Kubernetes Resource监控怎么做?
文章由才云科技翻译,如若转载,必须注明转载自“才云科技”。查看原文请点击“原文链接”。
Kubernetes有一个之前系统用来做很多工作的REST-ish HTTP API。这个API是开放的,而且文档十分齐全,很容易整合,可以从代码方面管理集群。然而这个API还有一个不直接映射到HTTP的概念:WATCH。resource有任何的修改,它就会通知API用户。然而这个功能的调用,还是有一定工作量的,我们来探个究竟。
WATCH请求剖析
从Python使用Kubernetes API,如果使用Request库的话,就十分轻松。API运行得十分好,总是使用并且返回JSON消息。但是发行watch请求就变得复杂多了。发一个watch请求理论上有两种方法:一个是用流传输结果的普通HTTP请求,同时使用分块编码;另一种方法是使用websockets。不幸的是,当测试Kubernetes1.1 master的时候,并没有正确地使用websocket协议,所以使用流传输结果才是正确的方法。
当使用分块编码流传输的时候,Kubernetes master会通过发送分块的尺寸开始传输分块。但是它不会发送一整个分块,它只会发送一行文本,再被一行新的文本终止。这行文本是JSON编码对象,里面还有event以及修改过的resource项目。所以协议是基于行的,而分块编码只是当结果可得的时候一个用来分流这些结果的方法。从表面上看用请求来做这个似乎不那么难:

然而iter_lines方法并没有按照你想要的方向来做,它保有一个外部缓冲,这个缓冲意味着你永远都看不到最后一个event因为你还在等着填满那个缓冲。
这个问题的提出意味着通过实施你自己的iter_lines()函数来使用原套socket,从回应socket到读取socket。很不幸,那个简单的方法犯了一些错误。首先,它没有正确地处理分块编码,描述分块大小的八位元数会出现在输出过程。但是更加重要的是,另一个缓冲层次正在继续,一个你不能进行应急操作的缓冲层次。额外的缓冲是因为请求使用的是原始套接字的生成文件方法从中读取数据。这对于Requests来说就讲得通了,Python标准库和OS都擅长通过缓冲加速。然而这并不意味着在Requests解析了响应的标头后,缓冲就已经不知道使用了响应本身多大的字节,而且这些字节无法检索。所以使用Requests来使用watch API基本上不太可能。
手动进行HTTP
所以如何从Python使用watch API?通过自己发出请求和处理响应。这个做起来其实很简单,socket编程其实没那么吓人。首先,你需要连接socket到服务器,然后发送HTTP request。HTTP非常简单,你只需要在socket上发送一些标头即可:
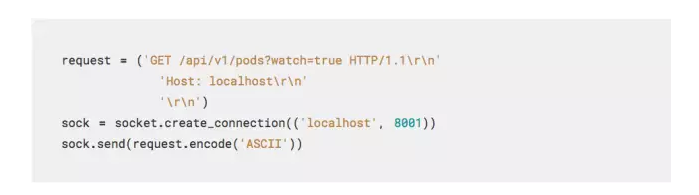
注意,Host标头被Kubernetes master要求用来接受request。
解析HTTP响应稍微有点复杂。然而http-parser库实施HTTP解析方面的东西的时候,没有涉及到sockets或者任何类似于网络的东西。所以我们可以轻松地读取和解析响应:

现在我们来响应已经被解析的标头。很可能,一些本体数据已经接收到了,这很棒,这些本体数据在解析器中仍处于缓冲好的的状态,直到我们检索它。但是首先让我们来保持读取数据,直到没有剩下的为止(不要在生产过程中这么做,对你的存储系统不好)。
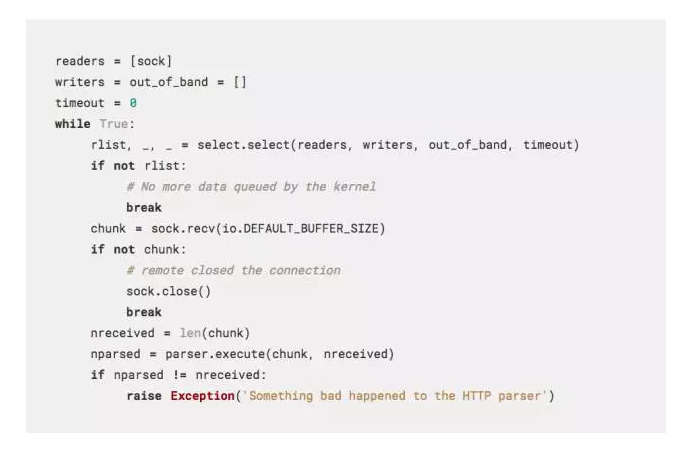
上图展示了如何使用select在数据可得的时候只读数据,而不是先阻断,然后使数据再次可读。当然,一旦使用了所有的数据,Kubernetes master 可能就会发送下一版本更新到PodList,但是让我们现在先来读一下接收到的events:

就是它!如果数据接收截至在换行符,然后lines.split() 调用会回到一个空的字符串(b'')作为最后一个项目。如果数据没有在一个新的换行符那里结束,那么一个未完成的event会被接收,这样当我们获得其它数据的时候我们就需要保存下来。
结论
所以为了正确地使用Kubernetes watch API调用的响应,你需要创建你自己的socket连接,并且解析HTTP响应。很幸运,这并没有想象得那么难。你并不需要全部自己来写!我们已经都实施过了,而且更多信息在我们的kube项目里,这也给我们提供了一个相当好的被包装成一个迭代器API的安装启用。Kube本身仍然需要更多的新功能,但是watch功能的实现已经十分有用了。
文章由才云科技翻译,如若转载,必须注明转载自“才云科技”。查看原文请点击“原文链接”。
想了解更多信息,请关注才云科技微信公众号
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

