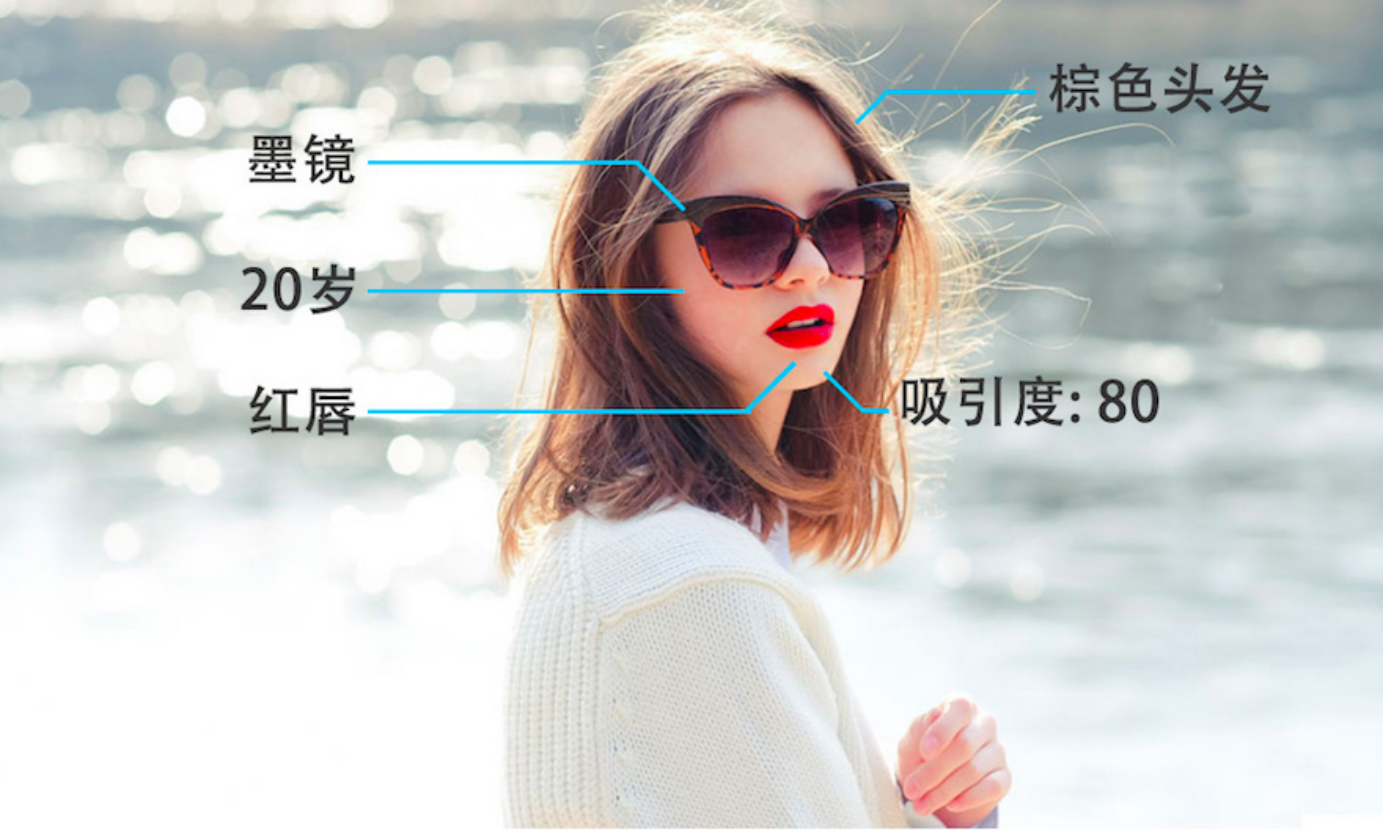
人脸识别 ,我们有很多技术做人脸识别,人脸识别可以做什么其他的东西呢?深度学习不止告诉我们人脸在图片中哪个位置,甚至告诉我这个人脸是谁的脸,是男性、女性,多大岁数都可以学习出来,包括人脸部的重要结点位置可以猜出来这个人是什么样的表情,甚至通过分析他嘴唇的动作,可以说这个人在说什么话,包括头发的颜色,戴什么样的墨镜,嘴唇涂什么样的唇膏都可以识别出来。

格林深瞳 的例子,比如说我们在重要机构里面可以有安防监控,深度学习训练的卷积神经网络CNN,可以识别被监控的人员是否有异常的举动,还有就是对车辆的追捕,这辆车是否有逃逸的可能性,超速行驶,逆行变道的风险。

AlphaGo 2016年3月,Google DeepMind研发的 AlphaGo 4:1 战胜了世界冠军李世石。标志了一个时代的终结和一个时代的开始,人类在完全信息博弈的竞技中败北,人工智能发展的元年开始。
围棋很难被攻破的原因就是复杂度太高了,每一步棋都有300多种可能,一盘棋平均有200多步,总的状态数量超过了整个宇宙中所有原子的数量,不可能被搜索完整的状态,我们只能通过估算和直觉进行围棋的计算和思考。象棋很早就被攻破了,围棋可以坚持这么久。深度学习可以让机器有人类的直觉,预测人下一步要走什么,同时分析及其应该走哪一步。所以说DeepMind研发的AlphaGo,基本上做到了知己知彼。
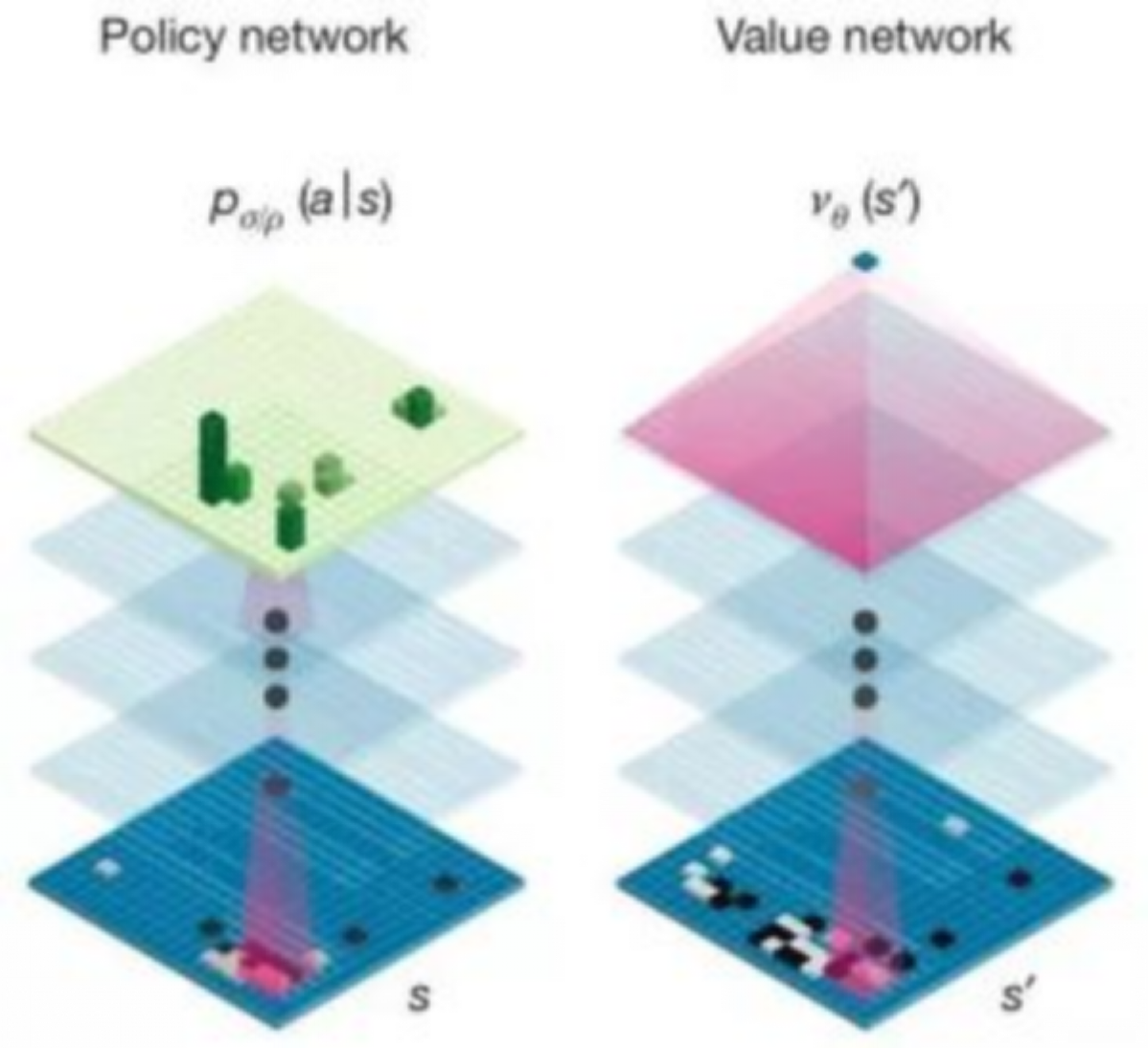
我们再来看看这两个DeepMind深度学习的网络,左边是策略网络,我走到一步的时候,分析棋盘上每个位置有多大价值,给每个位置打一个分数。右边这个估值网络是估算黑白双方的胜率的神经网络。通过这两个网络的结合,再加上一些之前通用搜索的方法,比如蒙特卡洛搜索树,可以让计算机拥有一个非常强的对战能力。事实上是通过复盘的结果,AlphaGo和李世石对战的时候,AlphaGo从一开始就认为自己的胜率有60%以上,到最后基本达到了90%,他对整个棋盘的控制超过了人类的理解了,情况并不是很多评论员所认为的可能双方还是均势,李世石还有机会等等。大局完全都在AlphaGo的掌握当中。

Deep Q Net,深度强化学习可以教会机器人如何灵活使用机械臂完成任务。 如果之前让一个机器人编程,让他去夹一个物体,不能有太多的干扰,否则就无法实现准确的抓取。现在我随便放一盒子东西,深度强化网络可以自动训练这个机器人拿什么样的物体,同时训练它怎么去夹,第一次没有夹到那就再学习,再尝试,直到学会。可以说深度学习让机器人拥有几岁小孩拾起物体的能力。


Google DeepDream实现梦幻般的图片生产,仿若梦魇一般 。
大家看这个图,下边这个图是不是有点抽象,这个画是用深度学习网络自动生成出来的,基本原理就是人观察一张图片的时候,记不住所有的细节,在我们脑子里重构的时候会用之前的经验和概念在脑中塑造一个新的图片,而深度学习也是这个意思,在大数据量的需要上,积累了很多过往的经验和数据,我们给他一幅图片重构的时候,就制造出一个仿佛做梦或者脑海中胡思乱想的时候对这个图片产生的理解。所以我们可以说,它已经具备了人类对事物抽象和重构的能力。
使用深度学习实现的EasyStyle,可以将任意图片内容与另一种图片风格融合



这个图可能大家很熟悉,最上边这位是美国总统竞选人Trump, 中间这幅画是著名画家的画作,通过深度神经网络结合我们可以合成下面的图,没有进行任何算法的调优,它获取上边这个图内容的信息,再获取中间这个图风格的信息,完美的结合就成了中间这张图。
Neural Doodle – 将涂鸦变成绘画
比如说随手涂鸦一幅画,可以得到一幅像模像样的一幅山水画。
我们还可以先解析一幅图的主要组成部分,然后调整其中的形状,再把原来的图重构出来,我们可以得出现实生活中不存在的图,这个是类似于人脑对物体的解析和重构的能力。
Image Analogies – 使用深度学习变形图片

Deep Q Net - 深度强化网络实现AI自动玩游戏

GoogleDeepMind除了做围棋软件还有实现自动玩游戏的AI,人类学习并不是一个监督和非监督的过程,是一个奖惩的机制,你做对的时候会有好的刺激,比如说我哭了,我妈妈过来把饭拿过来了,我吃了,很高兴,我下次可能饿了还要再哭。这套系统也是这样的,随即采取一些策略获得比较高分的时候,他会记住这个策略。这幅图是太空大战游戏,使用程序玩游戏已经超过了世界上玩这个游戏选手的最高水平了。
动态记忆网络实现的图片问答系统
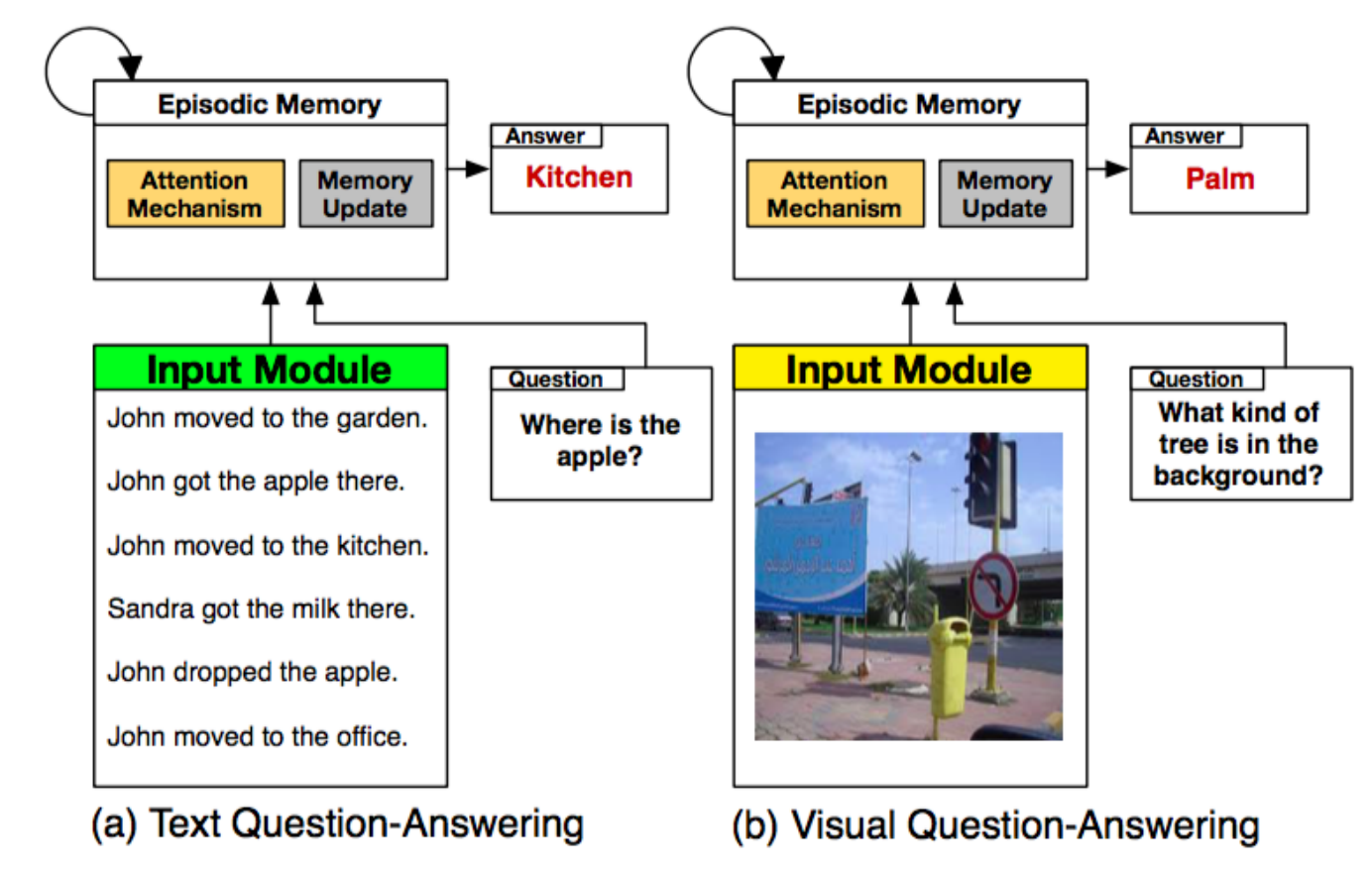
我们可以看看这幅图,左边是使用一个基于LSTM长短期记忆网络的动态来对一段语言进行理解,并回答问题。而右边则是直接对图片进行提问并让计算机回答,使用的技术是动态记忆网络。
目前我们可以做到这种程度,问左上角大巴的颜色是什么,最后转换成语言回答,虽然回答只是简单的单词,但是事实上深度神经网络已经理解你的问题,同时在图片上理解相关要素,然后再解析,回答你的能力了。其他几个图也是类似的概念。

其实深度学习学习的发展是离不开研究人员对 数据集 的探索的,之前我们有一个知名的数据集叫做ImageNet,是有几百万张图片让深度学习网络训练和测试。现在它升级了,叫Visual Genome,不止对图片分类,还要看出有什么关联,比如说这里有一个女人,戴着帽子,和帽子是什么关系,是佩戴的关系。她拿着吉他是拿和演奏的关系,我们要找不同物体之间存在的关系。

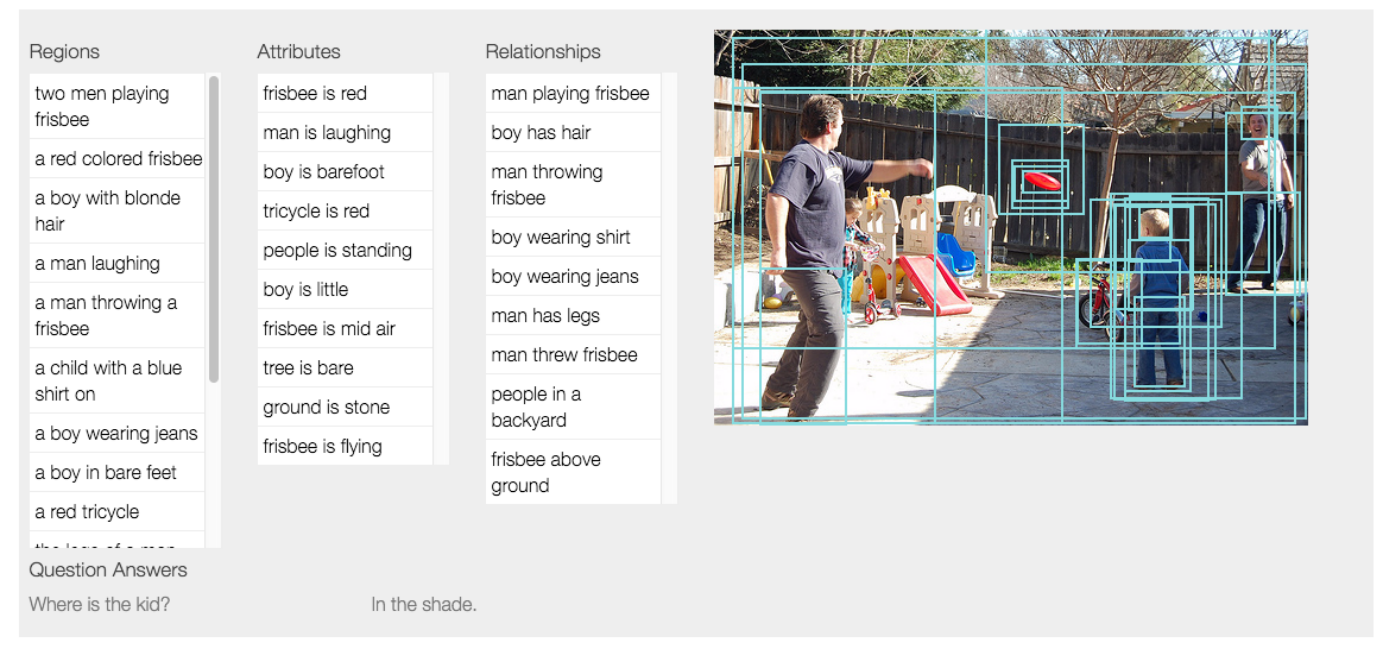
这个图是一个简单的例子, 深度神经网络可以解析出这个图片上有两个成人和小孩,小孩扔飞盘,大人在看,我们要把关联的关系、动态的关系都挖掘出来。
图像识别与NLP ,使用Deep Learning解析图像中的结构化信息,并生成描述性语言
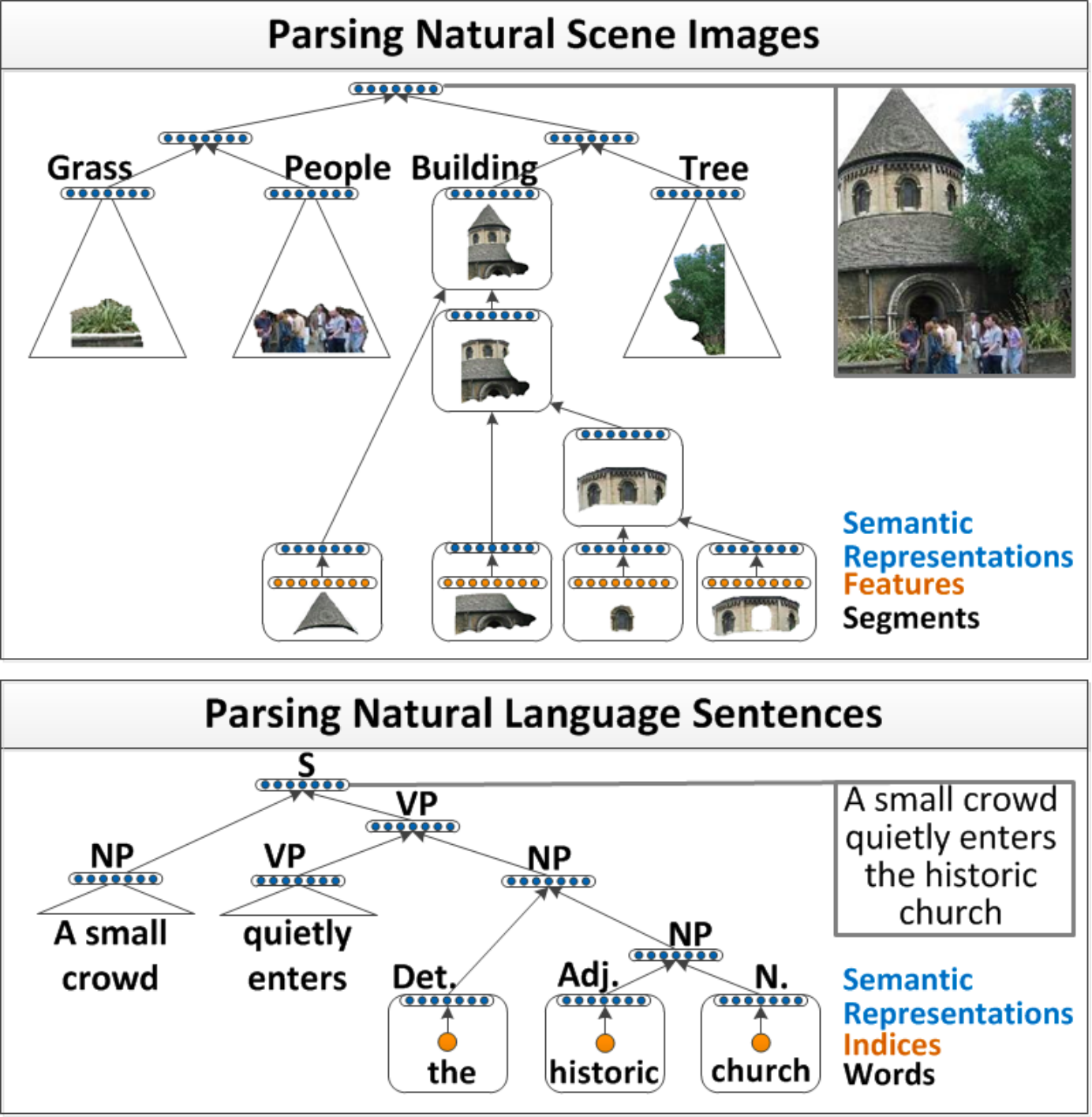
我们看看这幅图上能做什么,我们可以让深度神经网络先尝试理解这幅画的结构,然后再用语言把这幅画描述出来,比如生成这样一段话:这张图右边有一棵树,左边有一个塔,塔有一个塔尖和一个塔身组成,塔身上有三个窗户,有一个门。塔前有许多人在站着
Word Embedding, 或者Distributed Representation, 中文叫 词向量 ,是使用深度学习学习出来的单词的向量化表示,有如下特性:
King – Man ≃ Queen – Woman
同时意思相似的词,在空间位置上距离相近
词向量把我们常用的词汇转化为空间中的某一个点,点有什么特性呢: 如果词汇意思相近的话,在空间中位置应该也是相近的,左上角可以找到许多点都是城市,虽然深度神经网络不知道北京、伦敦在什么地方,里面有什么建筑也都不知道,但是通过大量的学习出来城市的概念,并把他们放在空间中很相近的位置。我们并没有任何的语言和数据教它,是他通过大量的学习自己发现的。
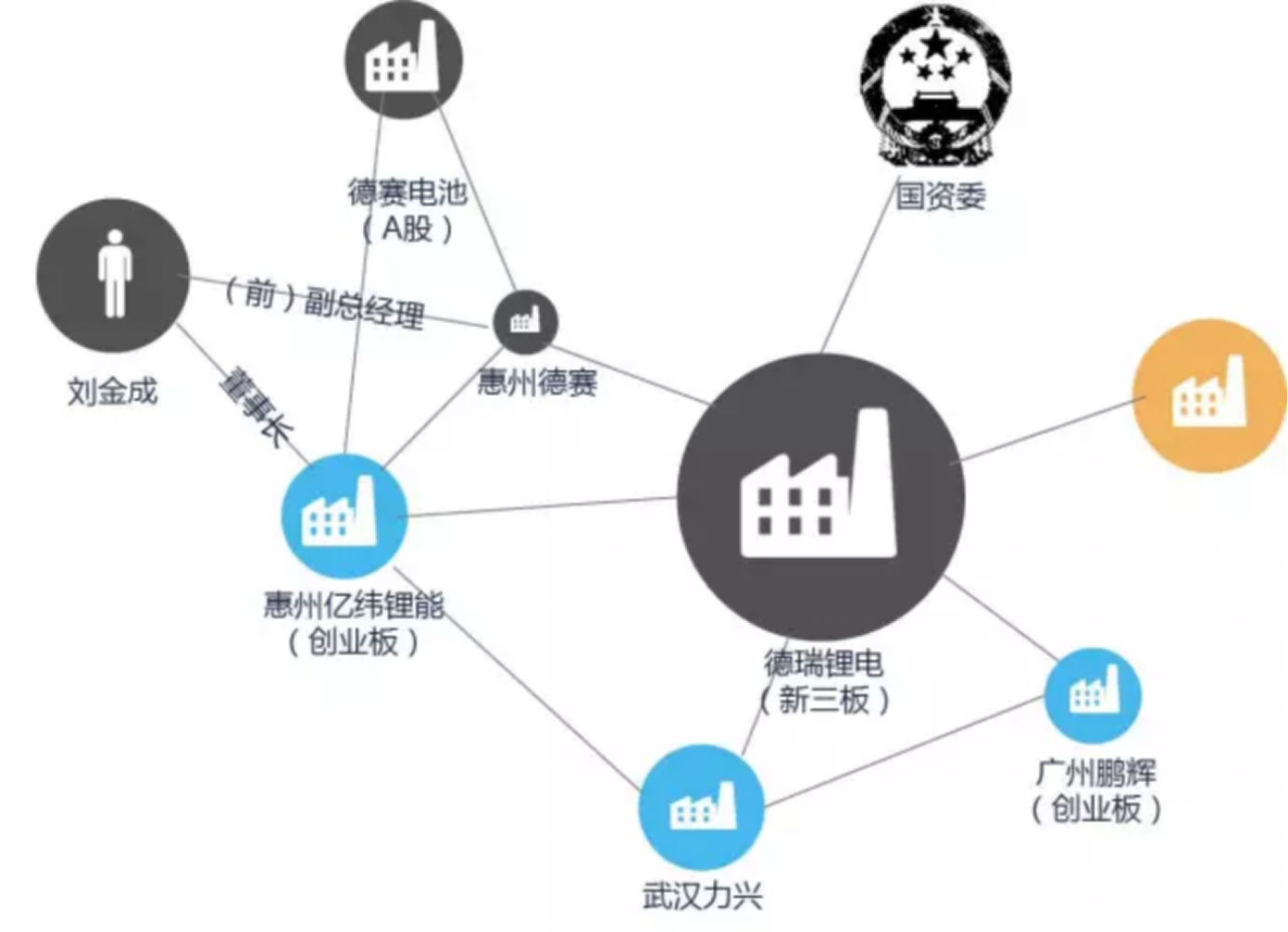
我们学习构建一个深度的 知识图谱可以用在企业关系的挖掘 ,有一家上市公司,比如说是做锂电池的,可以找到他投融资的企业,并将上下游竞争关系全部联起来,这些企业之间会有信息的传递,如果网络构建足够大可以有一个模型,分析预测这个上市公司股价以后未来的走势。
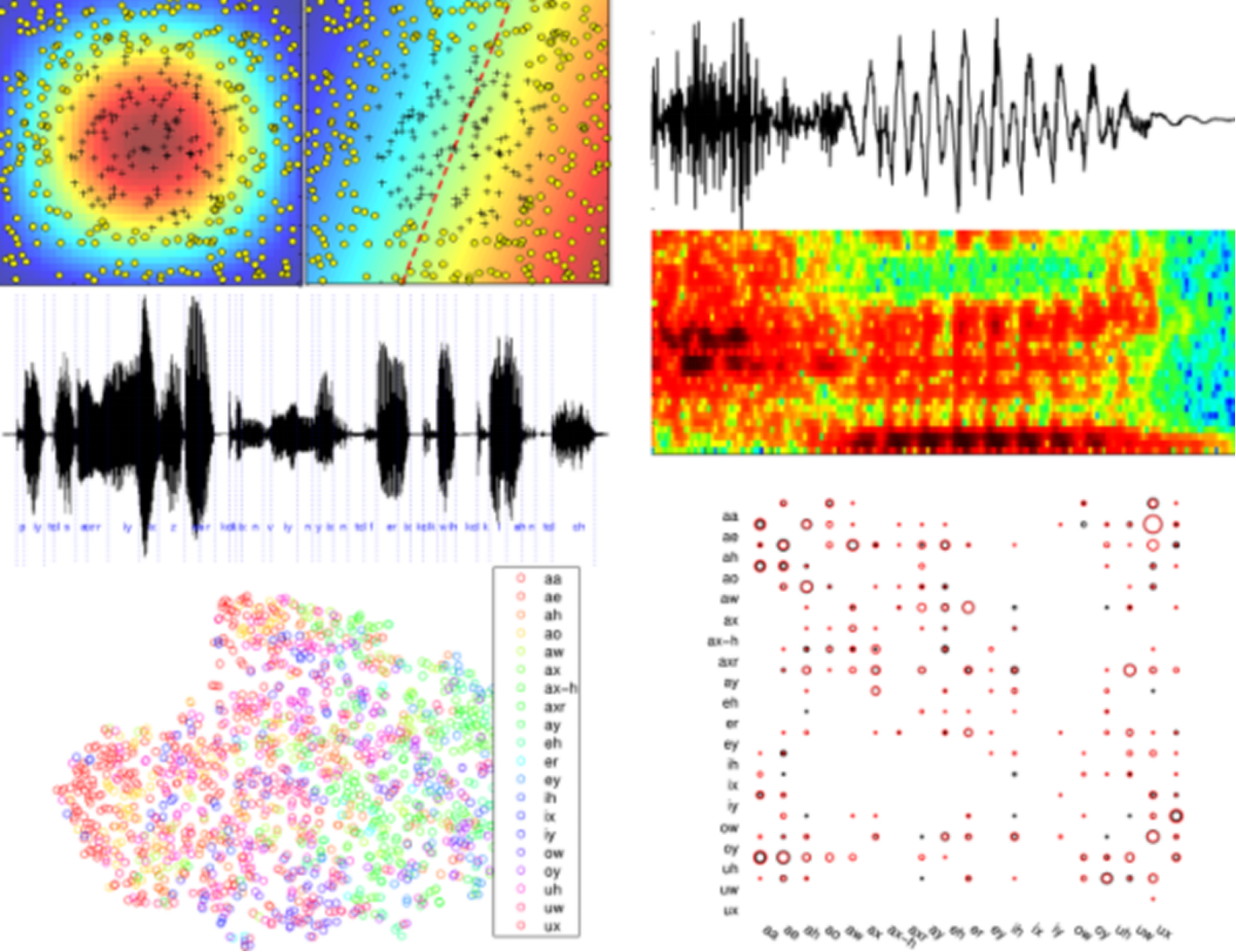
语音识别 ,百度最近有一个语音识别,叫双向循环神经网络BDRNN,可以把每个音节都识别出来,发音中略微有一些口音和错误,也能够把大致的意思正确的识别出来。这个是语音识别的可视化的图像,我们把语音信号降维成一个平面的图,你会发现同一个元音音节和辅音音节在平面当中很相近的,都被抽象成有相邻关系的点,说明它真正理解了语音这个声频信号代表的含义。
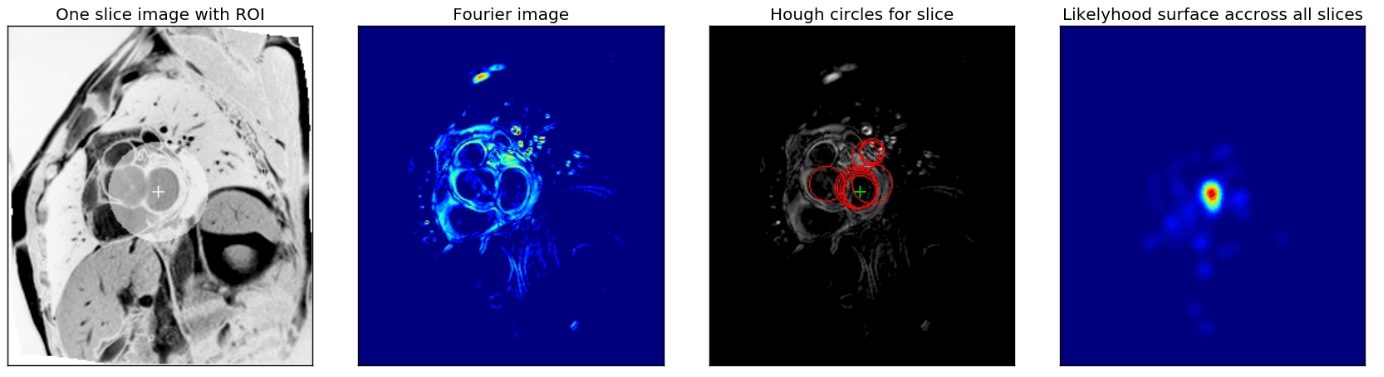
作为医疗诊断的重要根据 ,这是去年特别有名的心脏疾病诊断的比赛,当时参加比赛的最后获得冠军的队伍,他们做到了准确度甚至超过了专家的水平。将几万张图片给深度学习的网络学习规律,其中正确答案是五位专家商讨得到的,但是计算机的水平超过了单个专家的诊断水平。
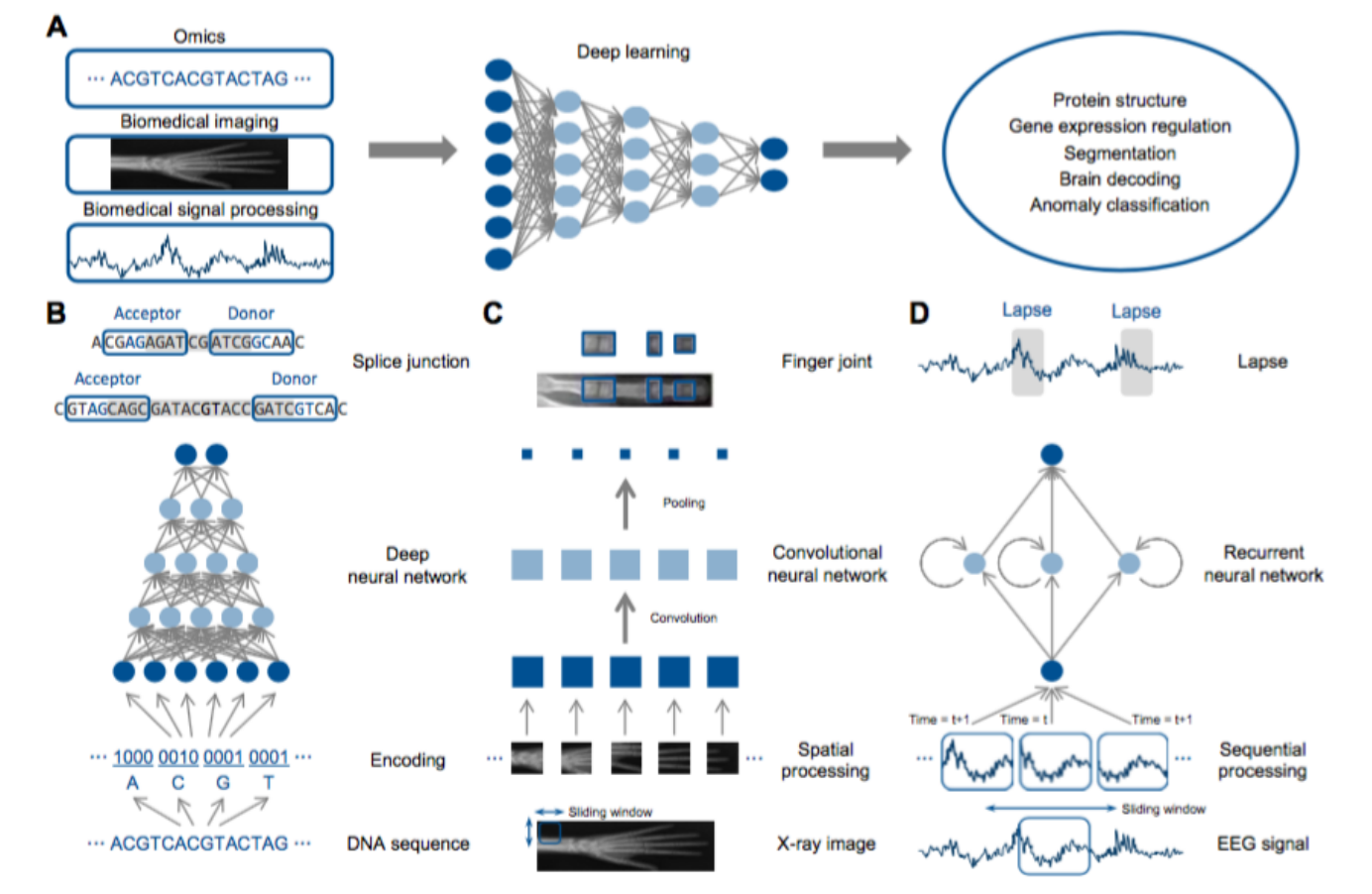
Deep Learning in Bioinformatics:深度学习在生物医学领域,比如医学图像处理、医学信号处理等有很好的应用基础
对DNA的解析 ,有很多遗传病是基因突变引起的,可能不是某一两个节点,可能是同时有几千个节点发生了问题,让人判断究竟怎么组合才会出问题是不可能了。这个时候深度学习可以来告诉我们,我们拿到一个人DNA之后,可以自动分析出来你在未来得某种疾病的几率有多少,可以提早的预防治疗。
2.深度学习到底为什么这么厉害
深度学习是一个对特征不断抽象的过程,我们给他一个图片,深度神经网络首先提取出点和边,然后组合成人局部的器官,比如说一个眼睛和鼻子,局部的器官之后可以把拼接成一个个人脸,人脸外貌上有差异,我们用模版再匹配出最相似的就可以看看有没有人脸,深度学习非常像人的学习过程,你必须一层一层的抽象才能理解更深的概念,之所以叫深度是有多层的学习网络,每一层是把特征抽象更高阶的概念,理解非常复杂的事物。

这是深度学习网络可视化的结果,我们给一个识别数字的神经网络一张数字‘8’的图,可以清楚的看到每一层神经网络对原图进行了哪些特征变换。
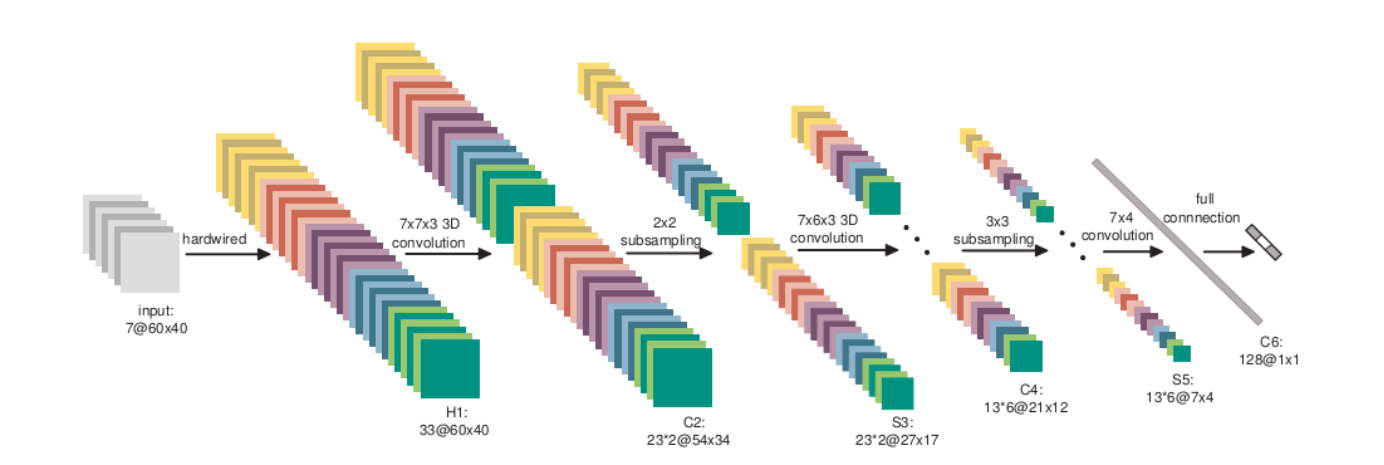
这是一个深度学习常见的卷积结构,细节不讲了,大家可以感受一下,其中主要了Convolution Layer, Max-Pooling Layer, 以及ReLu Activation。
Auto-Encoder(Layer-wise Training), RBM, DBN
- PReLu, RReLu
- Dropout
- RNN, LSTM
- Max-Out
- Highway (Residual Net)
- Batch normalization
Weight normalization
随着研究的不断深入,深度学习还有着各种各样的变种和组件,上面是一些最新的关于深度学习的研究成果。
3.深度学习在实际项目中
我们讲讲深度学习在我们明略项目中的应用,我们有个很大的制造业客户,他们有个故障预测的项目,我们能做什么呢?深度学习除了建模的能力比普通的强一点,还可以学习时间序列的结构,设备传感器的数据是一个时间序列,每一秒钟或者多少毫秒产品信号,我们用传统的方法很难处理这么高纬度,这么大数据量的模型法国,深度学习可以理解在时间上的关系,大大提高我们对故障分类的预测。
另外一个就是在银行对不良客户检测的模型中,我们有数百维的储蓄、消费、信贷特征如果我们请专家来做非常困难,因为很多时候,当你的特征太多了,很难想到那么多规则的组合,用深度学习可以进行自动特征组合,比如说发现我的银行的储蓄额很高,但是可能在月底突然取出来了,可能就代表着我可能只是临时在里面,跟别人借的钱放在里面,并不是我有这么高的资金做抵押,这个时候发现的时候,就可以排除在外,这个可能就超过了很多行业专家的工作效率了。
深度学习对我们的DataInsight是前沿重要的方向,我们会推出软硬一体的解决方案,我们也会使用TESLA GPU做深度学习加速器。
Q1:深度学习看上去很复杂,对于新手应该怎么去学,能不能推荐一些深度学习方面的书籍和流行的框架?
A1:深度学习的数学理论其实并不复杂,但是需要注意的细节太多了,我们需要大量的时间来消化理解各个概念,对于新手,我推荐先上手代码,再研究原理,目前的深度学习框架非常之多,包括TensorFlow, theano, lasagne, keras, sknn, no learn, caffe, mxnet, leaf, torch7, convnetjs等。tensorflow目前是github上最火的框架,我本人也是TensorFlow前20的contributor, 但是目前并不推荐新手直接使用Tensorflow,新手最简单易用的框架是keras,没有之一,可以先看上面的tutorial上手代码,理论方面,可以先学习MIT最新出的 Deep Learnign的书来学习,这一本作者包括深度学习三巨头Bengio
Q2:dl在明略的具体应用场景,遇到的困难?
A2:DL在明略的应用确实不是完全一帆风顺,我们在部署搭建GPU集群来训练DL时就需要非常多的坑,现在我们的产品DataInsight可以自动的帮我们解决这个环境问题,在数据上,我们需要收集比较大量的数据,才可以让DL发挥出强大的威力,在数据上,我们需要收集比较大量的数据,才可以让DL发挥出强大的威力,量级起码需要在十万条数据以上,最好是百万以上,然后就是参数调试的问题,不同的网络结构,激活函数,dropout,learning rate,参数实在太多,可能对初学者来说,感觉像是噩梦,然而随着对DL理论的理解,我们可以清晰的指导自己调参的思路,选择一条最佳的道路去解决这个问题,什么时候用CNN,什么时候用RNN,什么时候用dropout,都是很有意思,并且很有内在道理的。能推荐几本书?或者资源吗? 关于这个问题,我推荐去github上有一个项目叫 awesome deeplearning,上面有非常多的关于DL的资源
Q3:请问现在对深度学习有一定理解,也有过相关经历用过keras等,请问怎么样更深入学习?
A3:如果对基础代码熟练了,可以尝试去学习DL各个变种以及组件的原理,并在比较底层的框架,如theano,tensofrflow上自己实现
Q4:我是深度学习的硕士,请问现在有哪些工作还可以去做?
A4:目前在NLP方向的研究还没有像CV和语音识别爆发起来,还存在很多灌水的空间
Q5:内存和数据库以及CPU是否是深度学习的瓶颈?如果是则使用什么数据库能达到相应性能?
A5:深度学习一般使用GPU训练,显存可能会成为瓶颈,数据库,cpu一般不会成为瓶颈
Q6:请问对于图像处理,是否用不到RNN? 这个问题很有意思
A6:RNN用于有时间上前后关系的序列,以及需要记忆的网络,很有优势,可以说的是,在视频中,肯定是可以用到的,还有刚才的图片问答的整体系统中,也是需要用到RNN的。
Q7:请问深度学习在能应用在教育大数据分析中吗
A7:DL基本可以用于任何数据集和问题,前提是有足够多的数据量,这个是最重要的瓶颈,
Q8:请问spark中那些可以在深度学习中应用呢?
A8:目前有很多应用在spark中的DL框架,包括Elephas(依赖Keras), SparkNet, CaffeOnSpark(依赖Caffe)
Q9:请问在图像处理领域,DL还有哪方面的事情可以去研究?
A9:目前比较火的一个方向是 图像生成,DCGAN, 还有利用DL进行去噪,甚至是超分辨率,去模糊等方面的研究
Q10:在relu等方法之后,一定程度上减轻了梯度扩散的问题,请问网络层数该如何选择(显然不是越多越好)?或者说,现阶段限制网络层数的主要原因有哪些?
A10:网络层数过深目前依然会带来一些问题,比如训练过难,局部最优,鞍点等问题,还有就是也有过拟合的可能,如果问题确实非常复杂,比如图片分类,我们可以使用resnet或者highway来训练超深的网络,如果是简单一些的问题,我们可以考虑在深层一些的网络中加入类似dropout, weight regularization等减轻过拟合.
Q11:我是新手,想问下深度学习需要哪些技术和理论基础?
A11:DL,首先需要在线性代数方面的基础知识,其次还有概率论,凸优化,基础数据挖掘概念等知识
Q12:DL在政务领域有哪些应用?
A12:可以参见MIT的Deep learning的书籍,里面有很基础的讲解,可以简单入门
Q13:与VR有什么交叉点吗?
A13:与VR关联可能不大,但是与AR关系很大,因为AR需要先识别出图像中的实体,再去进行augmentation增强,其中的识别需要用到DL
Q14:分布式环境上的深度学习,老师最推崇哪个?
A14:分布式的深度学习框架,最推荐tensorflow,在100台节点的gpu服务器集群上,tensorflow的总体性能是单节点的56倍,也就是可以达到56%的分布式效率,远超其他框架
Q15:先请问黄老师一个不正经的问题:有哪些任务目前为止的实验结果表明不适合DL?
A15:稀疏特征的数据上,DL并不适用,比如适用bag of words再接DL效果一就很差,还有一个就是小数据量上DL可能会严重欠拟合
Q16:话说对于一个大陆的学校的学生。如果本校没有什么出色老师研究这方面,怎么入门?
A16:建议先研究代码,先研读keras的tutorial中的sample code, 然后再读MIT的Deep Learning这本书,最后读论文,通过tensorflow或者theano复现论文的方法。
Q17:如何保证程序不被坏的数据教坏,比如垃圾数据,或者恶意构造的数据,以影响其本身的学习精度,就像微软的小冰,最近看到国外版本好像都要下线了,就是被人教坏了 .
A17:这个问题很有趣,目前确实没有什么特别好的办法解决这个问题,可能需要在网络结构上使用减轻过拟合的组件和策略,并且避免使用过大的learning rate和过小的batch size。
Q18: 请问黄老师 在金融风控征信方式 dl应用场景 能举些典型例子么
A18:在政务和金融领域的应用,比如使用DL实现自动的征信打分模型,政府或者银行拥有超大规模的数据,完全可以满足DL的需求,加上DL自动组合特征的能力,是完全可以在准确度上超过其他模型的。:
Q19:然而随着对DL理论的理解,我们可以清晰的指导自己调参的思路,选择一条最佳的道路去解决这个问题,可否稍微详细介绍下最佳道路?
A19:最重要的是网络结构,先设计好是用CNN还是RNN,用多深的网络,用不用maxpooling,接下来就是Activation 函数的选择了,目前比较好的是relu系列的,包括PRelu, Leaky Relu, RRelue, 另一个选择就是maxout.如果需要处理复杂问题,可以考虑highway或resnet,这两个可以训练非常深的网络,如果过拟合严重,可以考虑dropout或者regularization。最后,再考虑hidden layer unit number, learning rate等等
感谢杜小芳对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

