Hypernetes:为Kubernetes带来安全性与多租户机制
尽管很多开发者与安全专家乐于强调Linux容器所拥有的明确边界,但大多数用户仍然希望进一步提升其隔离性水平,特别是在多租户运行环境当中。遗憾的是,目前这部分用户仍不得不将容器运行在虚拟机当中,有些甚至采取了容器与虚拟机一对一的包装方式。
这种作法直接影响到了云原生应用的诸多固有优势:包装在容器外面的虚拟机拖慢了服务的启动速度,带来更多的内存消耗,集群的资源利用率也无法得到有的效保证。
在今天的文章中,我们将介绍HyperContainer这种基于虚拟化技术的容器实现,了解它如何契合于Kubernetes的设计理念并帮助用户直接为使用者提供一套虚拟化技术加持的容器——而不是将它们打包进虚拟机当中。
HyperContainer
HyperContainer 是一款基于虚拟化技术的容器方案,它允许大家利用现有标准虚拟化管理程序(包括KVM与Xen等)来启动Docker镜像。作为开源项目,HyperContainer由一套名为 runV 的 OCI 标准容器运行时和一个名为 hyperd 的守护程序共同构成。HyperContainer的设计思路非常明确:它要将虚拟化与容器两项技术的优势结合起来。
其实,我们可以将所有容器都看作由两大部分组成(Kubernetes正是这么设计的)。第一部分称为容器运行时,这里HyperContainer利用虚拟化技术(而非namespaces与cgroups)实现隔离与资源限制。另一部分称为应用数据,HyperContainer使用的是Docker镜像。因此在HyperContainer当中,虚拟化技术能够构建出完全隔离的沙箱环境和独立的用户kernel(这也意味着’top’指令及/proc文件系统在Hyper容器中都是正常工作的)。但从开发者的角度来看,其使用感受及可移植性则与标准容器保持一致。
HyperContainer原生支持Pod
HyperContainer的有趣之处在于,它不仅能够为多租户环境(例如公有云)带来理想的安全保障,同时也能够很好地契合Kubernetes的设计理念。
Kubernetes当中最为重要的概念就是Pod,而Pod的设计思想则源自Google公司著名的Borg系统对真实世界工作负载进行抽象得出的结论( 见Borg论文8.1节 ),即在大多数情况下用户都希望能够将多个紧密协作的容器打包称为一个原子的调度单元来进行管理。当使用Linux容器时,Kubernetes Pod负责将多个容器打包并封装成为一个逻辑组。而在HyperContainer当中,虚拟机则被用来充当这组容器的天然边界,从而使得Pod能够则作为HyperContainer的顶级对象:
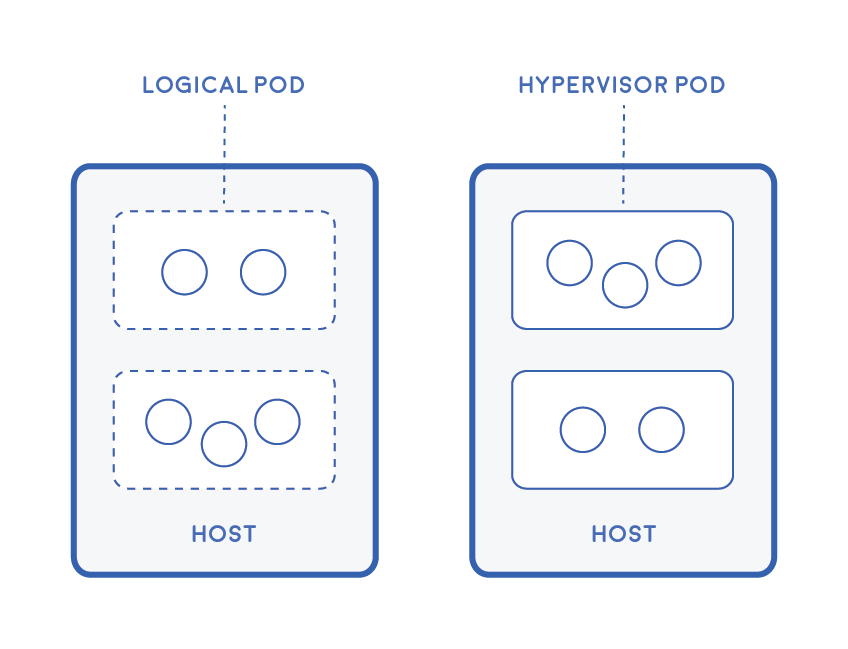
HyperContainer将多个轻量化应用容器打包成一个Pod,并在Pod级别来暴露容器操作的接口。在Pod当中,一个名为HyperKernel的极小Linux内核会被启动。而这个HyperKernel责由HyperStart这个轻量的Init服务来负责构建,HyperStart会作为PID 1的进程存在并创建Pod本体、设置Mount namespace、根据载入的镜像启动各应用。
这套模式能够与Kubernetes十分顺畅地对接。一旦将HyperContainer与Kubernetes相结合,就构成了我们在标题中提到的“ Hypernetes ”项目。
Hypernetes
Kubernetes的一个最大优势在于它是目前唯一支持多容器运行时的编排管理框架,这意味着用户不会被锁定在单一的容器技术提供商上。在这里我们很高兴地宣布,我们已经与Kubernetes团队达成合作关系,共同将HyperContainter整合至Kubernetes主干当中。这些合作工作包括了:
- 容器运行时优化与重构
- 新的客户端-服务器模式运行时接口
- 集成containerd并支持runV
尽管HyperContainer并非基于Linux容器技术堆栈所构建,但OCI标准和Kubernetes的多运行时架构使得这一整合过程非常顺利。
在另一方面,为了在多租户环境下运行HyperContainer,我们还创建了一款新的Kubernetes网络插件,并对现有的存储插件做了修改。由于Hypernetes直接使用虚拟机来作为Pod,它能够直接利用现有的成熟IaaS层技术来提供多租户网络及持久化卷存储。目前Hypernetes实现方案采用了标准的OpenStack组件。
接下来,我们将进一步探讨具体实现细节。
身份验证与授权
在Hypernetes当中,我们选择了 Keystone 来管理不同租户并在管理操作流程中执行身份验证任务。由于Keystone源自OpenStack生态系统,因此它能够同Hypernetes中使用的网络与存储插件进行无缝协作。
多租户网络模型
对于多租户容器集群,每位租户都拥有与其他租户完全隔离的自有网络环境。在Hypernetes中,每位租户亦拥有自己的Network。相较于利用OpenStack配置网络的复杂作法,Hypernetes只需要创建一个Network对象即可,具体如下:
apiVersion: v1
kind: Network
metadata:
name: net1
spec:
tenantID: 065f210a2ca9442aad898ab129426350
subnets:
subnet1:
cidr: 192.168.0.0/24
gateway: 192.168.0.1
请注意,其中的tenantID由Keystone负责提供。在个yaml将创建一个新的Neutron网络,并使用默认路由与192.168.0.0/24子网。
对于由用户创建的任意Network对象,都将由我们所新增的Kubernetes Network控制器(Network Controller)来负责其生命周期管理工作。该Network可被分配至一个或多个Kubernetes Namespaces,而任意归属于同一Network的Pod都能够直接通过IP地址彼此通信。
apiVersion: v1
kind: Namespace
metadata:
name: ns1
spec:
network: net1
如果Namespace中不存在Network的字段,它会默认使用Kubernetes自带的网络模型,其中包括了默认的kube-proxy。因此如果用户在Namespace中利用相关Network创建一个Pod,Hypernetes将根据 Kubernetes网络插件 模型设置一套Neutron网络。下图是一个粗略的流程示例:
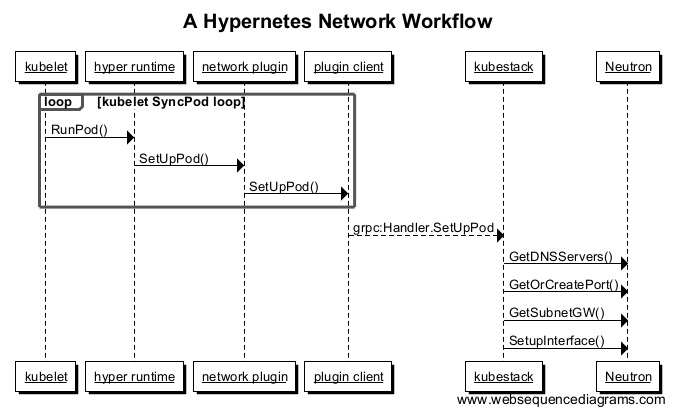
Hypernetes使用了一个名叫kubestack的独立进程来将Kubernetes Pod请求翻译至Neutron网络API。另外,kubestack还负责处理另一项重要的网络功能:多租户Service代理。
在多租户环境下,基于iptables的默认kube-proxy无法访问到所有Pod,因为这些Pod会被隔离在不同网络当中。面对这一需求, Hypernetes利用了内置的HAproxy 作为门户(Portal)。HAproxy将负责代理该Pod namespace中的全部Service实例。Kube-proxy则根据标准的OnServiceUpdate和OnEndpointsUpdate流程对这些后端服务器进行更新,用户在使用中将不会有任何异样的感觉。不过这种作法的弊端在于,HAproxy必须监听部分可能与用户容器相冲突的端口。正因为如此,我们才计划在下一版本中利用LVS取代目前的代理机制。
在上述基于Neutron的网络插件的帮助下,Hypernetes Service能够提供一套OpenStack负载均衡器,其效果与GCE上的“外部负载均衡器”基本一致。当用户利用外部IP创建一项Service时,系统会同时为其创建一套OpenStack负载均衡器,被代理的各后端服务则通过之前提到的kubestack工作流进行自动更新。
持久化存储
所谓的持久化存储,我们实际上指的是如何在Kubernetes当中构建起一套多租户的持久化数据卷。我们之所以没有选择现有Kubernetes Cinder数据卷插件,是因为该模式并不适用于基于虚拟化的容器上。比如:
- Cinder数据卷插件要求使用完整的OpenStack集群来作为Kubernetes的下层IaaS。
- OpenStack将会负责找到需要挂载数据卷的Pod运行在哪个虚拟机上。
然后Cinder数据卷插件会将Cinder卷挂载到Kubernetes所在的虚拟机上的指定目录。 - Kubelet会绑定此目录以作为目标Pod内各容器的数据卷(host:path模式)。
不过在Hypernetes中,整个流程则要简单得多。归功于Pod的物理边界,HyperContainer能够直接将Cinder数据卷作为块存储设备直接添加至Pod当中——正如同我们对普通虚拟机所做的那样。这项机制消除了前面提到的OpenStack通过Nova来查找目标Pod对应的虚拟机所带来的时间浪费。
目前,我们的Cinder插件使用的是Ceph RBD后端,其工作方式同其它Kubernetes标准数据卷插件一致,用户只需要创建Cinder数据卷(比如以下示例中volumeID所标示的内容)即可。
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: nginx-persistent-storage
mountPath: /var/lib/nginx
volumes:
- name: nginx-persistent-storage
cinder:
volumeID: 651b2a7b-683e-47e1-bdd6-e3c62e8f91c0
fsType: ext4
因此当用户在Pod yaml中声明了Cinder数据卷后,Hypernetes会检查kubelet是否正在使用HyperContainer容器运行时。如果是,则Cinder数据卷可在无需进行额外路径映射的前提下直接与Pod进行挂载。然后,该数据卷的元数据将作为HyperContainer描述的一部分被交给至Kubelet RunPod进程处用来启动Pod。大功告成!
受益于Kubernetes网络与数据卷的插件模式,我们能够轻松的使用上述解决方案来支撑HyperContainer在Kubernetes中运行,尽管它采用了与Linux容器完全不同的隔离机制。我们还计划在容器运行时整合工作完成后通过满足CNI网络接口与Kubernetes数据卷插件标准从而将这些解决方案合并到Kubernetes主干当中。
我们坚信这些 开源项目 都是容器生态系统中的重要组成部分,而它们的成长很大程度上归功于开源软件精神和Kubernetes团队的技术视野。
总结
在今天的文章中,我们介绍了HyperContainer以及Hypernetes项目的部分技术细节。我们希望大家会对这一全新的、安全的容器方案和它与Kubernetes的集成抱有兴趣。如果大家想试用Hypernetes以及HyperContainer,我们正好刚刚发布了基于上述技术的、全新的、安全的容器云服务的beta测试版本( Hyper_ )。不过如果大家更倾向于选择私有环境,那么Hypernetes与HyperContainter项目绝对能够帮助大家获得更安全的、更适合生产环境的Kubernetes解决方案。
原文链接: Hypernetes: Bringing Security and Multi-tenancy to Kubernetes
正文到此结束
- 本文标签: 负载均衡 配置 Google Docker Uber beta测试 Nginx 安全 API 实例 开源 Security update iptables apr 管理 Kubernetes 总结 文章 XEN ip 集群 开源项目 App 锁 ACE 目录 端口 标题 数据 时间 开发 生命 云 tab 进程 开源软件 需求 软件 http 虚拟化 测试 tar 开发者 IaaS 插件 src linux 翻译 UI OpenStack key lib Service 服务器
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

