Hadoop 单机伪集群配置试验和分析
同步发在:
https://evergreen-tree.github.io/articles/2016-05/daily-hadoop-singleNode-setup
以下内容摘自网路:
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。 用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统( Hadoop Distributed File System ),简称 HDFS 。 HDFS 有高容错性的特点,并且设计用来部署在低廉的( low-cost )硬件上;而且它提供高吞吐量( high throughput )来访问应用程序的数据,适合那些有着超大数据集( large data set )的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是: HDFS 和 MapReduce 。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。。
从网络上摘抄出来的内容看出来,hadoop的确已经完全形成了自己的体系。
从准备开始学习hadoop到真正开始使用hadoop的过程中感觉自己走了很多弯路,其中最主要的一个就是一直以来把hadoop当成了一款开源软件来进行学习,开源软件学习的过程一般是通过阅读 tutorial(说明书) 来进行最初的设定,并且完成最基本的接入操作,然后逐步深入,阅读和使用分布式的配置,阅读和使用更多的feature。例如学习activeMQ,就可以通过阅读user guide来完成入门,然后通过阅读配置部分加java的demo,基本完成对于activemq的设定和使用,可是这一招在面对hadoop的时候失效了。
为什么失效?这是个让我很头痛的问题,后来经过一系列的学习和分析终于对hadoop有所掌握之后发现hadoop实际上不是一款开源软件,而是一个分布式运算的体系或者平台,我们可以把hadoop认为是 一种分布式运算的操作系统 ,提供了很多底层的API的定义,然后在hadoop这个体系的内部呢,有很多的开源软件的实现,比如mapreduce,比如hdfs,比如yarn等等,这些软件被集成在hadoop平台内部,从而通过hadoop平台的分配掉用来完成真正的工作。当然了上面的说法可能不尽准确,但是这样进行思考可以让你更快的学会使用hadoop。
通过上面的说法我们可以制定接下里的方向,操作系统我们要学习的当然是命令了,就是hadoop基本的CLI的命令(具体的命令见附件部分)。通过这一系列的命令我们可以操作在hadoop这个系统中的文件,以及执行一些特定的操作,甚至于运行我们自己编写的软件(如jar命令)。
学习完操作系统,接下来要想做事情就需要学习运行在操作系统上面的软件了,比如我们的硬盘存储HDFS,比如我们的资源管理和计算操作软件YARN,通过学习逐渐的发觉,学习hadoop其实就是学习HDFS跟MAPREDUCE的过程,因为实际上启动hadoop就是启动hadoop的存储并运行分布式运算的过程。
扯了这么多,我们现在先回来感受一把hadoop的魅力:
首先要说明一点的就是hadoop的更新实在太快了,所以网络上面很多的文章已经不是特别的准确,如果需要阅读相关的文档,英文够好的话建议直接阅读发行包里面的文档,它就在你下载的发行包的 share/doc 底下。
另外不建议大家再windows下玩儿hadoop,有条件的最好安装linux操作系统,或者使用虚拟机,没有条件的也建议使用cygwin而不是在windows下使用bat进行操作。
单点启动方式
hadoop下载完成之后并不是说下载了操作系统,然后需要安装软件,它的软件是集成在里面的。比如我们下载的2.6.4的发型包里面就是集成了HDFS跟YARN的。
hadoop下载完成之后,不需要任何的配置即可以单点方式运行,这时候hadoop并不会启动hdfs跟yarn或者maprduce,而仅仅以单一的java进程来处理你的命令。
$ mkdir input $ cp etc/hadoop/*.xml input $ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep input output 'dfs[a-z.]+' $ cat output/* 上面的命令可以让你体验一下hadoop居然是可以运行的,唯一的前提条件是你要安装过JAVA,并且配置了JAVA_HOME.
简单介绍一下上面的命令所体现出来的内容:
- mdkir和cp部分是新建一个来源文件目录
- 紧跟其后的hadoop jar命令,指定hadoop装载本地的一个jar文件并且以mapreduce的方式运行该jar中的mapreduce对象(具体该jar怎么被创建出来后面的章节会介绍)。
- grep命令是demo里面所需要的运行时参数,input是输入文件的路径,output是结果的输出路径,最后的正则表达式是grep的规则。也就是说希望hadoop将input中所有的文件通过提供的正则表达式的规则过滤到output中。
- 最后是检查在output中到底有什么内容:
运行cat之后的结果如下(看起来所有的文件中存在dfs[a-z.]+正则匹配的只是出现了一次,这次叫做dfsadmin)
1 dfsadmin 伪分布式单机启动
上面的启动方式当然不够炫酷,而且单机运行的时候实际上除了有个结果之外并没法让你看到任何hadoop的痕迹,所以hadoop提供了第二种单机运行的方式,伪分布式,在伪分布式中,hadoop将会启动两个进程,一个为hdfs进程,一个为mapreduce的管理进程,如果已经配置了yarn的,那么将会启动的就是yarn的进程。
启动一个分布式的hadoop的过程其实就是分别启动hadoop的四个基本元素的过程,即
- NameNode
- DataNode
- ResourceManager
- NodeManager
其中,NameNode & DataNode在默认的发行版里面是通过start-dfs来完成,即NameNode&DataNode是HDFS的组成部分,而ResourceManager&NodeManager发行版里面有默认的实现以及yarn,鉴于官方的文档也建议使用yarn来进行资源管理,我们的配置也使用yarn进行配置。
依次更改下面的配置文件:
etc/hadoop/core-site.xml(基本配置,这个配置文件在集群里面所有的机器应该配置为相同的): ```xml
fs.defaultFS hdfs://localhost:9000
etc/hadoop/hdfs-site.xml(在NameNode/DataNode不同的配置文件,我们现在通过一台机器进行模拟,所以不需要进行多余的配置): ```xml <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration> 至此我们没有使用yarn进行mapreduce的操作,而是使用hadoop默认的mapreduce,如果需要使用其他的mapreduce实现,那么需要修改: etc/hadoop/mapred-site.xml
这个文件的修改我们接下里会说。
完成上面两个文件的修改之后,我们就拥有了一个伪分布式的环境,在这个环境里面NameNode,DataNode,ResourceManger跟NodeManager都分别以独立的进程来运行。
接下来我们来运行我们的hadoop操作系统。
因为hadoop是通过ssh来进行各个节点的启动和停止操作的,所以需要ssh的支持,为了简单起见我们可以设置ssh免密码登陆,具体的原理请参照 https://evergreen-tree.github.io/articles/2016-05/daily-ssh-authorized-keys 。
我们本地需要设置的是对于localhost的免密码登陆:
依次执行下面的命令即可
$ ssh localhost If you cannot ssh to localhost without a passphrase, execute the following commands: $ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys - 第一步,格式化硬盘(格式化NameNode)
-
bin/hdfs namenode -format
-
- 第二步,启动硬盘管理系统(启动hdfs)
-
sbin/start-dfs.sh - 硬盘(HDFS)管理器启动之后,有一个UI可以让你更加直观的看到本地hdfs里面的内容,访问方式如下:
- http://localhost:50070/
-
- 第三步,硬盘 (HDFS)启动成功之后通过操作系统(hadoop)来向硬盘写入数据以备计算使用。(这一步官方的文档存在bug,最好使用我给的命令)
-
bin/hdfs dfs -mkdir /user- 创建工作目录 -
bin/hdfs dfs -mkdir /user/test- 创建工作目录,按照官方文档,这里面新建的目录应该是当前linux系统登录的用户,为了区别起见,我们使用test -
bin/hdfs dfs -put etc/hadoop /user/test/input- 将本地文件导入到hadoop系统中的HDFS
-
- 第四步,重新运行我们在单点模式的时候运行的JOB
-
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep /user/test/input output 'dfs[a-z.]+' - 在上面单点运行的时候结果会直接被写入到运行命令的当前目录的output文件夹,但是在使用hadoop执行命令的时候,命令其实是被运行在了hadoop系统里面,所以结果被写入到了hadoop平台的output文件夹里面
-
- 检查成果
-
bin/hdfs dfs -cat output/* - 最终的结果会被写入到
/user/root/output默认是linux的登陆用户的用户名。
-
- 如果不想继续了请关闭
sbin/stop-dfs.sh
对上面的操作进行一些分析:
启动dfs之后,其实在后台启动了NameNode跟SecondNameNode(secondNameNode是NameNode的容灾)
root 24225 1 17 14:28 ? 00:00:07 /etc/alternatives/java_sdk/bin/java -Dproc_namenode -Xmx1000m -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/opt/hadoop-2.6.4/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/opt/hadoop-2.6.4 -Dhadoop.id.str=root -Dhadoop.root.logger=INFO,console -Djava.library.path=/opt/hadoop-2.6.4/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/opt/hadoop-2.6.4/logs -Dhadoop.log.file=hadoop-root-namenode-localhost.localdomain.log -Dhadoop.home.dir=/opt/hadoop-2.6.4 -Dhadoop.id.str=root -Dhadoop.root.logger=INFO,RFA -Djava.library.path=/opt/hadoop-2.6.4/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS org.apache.hadoop.hdfs.server.namenode.NameNode root 24326 1 21 14:28 ? 00:00:08 /etc/alternatives/java_sdk/bin/java -Dproc_datanode -Xmx1000m -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/opt/hadoop-2.6.4/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/opt/hadoop-2.6.4 -Dhadoop.id.str=root -Dhadoop.root.logger=INFO,console -Djava.library.path=/opt/hadoop-2.6.4/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/opt/hadoop-2.6.4/logs -Dhadoop.log.file=hadoop-root-datanode-localhost.localdomain.log -Dhadoop.home.dir=/opt/hadoop-2.6.4 -Dhadoop.id.str=root -Dhadoop.root.logger=INFO,RFA -Djava.library.path=/opt/hadoop-2.6.4/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -server -Dhadoop.security.logger=ERROR,RFAS -Dhadoop.security.logger=ERROR,RFAS -Dhadoop.security.logger=ERROR,RFAS -Dhadoop.security.logger=INFO,RFAS org.apache.hadoop.hdfs.server.datanode.DataNode root 24529 1 17 14:28 ? 00:00:05 /etc/alternatives/java_sdk/bin/java -Dproc_secondarynamenode -Xmx1000m -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/opt/hadoop-2.6.4/logs -Dhadoop.log.file=hadoop.log -Dhadoop.home.dir=/opt/hadoop-2.6.4 -Dhadoop.id.str=root -Dhadoop.root.logger=INFO,console -Djava.library.path=/opt/hadoop-2.6.4/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Stack=true -Dhadoop.log.dir=/opt/hadoop-2.6.4/logs -Dhadoop.log.file=hadoop-root-secondarynamenode-localhost.localdomain.log -Dhadoop.home.dir=/opt/hadoop-2.6.4 -Dhadoop.id.str=root -Dhadoop.root.logger=INFO,RFA -Djava.library.path=/opt/hadoop-2.6.4/lib/native -Dhadoop.policy.file=hadoop-policy.xml -Djava.net.preferIPv4Stack=true -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode 进入tmp目录会发现有下面的目录结构:
[root@localhost tmp]# ll drwxr-xr-x. 3 root root 4096 May 25 14:28 hadoop-root -rw-r--r--. 1 root root 6 May 25 14:28 hadoop-root-datanode.pid -rw-r--r--. 1 root root 6 May 25 14:28 hadoop-root-namenode.pid -rw-r--r--. 1 root root 6 May 25 14:28 hadoop-root-secondarynamenode.pid drwxr-xr-x. 2 root root 4096 May 25 14:28 hsperfdata_root drwxr-xr-x. 4 root root 4096 May 25 14:28 Jetty_0_0_0_0_50070_hdfs____w2cu08 drwxr-xr-x. 4 root root 4096 May 25 14:28 Jetty_0_0_0_0_50075_datanode____hwtdwq drwxr-xr-x. 4 root root 4096 May 25 14:28 Jetty_0_0_0_0_50090_secondary____y6aanv 通过UI界面(http://10.132.65.77:50070/)(我的UI)我们可以看到现在机器上面已经启动了一个datanode:
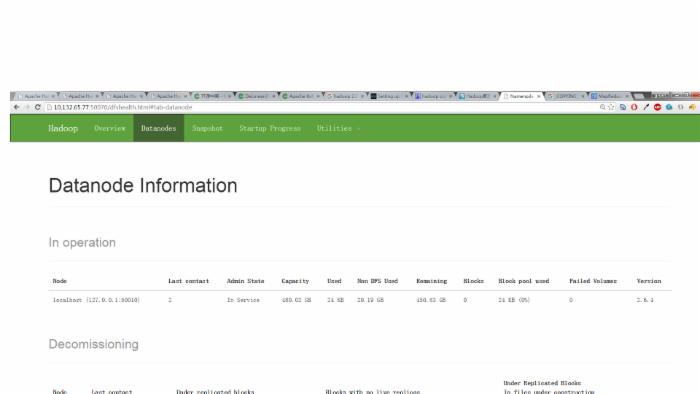
然后执行完所有的命令之后我们看到的结果如下;
[root@localhost hadoop]# bin/hdfs dfs -cat output/* 16/05/25 14:34:35 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable cat: `output/output': No such file or directory 6 dfs.audit.logger 4 dfs.class 3 dfs.server.namenode. 2 dfs.period 2 dfs.audit.log.maxfilesize 2 dfs.audit.log.maxbackupindex 1 dfsmetrics.log 1 dfsadmin 1 dfs.servers 1 dfs.replication 1 dfs.file 至此我们已经完成了通过一台机器启动NameNode & DataNode的过程,secondNameNode的启动大家可以暂时先忽略掉,我们看到如果不想要使用特定的mapreduce方案,那么只要启动namenode跟datanode即可。
通过刚才的设置,我们已经搭建好一个基本的运行环境,如果你刚才设置core-site.xml的时候绑定的是0.0.0.0那么你现在已经可以通过下面的java方法来远程连接你的hdfs并且进行一些简单的操作了!
package distributed.lock.hadoopJob; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import java.io.InputStream; import java.net.URI; public class HDFSTest { public static void main(String[] args) throws Exception { String uri = "hdfs://10.132.65.77:9000/"; Configuration config = new Configuration(); FileSystem fs = FileSystem.get(URI.create(uri), config); FileStatus[] statuses = fs.listStatus(new Path("/user/root")); for (FileStatus status : statuses) { System.out.println(status); } FSDataOutputStream os = fs.create(new Path("/user/root/input/test.log")); os.write("Hello World!".getBytes()); os.flush(); os.close(); InputStream is = fs.open(new Path("/user/root/test.log")); IOUtils.copyBytes(is, System.out, 1024, true); } } 上面的类我在执行的时候发生了一些小问题,不过用来验证可以进行连接操作还是蛮好的。不深究了。
使用yarn进行mapreduce
在使用yarn之前,建议首先删除掉原来的/tmp的所有文件并且重新format
依次修改下面的配置文件:
etc/hadoop/mapred-site.xml - 指定使用yarn作为mapreduce的调度者
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> etc/hadoop/yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> 然后启动yarn即可 sbin/start-yarn.sh (上面的dfs需要重启)
启动yarn之后,会发觉多出来两个进程(ResourceManager跟NodeManager):
root 29518 1 99 15:08 pts/2 00:00:09 /etc/alternatives/java_sdk/bin/java -Dproc_resourcemanager -Xmx1000m -Dhadoop.log.dir=/opt/hadoop-2.6.4/logs -Dyarn.log.dir=/opt/hadoop-2.6.4/logs -Dhadoop.log.file=yarn-root-resourcemanager-localhost.localdomain.log -Dyarn.log.file=yarn-root-resourcemanager-localhost.localdomain.log -Dyarn.home.dir= -Dyarn.id.str=root -Dhadoop.root.logger=INFO,RFA -Dyarn.root.logger=INFO,RFA -Djava.library.path=/opt/hadoop-2.6.4/lib/native -Dyarn.policy.file=hadoop-policy.xml -Dhadoop.log.dir=/opt/hadoop-2.6.4/logs -Dyarn.log.dir=/opt/hadoop-2.6.4/logs -Dhadoop.log.file=yarn-root-resourcemanager-localhost.localdomain.log -Dyarn.log.file=yarn-root-resourcemanager-localhost.localdomain.log -Dyarn.home.dir=/opt/hadoop-2.6.4 -Dhadoop.home.dir=/opt/hadoop-2.6.4 -Dhadoop.root.logger=INFO,RFA -Dyarn.root.logger=INFO,RFA -Djava.library.path=/opt/hadoop-2.6.4/lib/native -classpath /opt/hadoop-2.6.4/etc/hadoop:/opt/hadoop-2.6.4/etc/hadoop:/opt/hadoop-2.6.4/etc/hadoop:/opt/hadoop-2.6.4/share/hadoop/common/lib/*:/opt/hadoop-2.6.4/share/hadoop/common/*:/opt/hadoop-2.6.4/share/hadoop/hdfs:/opt/hadoop-2.6.4/share/hadoop/hdfs/lib/*:/opt/hadoop-2.6.4/share/hadoop/hdfs/*:/opt/hadoop-2.6.4/share/hadoop/yarn/lib/*:/opt/hadoop-2.6.4/share/hadoop/yarn/*:/opt/hadoop-2.6.4/share/hadoop/mapreduce/lib/*:/opt/hadoop-2.6.4/share/hadoop/mapreduce/*:/etc/alternatives/java_sdk/lib/tools.jar:/contrib/capacity-scheduler/*.jar:/contrib/capacity-scheduler/*.jar:/contrib/capacity-scheduler/*.jar:/opt/hadoop-2.6.4/share/hadoop/yarn/*:/opt/hadoop-2.6.4/share/hadoop/yarn/lib/*:/opt/hadoop-2.6.4/etc/hadoop/rm-config/log4j.properties org.apache.hadoop.yarn.server.resourcemanager.ResourceManager root 29623 1 99 15:08 ? 00:00:09 /etc/alternatives/java_sdk/bin/java -Dproc_nodemanager -Xmx1000m -Dhadoop.log.dir=/opt/hadoop-2.6.4/logs -Dyarn.log.dir=/opt/hadoop-2.6.4/logs -Dhadoop.log.file=yarn-root-nodemanager-localhost.localdomain.log -Dyarn.log.file=yarn-root-nodemanager-localhost.localdomain.log -Dyarn.home.dir= -Dyarn.id.str=root -Dhadoop.root.logger=INFO,RFA -Dyarn.root.logger=INFO,RFA -Djava.library.path=/opt/hadoop-2.6.4/lib/native -Dyarn.policy.file=hadoop-policy.xml -server -Dhadoop.log.dir=/opt/hadoop-2.6.4/logs -Dyarn.log.dir=/opt/hadoop-2.6.4/logs -Dhadoop.log.file=yarn-root-nodemanager-localhost.localdomain.log -Dyarn.log.file=yarn-root-nodemanager-localhost.localdomain.log -Dyarn.home.dir=/opt/hadoop-2.6.4 -Dhadoop.home.dir=/opt/hadoop-2.6.4 -Dhadoop.root.logger=INFO,RFA -Dyarn.root.logger=INFO,RFA -Djava.library.path=/opt/hadoop-2.6.4/lib/native -classpath /opt/hadoop-2.6.4/etc/hadoop:/opt/hadoop-2.6.4/etc/hadoop:/opt/hadoop-2.6.4/etc/hadoop:/opt/hadoop-2.6.4/share/hadoop/common/lib/*:/opt/hadoop-2.6.4/share/hadoop/common/*:/opt/hadoop-2.6.4/share/hadoop/hdfs:/opt/hadoop-2.6.4/share/hadoop/hdfs/lib/*:/opt/hadoop-2.6.4/share/hadoop/hdfs/*:/opt/hadoop-2.6.4/share/hadoop/yarn/lib/*:/opt/hadoop-2.6.4/share/hadoop/yarn/*:/opt/hadoop-2.6.4/share/hadoop/mapreduce/lib/*:/opt/hadoop-2.6.4/share/hadoop/mapreduce/*:/etc/alternatives/java_sdk/lib/tools.jar:/contrib/capacity-scheduler/*.jar:/contrib/capacity-scheduler/*.jar:/opt/hadoop-2.6.4/share/hadoop/yarn/*:/opt/hadoop-2.6.4/share/hadoop/yarn/lib/*:/opt/hadoop-2.6.4/etc/hadoop/nm-config/log4j.properties org.apache.hadoop.yarn.server.nodemanager.NodeManager tmp下面也增加了相应的pid等文件:
drwxr-xr-x. 4 root root 4096 May 25 15:08 hadoop-root -rw-r--r--. 1 root root 6 May 25 15:07 hadoop-root-datanode.pid -rw-r--r--. 1 root root 6 May 25 15:07 hadoop-root-namenode.pid -rw-r--r--. 1 root root 6 May 25 15:07 hadoop-root-secondarynamenode.pid drwxr-xr-x. 2 root root 4096 May 25 15:08 hsperfdata_root drwxr-xr-x. 4 root root 4096 May 25 15:07 Jetty_0_0_0_0_50070_hdfs____w2cu08 drwxr-xr-x. 4 root root 4096 May 25 15:07 Jetty_0_0_0_0_50075_datanode____hwtdwq drwxr-xr-x. 4 root root 4096 May 25 15:07 Jetty_0_0_0_0_50090_secondary____y6aanv drwxr-xr-x. 5 root root 4096 May 25 15:08 Jetty_0_0_0_0_8042_node____19tj0x drwxr-xr-x. 5 root root 4096 May 25 15:08 Jetty_0_0_0_0_8088_cluster____u0rgz3 -rw-r--r--. 1 root root 6 May 25 15:08 yarn-root-nodemanager.pid -rw-r--r--. 1 root root 6 May 25 15:08 yarn-root-resourcemanager.pid 正文到此结束
- 本文标签: IDE XML 开发 http Service 正则表达式 windows grep apr 数据 DOM 操作系统 core Property linux Hadoop tar secondarynamenode 开源软件 App 参数 src Security classpath Datanode UI CTO 快的 lib ActiveMQ root https Namenode 基金 GitHub 软件 dist Job apache git HDFS API list example 下载 ssh ip 集群 配置 管理 value 同步 文章 java jetty cat 安装 大数据 key 开源 删除 ORM 目录 node 进程 map
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

