使用Windbg和Python进行堆跟踪
这篇文章主要展示如何使用 Windbg 的 Python 脚本,以及如何建立一个基本堆模拟器。所有代码可以从 这里 找到。
配置 PyKd
我们将使用PyKd的python库文件,这就可以让我们使用python和Windbg的API进行交流。首先你系统上要安装python2.7.10或者更早版本。当前PyKd兼容的最高版本是2.7.10,并且稳定性很高。现在下载PyKd安装包,就可以开始了。一旦你安装了PyKd,打开Windbg,随意附加一个进程(我使用Notepad++),接着使用 “!load pykd.pyd”加载PyKd。现在可以创建一个小的测试脚本:
import pykd print pykd.dbgCommand("!teb")
保存并执行
!py $path_to_script可以看到下面的内容:
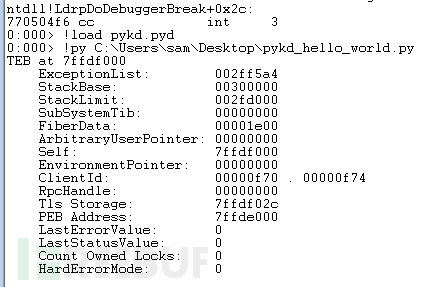
Hook 函数
我们准备通过在每个内存分配函数的入口和出口处设置断点来hook这些函数,收集一些我们需要的信息,然后再重新执行。首先我们创建一个函数能够得到所要hook函数的地址。
import pykd def get_address(localAddr): res = pykd.dbgCommand("x " + localAddr) result_count = res.count("/n") if result_count == 0: print localAddr + " not found." return None if result_count > 1: print "Warning, more than one result for " + localAddr return res.split()[0]
接着创建一个能够处理 hook 的类,这个类所处理的入口断点创建在构造函数里面。
class handle_allocate_heap(pykd.eventHandler): def __init__(self): addr = get_address("ntdll!RtlAllocateHeap") if addr == None: return self.bp_init = pykd.setBp(int(addr, 16), self.enter_call_back) self.bp_end = None
现在在 callback 函数里我们使用 pykd 找到函数的最后一行,并在该处设置断点。这就意味着 rerutn_call_back 函数在返回前被调用。从 callback 返回错误,我们让程序继续执行,如果返回值正确,将会停止执行。
def enter_call_back(self,bp): print "RtlAllocateHeap called." if self.bp_end == None: disas = pykd.dbgCommand("uf ntdll!RtlAllocateHeap").split('/n') for i in disas: if 'ret' in i: self.ret_addr = i.split()[0] break self.bp_end = pykd.setBp(int(self.ret_addr, 16), self.return_call_back) return False def return_call_back(self,bp): print "RtlAllocateHeap returned." return False
这个创建完毕后,我们所做的就是实例化这个类,当 Windbg 的 pykd 加载后将会进行 hook 初始化。
handle_allocate_heap() pykd.go()
在 windbg 中运行该脚本,我们可以看到在调用 RTlAllocateHeap 时就会被记录。

堆追踪
现在我们需要改善下代码,提取RTlAllocateHeap 传入的参数以及它的返回地址。当使用win32函数标准的调用规则时,参数被传入堆栈上,因此我们可以通过读取栈值来得到参数,如下:
def enter_call_back(self,bp): self.out = "RtlAllocateHeap(" esp = pykd.reg("esp") self.out += hex(pykd.ptrPtr(esp + 4)) + " , " self.out += hex(pykd.ptrMWord(esp + 0x8)) + " , " self.out += hex(pykd.ptrMWord(esp + 0xC)) + ") = " if self.bp_end == None: disas = pykd.dbgCommand("uf ntdll!RtlAllocateHeap").split('/n') for i in disas: if 'ret' in i: self.ret_addr = i.split()[0] break self.bp_end = pykd.setBp(int(self.ret_addr, 16), self.return_call_back) return False 在这个调用规则下,函数的返回值是保存在eax中,我们可以在这个值出现的那一刻将其提取出来,然后全部打印。 def return_call_back(self,bp): self.out += ") = " + hex(pykd.reg(return_reg)) print self.out return False
更新后的代码,再次运行如下所示。
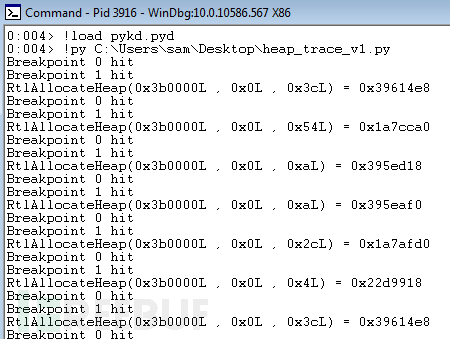
如图所示,分配结果还不是很好理解,我们可以看到相同的地址多次分配内存。这是由于我们只跟踪分配过程没有跟踪释放过程,所以我们同样为此添加一个hook(预测重分配),同样也支持Windows 64位的调用约定,而且更新了代码采用记事本记录而不是通过标准输出。代码如下:
import pykd from os.path import expanduser home = expanduser("~") return_reg = "rax" stack_pointer = "rsp" arch_bits = 64 log = None def get_address(localAddr): res = pykd.dbgCommand("x " + localAddr) result_count = res.count("/n") if result_count == 0: print localAddr + " not found." return None if result_count > 1: print "[-] Warning, more than one result for", localAddr return res.split()[0] #RtlAllocateHeap( # IN PVOID HeapHandle, # IN ULONG Flags, # IN ULONG Size ); class handle_allocate_heap(pykd.eventHandler): def __init__(self): addr = get_address("ntdll!RtlAllocateHeap") if addr == None: return self.bp_init = pykd.setBp(int(addr, 16), self.enter_call_back) self.bp_end = None def enter_call_back(self,bp): self.out = "RtlAllocateHeap(" if arch_bits == 32: esp = pykd.reg(stack_pointer) self.out += hex(pykd.ptrPtr(esp + 4)) + " , " self.out += hex(pykd.ptrMWord(esp + 0x8)) + " , " self.out += hex(pykd.ptrMWord(esp + 0xC)) + ") = " else: self.out += hex(pykd.reg("rcx")) + " , " self.out += hex(pykd.reg("rdx")) + " , " self.out += hex(pykd.reg("r8")) + ") = " if self.bp_end == None: disas = pykd.dbgCommand("uf ntdll!RtlAllocateHeap").split('/n') for i in disas: if 'ret' in i: self.ret_addr = i.split()[0] break self.bp_end = pykd.setBp(int(self.ret_addr, 16), self.return_call_back) return False def return_call_back(self,bp): log.write(self.out + hex(pykd.reg(return_reg)) + "/n") return False #RtlFreeHeap( #IN PVOID HeapHandle, #IN ULONG Flags OPTIONAL, #IN PVOID MemoryPointer ); class handle_free_heap(pykd.eventHandler): def __init__(self): addr = get_address("ntdll!RtlFreeHeap") if addr == None: return self.bp_init = pykd.setBp(int(addr, 16), self.enter_call_back) self.bp_end = None def enter_call_back(self,bp): self.out = "RtlFreeHeap(" if arch_bits == 32: esp = pykd.reg(stack_pointer) self.out += hex(pykd.ptrPtr(esp + 4)) + " , " self.out += hex(pykd.ptrMWord(esp + 0x8)) + " , " self.out += hex(pykd.ptrPtr(esp + 0xC)) + ") = " else: self.out += hex(pykd.reg("rcx")) + " , " self.out += hex(pykd.reg("rdx")) + " , " self.out += hex(pykd.reg("r8")) + ") = " if self.bp_end == None: disas = pykd.dbgCommand("uf ntdll!RtlFreeHeap").split('/n') for i in disas: if 'ret' in i: self.ret_addr = i.split()[0] break self.bp_end = pykd.setBp(int(self.ret_addr, 16), self.return_call_back) return False def return_call_back(self,bp): #returns a BOOLEAN which is a byte under the hood ret_val = hex(pykd.reg("al")) log.write(self.out + ret_val + "/n") return False #RtlReAllocateHeap( #IN PVOID HeapHandle, #IN ULONG Flags, # IN PVOID MemoryPointer, # IN ULONG Size ); class handle_realloc_heap(pykd.eventHandler): def __init__(self): addr = get_address("ntdll!RtlReAllocateHeap") if addr == None: return self.bp_init = pykd.setBp(int(addr, 16), self.enter_call_back) self.bp_end = None def enter_call_back(self,bp): self.out = "RtlReAllocateHeap(" if arch_bits == 32: esp = pykd.reg(stack_pointer) self.out += hex(pykd.ptrPtr(esp + 4)) + " , " self.out += hex(pykd.ptrMWord(esp + 0x8)) + " , " self.out += hex(pykd.ptrPtr(esp + 0xC)) + " , " self.out += hex(pykd.ptrMWord(esp + 0x10)) + ") = " else: self.out += hex(pykd.reg("rcx")) + " , " self.out += hex(pykd.reg("rdx")) + " , " self.out += hex(pykd.reg("r8")) + " , " self.out += hex(pykd.reg("r9")) + ") = " if self.bp_end == None: disas = pykd.dbgCommand("uf ntdll!RtlReAllocateHeap").split('/n') for i in disas: if 'ret' in i: self.ret_addr = i.split()[0] break self.bp_end = pykd.setBp(int(self.ret_addr, 16), self.return_call_back) return False def return_call_back(self,bp): log.write(self.out + hex(pykd.reg(return_reg)) + "/n") return False log = open(home + "/log.log","w+") try: pykd.reg("rax") except: arch_bits = 32 return_reg = "eax" stack_pointer = "esp" handle_allocate_heap() handle_free_heap() handle_realloc_heap() pykd.go()
使用windbg attach notepad++,运行代码,日志记录如下:
RtlFreeHeap(0xb20000L , 0x0L , 0xb33eb8L) = 0x1 RtlAllocateHeap(0x230000L , 0x0L , 0x3cL) = 0x24c8570 RtlFreeHeap(0x230000L , 0x0L , 0x24cc4d8L) = 0x1 RtlFreeHeap(0x230000L , 0x0L , 0x24cc4a0L) = 0x1 RtlFreeHeap(0x230000L , 0x0L , 0x24744d0L) = 0x1 RtlFreeHeap(0x230000L , 0x0L , 0xc87d28L) = 0x1 RtlAllocateHeap(0x230000L , 0x0L , 0x54L) = 0xc87d28 RtlAllocateHeap(0x230000L , 0x0L , 0x11L) = 0x2468cf8 RtlAllocateHeap(0x230000L , 0x0L , 0x11L) = 0x2468c58 RtlAllocateHeap(0x230000L , 0x0L , 0x48L) = 0x24d94e8 RtlAllocateHeap(0x230000L , 0x0L , 0x4L) = 0x24794c0 RtlFreeHeap(0x230000L , 0x0L , 0x24794c0L) = 0x1 RtlFreeHeap(0x230000L , 0x0L , 0x24c8570L) = 0x1 RtlAllocateHeap(0x230000L , 0x0L , 0x3cL) = 0x24c8570 RtlFreeHeap(0x230000L , 0x0L , 0x24c8570L) = 0x1 RtlAllocateHeap(0x230000L , 0x0L , 0x3cL) = 0x24c8570 RtlFreeHeap(0x230000L , 0x0L , 0x24c8570L) = 0x1 RtlAllocateHeap(0x230000L , 0x0L , 0x3cL) = 0x24c8570 RtlFreeHeap(0x230000L , 0x0L , 0x24c8570L) = 0x1 RtlAllocateHeap(0x230000L , 0x0L , 0x3cL) = 0x24c8570 RtlFreeHeap(0x230000L , 0x0L , 0x24c8570L) = 0x1 RtlAllocateHeap(0x230000L , 0x0L , 0x3cL) = 0x24c8570 RtlFreeHeap(0x230000L , 0x0L , 0x24c8570L) = 0x1 RtlAllocateHeap(0x230000L , 0x0L , 0x3cL) = 0x24c8570 RtlFreeHeap(0x230000L , 0x0L , 0x24c8570L) = 0x1
很棒有没有,看起来我们的堆追踪正在工作,日志样本可以在这里 找到 。
可视化堆
使用修改后的版本 villoc heap visualiser ,我们可以将信息转存到HTML图表上。我们使用 ” python villoc.py sample.log out.html ” 来获得这些信息,下面可以看到输出的HTML部分数据块。本例中,一个单独的块重复被释放和分配。
这只是跟踪到的部分信息,完整信息可以在 这里 找到,下载之后在浏览器中可以正确的查看,修改后的villoc.py可以在 这里 找到。
开销
我想知道在运行程序时附带上堆跟踪和附加调试器进行比对其开销情况。不出所料,答案是很大。因此我做了一个定时,在运行IE9时,通过一个基本的堆喷射来看其表现。首先附加上调试器然后开始堆跟踪。我使用取自Corelan的堆喷射,在喷射的开始和结束修改 “parseFloat”,
这个调用用于触发已设定的函数”jscript9 ! StrToDbl”断点,让我们知道什么时候喷即将开始,以及何时结束。
<html> <script language="javascript"> // heap spray test script // corelanc0d3r //Original source: https://www.corelan.be/index.php/2011/12/31/exploit-writing-tutorial-part-11-heap-spraying-demystified/#Visualizing_the_heap_spray_8211_IE6 var a = parseFloat("10"); tag = unescape('%u4F43%u4552'); // CORE tag += unescape('%u414C%u214E'); // LAN! chunk = ''; chunksize = 0x1000; nr_of_chunks = 200; for ( counter = 0; counter < chunksize; counter++) { chunk += unescape('%u9090%u9090'); //nops } document.write("size of NOPS at this point : " + chunk.length.toString() + "<br>"); chunk = chunk.substring(0,chunksize - tag.length); document.write("size of NOPS after substring : " + chunk.length.toString() + "<br>"); // create the array testarray = new Array(); for ( counter = 0; counter < nr_of_chunks; counter++) { testarray[counter] = tag + chunk; document.write("Allocated " + (tag.length+chunk.length).toString() + " bytes <br>"); } var b = parseFloat("10"); </script> </html>
我用下面的脚本只是附加调试器来获得运行时间。然后我用的堆跟踪脚本,其中包括相同的时序逻辑做堆跟踪相同的修改版本,定时脚本可以在 这里 找到。
import pykd import timeit start = timeit.default_timer() def get_address(localAddr): res = pykd.dbgCommand("x " + localAddr) result_count = res.count("/n") if result_count == 0: print localAddr + " not found." return None if result_count > 1: print "[-] Warning, more than one result for", localAddr return res.split()[0] class time(pykd.eventHandler): def __init__(self): addr = get_address("jscript9!StrToDbl") if addr == None: return self.start = timeit.default_timer() self.bp_init = pykd.setBp(int(addr, 16), self.enter_call_back) def enter_call_back(self,bp): end = timeit.default_timer() print "Heap spray took: " + str(end - self.start) return True time() pykd.go()
多次运行的每个定时脚本并取时间的平均后,附加调试器运行时间为0.016秒,堆跟踪调试运行时间为17.1秒。给出的粗略结果约1000倍的总开销(精确为1046.46)。多次运行的每个定时脚本并取时间的平均后,附加调试器运行时间为0.016秒,堆跟踪调试运行时间为17.1秒。给出的粗略结果约1000倍的总开销(精确为1046.46)。
可视化堆喷射
为了将跟ie_execcommand_uaf踪脚本ie_execcommand_uaf和villoc的输出结合,我在windows7 32位sp1 IE9上运行跟踪脚本,而这个版本的是存在一个ie_execcommand_uaf漏洞,具体可以在Metasploit上看到(详情漏洞利用可以在这里找到)。我们可以在生成的可视化堆中看到这个漏洞使用堆喷射的方式利用。例如,在下面的两张图片中我们可以看到通过某种指定的方式连续分配内存。


完整的跟踪文件,见 “ie_execcommand_uaf.zip” 。
在利用漏洞的过程中,堆跟踪也将是很有用的。例如,当利用MS15-061,Windows Kernel Use-After-Free漏洞(完整的细节请看 白皮书 ),Dominic Wang使用了好几个Wind存bg脚本来监控用户态堆并确保可以被操控。
结论
能够快速创建和修改现有的脚本调试器在漏洞分析和利用过程将是一个利器,使得能够开发获得目标软件的状态以及更深入的了解这些有用工具。 Villoc Visualiser 在利用和分析的过程中虽然开销很大,但提供了一个简单的基于堆的攻击复杂的方法,使得过程更加清晰。
*参考来源: mwrinfosecurity ,FB小编老王隔壁的白帽子翻译,转载请注明来自FreeBuf黑客与极客(FreeBuf.COM)
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

