大数据治理系列,第六部分: 大数据监管和信息单一视图监管
大数据治理专题详细阐述了什么是大数据治理、为何要做大数据治理,并结合实际业务问题介绍了大数据治理统一流程参考模型的实施步骤,以及 IBM 相关的大数据治理的产品介绍。
大数据治理统一流程参考模型(续)
第十二步:(狭义)大数据监管
在大数据时代,企业更需要数据治理,只有对海量数据进行治理,使其变得可信才能帮助企业获取准确、深入的洞察力。除了满足监管和风险管理要求外,企业通过对大数据来创造更多的业务价值,比如精细化管理、精准营销、反洗钱和反欺诈等,当然这一切的前提就是数据是可信的。如果基础数据不可靠,那么大多数企业的大数据计划要么会失败,要么效果会低于预期。大数据监管和主数据监管类似,同样包含三部分:委派数据管理员、(狭义)大数据质量管理和实施大数据管理三部分。
- 委派数据管理员: 主要包括委派首席数据管理员、确定数据管理工作计划的配置(根据成熟度的不同,从低到高分为按 IT 系统、按组织和按主题区域调整数据管理工作)、确定每个数据领域的主管发起人以及为每个数据领域分配数据管理员等。
- (狭义)大数据数据质量管理: 相比传统数据的监管,由于大数据实时性要求高、容量大以及数据类型多样,其数据质量管理也有别于传统数据的质量管理。针对高价值的结构化数据企业通常会执行严格的、完全的数据治理流程,而大数据治理则要考虑投入产出的问题,因为基于目前数据的数量、速度和多样性,企业往往无法承担完全清理每部分数据所需的时间和资源,因为这不太经济。具体来说大数据质量管理与传统的数据质量管理存在以下区别:
- 传统的数据质量管理主要关注静态数据,而大数据治理除了静态数据以外,还要关注动态数据处理;
- 传统数据置信度较高,而(狭义)大数据中很多时候存在大量噪音数据,需要进行清除;
- 传统数据以结构化为主,而(狭义)大数据除了结构化数据,还包含大量的半结构化和非结构化数据;
- 传统数据的元数据管理完善,而(狭义)大数据本身受用例驱动,其元数据管理相应较差;
- 传统数据分析主要基于静态数据,而(狭义)大数据分析除了基于静态数据进行分析以外,还包括对动态数据进行实时分析。
企业可以参考以下步骤进行(狭义)大数据的质量管理:
- 在业务上与合作伙伴合作,建立并评估大数据质量的置信区间;
相比传统的数据质量管理以内部结构化数据为主不同,大数据项目很多时候会用到大量的外部数据,及时发现数据质量问题比以前困难很多。企业可以尝试在业务上与合作伙伴合作,尝试创建数据质量模型,包含关键的数据元素、数据质量问题和业务规则。比如企业 AAA 基于互联网数据进行产品方面的舆情分析,对采自微博的数据进行以下处理,如果微博记录中包含了“@AAA”以及一件该公司产品,那么置信度为 99%(高置信度),如果该微博记录仅包含“@AAA”,那么置信度为 75%(较高置信度),如果微博记录中只包含 AAA,那么置信度为 50%(中等置信度),如果微博记录来自黑名单中的用户,则置信度为 0。
- 利用半结构化和非结构化数据,提高人口稀疏的结构化数据质量;
- 通过流计算技术对动态数据进行实时处理,剔除噪音数据,提高数据质量,最后将输出结构作为静态数据存储到 Hadoop 平台、MPP 数据库、关系型数据库/数据仓库或各种 NoSQL 数据库中,无需将中间结果进行保存。
- 实施大数据管理: 实施大数据解决方案需要采取务实的态度以及渐进式的方式,首先需要识别业务需求,然后确定基础架构、数据源以及各种 KPI 指标,通过从内部和外部数据源提取新的洞察,帮助企业获得实际效果后再进一步扩大应用范围,根据企业大数据战略进一步升级其基础架构。针对狭义大数据的治理,企业通常需要制定一个合适的大数据治理策略,具体包括以下内容:
- 审核确定大数据治理的业务案例(大数据分析是受用例驱动的);
- 通过实施完善的元数据管理,建立大数据的类别信息;
- 建立大数据与主数据之间的映射关系,比如在满足隐私以及相关政策的情况下,将社交媒体数据和主数据进行关联;
- 识别企业内与大数据相关的关键业务流程,针对业务流程中的关键步骤制定相应的大数据治理策略;
- 对流数据进行实时分析处理,只将最终要保留的结果进行存储,废弃中间结果和噪音数据;
- 对重点数据实现质量控制;
- 关注大数据生命周期管理,对访问频率较低的数据进行归档,删除没有必要存储的数据等;
- 企业必须建立符合法律规范的隐私策略,防止大数据的误用、滥用。
回页首
IBM BigInsights 3.0 介绍
IBM 在 Hadoop 开源框架的基础上进行了大量的开发和扩展,陆续将丰富的高级文本分析(Advanced Text Analytics Toolkit,研发代码 SystemT)、机器学习(Machine Learning Toolkit,研发代码 SystemML)、GPFS File Place Optimizer(GPFS-FPO)、IBM LZO 压缩、针对 Jaql 的 R 模块扩展、改进的工作负载调度(Intelligent Scheduler)、自适应 MapReduce(Adaptive MapReduce)、基于浏览器的可视化工具(BigSheets)、大规模索引、搜索解决方案构建框架(BigIndex)、大规模并行处理 SQL 引擎(MPP SQL Engine,IBM Big SQL)等纳入到 InfoSphere BigInsights 中,并增强了高可用性、可扩展性、安全性、性能、易用性、监控和告警等,通过支持 LDAP 身份验证增强安全性(另外还能够提供可插拔身份验证支持,支持 Kerberos 等其他协议),构建了一个完整的企业级大数据平台。该平台为开发人员提供了全面的开发和运行时环境来构建高级分析应用程序,为企业用户提供了完善的分析工具来分析大数据,从而使与大数据分析相关的时间价值曲线变平。
IBM Big SQL 3.0 是一个大规模并行处理 SQL 引擎(MPP SQL Engine),可以直接部署在物理的 HDFS 集群上。通过使用一个低延时并行执行基础架构,并将处理操作放在数据所在的节点,Big SQL 3.0 实现了 native 方式的 Hadoop 数据访问,包括读和写操作。Big SQL 3.0 数据库基础架构提供一个所有数据的逻辑视图(通过 Hive 元数据管理),查询编译视图,以及为最优的 SQL 处理提供优化和运行时环境。针对复杂嵌套的决策支持查询,Big SQL 3.0 专门做了优化处理。Big SQL 3.0 接口完全支持 SQL 2011 标准,支持存储过程,用户自定义函数,广泛的数据类型,JDBC/ODBC 接口等。
Big SQL 所有的数据都保持原有的格式存储在 Hadoop 集群中,Big SQL 对数据的格式没有特殊的要求,Hadoop 表的定义是由 Hive Metastore 定义和共享的,使用 Hadoop 的标准目录。Big SQL 共享 Hive 接口进行物理读取,写入和理解 Hadoop 中存储的数据。简单的来说,Big SQL 中没有任何的数据存储,数据是存放在 Hadoop 集群中的,在 Big SQL 中定义的表实际上是一个在 Hive 中定义的表。通过 Apache HCatalog,Hive 中定义的表可以作为很多工具的有效数据源。最终,任何 Hadoop 应用程序都可以访问这些大规模共享的分布式文件系统中的简单文件。Big SQL 既可以运行在 POWER Linux (Red Hat) 上,也可以运行在 x64 Linux 上,如 Red Hat 和 SUSE Linux。
更多内容请参考:
IBM Big SQL 3.0 新功能系列,第一部分:大规模并行处理 SQL 引擎(MPP SQL Engine)Big SQL 3.0 介绍
IBM Big SQL 3.0 新功能系列,第二部分:IBM InfoSphere BigInsights 3.0 环境搭建
IBM Big SQL 3.0 新功能系列,第三部分: Big SQL 3.0 测试环境初始化
IBM Big SQL 3.0 新功能系列,第四部分: 小数据量下 TEXTFILE 存储格式 Big SQL 和 Hive External 表查询对比
IBM Big SQL 3.0 新功能系列,第五部分:大数据量下 TEXTFILE 格式的 Big SQL 和 Hive External 表查询对比
IBM Big SQL 3.0 新功能系列,第六部分:各种存储格式下 Big SQL 和 Hive 查询对比
企业级大数据存储、分析平台:IBM InfoSphere BigInsights 3.0 新功能介绍
回页首
IBM InfoSphere Streams 介绍
IBM InfoSphere Streams 是一个并行和高效的低延迟流计算平台(毫秒级延迟,甚至低至微秒级),可以即时处理、过滤和分析流数据,流数据可以是结构化、半结构化或非结构化数据(如文本、音频、视频、图像、传感器、数字、GPS 数据、日志、交易记录和呼叫详细记录等各种类型数据)。InfoSphere Streams 支持连续、快速地分析大量移动中的数据,加速业务洞察和决策制定。如图 1 所示,InfoSphere Streams 包含应用程序的编程语言 Steams Processing Language(SPL)和集成开发环境(IDE),以及可在单个主机或一组分布式主机上执行应用程序的运行时系统。SPL 提供一种语言和运行时框架来支持流式方法应用程序。用户可以创建应用程序,无需了解较低级别的特定于流的操作。SPL 提供大量内置运算符、导入 InfoSphere Streams 外部数据和导出系统外部结果的功能,以及通过用户定义的运算符扩展底层系统的工具。许多 SPL 内置运算符提供功能强大的关系函数,如连接和聚合。Streams Studio IDE 包括用于编写和创建 InfoSphere Streams 应用程序的可视化表示的工具。
图 1. Streams 体系结构

InfoSphere Steams 可以在多种硬件平台上进行扩展,最高可扩展到 125 个节点(线性的可扩展性),支持动态部署新的分析应用,通过 JVM 共享从而最大限度的减少内存使用。通过在数据进入视野就进行分析,企业可以即时对事件和趋势进行响应,改善业务成果。通过 Steams,可以跨多个流获得洞察力,融合多个流获得新的洞察力,还支持将需要的数据保存后进行深入分析等。InfoSphere Streams 作为支持流计算快捷实时数据分析开发平台,提供对流数据(结构化和非结构化)的实时分析能力,支持海量多数据源,提供高性能处理和敏捷开发,支持流动数据加分析的模式从海量数据中挖掘出有用的信息。另外,InfoSphere Streams 和 BigInsights 共享同一个 Advanced Text Analytics Toolkit,可以在整个大数据平台中实现技能和代码的重用。
如图 2 所示,在 Streams 流计算过程中最小处理单元是 Processing Element(PE),可以配置 PE 动态地在多个服务器间动态负载均衡,根据工作负载需要进行动态资源调配,也可以指定让 PE 运行的服务器。
图 2. Streams 运行环境

回页首
第十三步:信息单一视图监管
过去很长一段时间,企业应用主要围绕业务展开,形成了一个个分立的应用,而分立的应用导致了一个个的静态竖井。这些竖井(信息孤岛)之间缺乏沟通,每个竖井只能提供片面的信息,而不是全局的单一视图。这些孤立的竖井使得高管们对公司只有有限的洞察力,无法准确预见到将要发生的事情。缺少企业信息的单一视图,往往意味着营收损失,客户满意度下降和市场开拓乏力等等。例如,一个全球性的大公司一般拥有多个业务部门,并且在全球很多地方设有分部,其客户信息和业务合作伙伴信息分散在多个业务系统中,每个部门甚至每个分部都拥有自己的客户关系管理系统。即便在同一个部门,客户信息也可能分散在计费、订单和客服中心中,因此公司无法获得关于其客户的足够信息以便更有效地服务客户或开拓市场。更好的客户服务和更高的目标要求,驱动了对客户信息单一视图的需求。再例如银行受理一笔贷款申请,由于没有足够的历史数据支撑,无法准确判读借款人的风险评级情况,很多时候只能依据借款人提供的当前时点的资料进行主观判断,假如该借款人另一个不同的账户过去有拖欠付款记录,而且没有被正确标识,那么客户可能会收到不恰当的良好记录,而银行也会因此增加风险。当银行给客户提供贷款时,公司需要准确的知道不同客户能给公司带来的价值和相应的风险。如果对客户缺乏足够的了解,那么就无法准确地了解和他们相关的风险敞口,而公司就可能会低估该风险敞口或给予客户过于宽松的信贷条件。
为了解决业务竖井,消除信息孤岛,信息架构需要从以项目为基础转向以灵活架构为基础,动态地为应用提供整合的信息(可信的全景信息),即信息随需应变(Information On Demand,IOD)。通过一个灵活的信息架构,用户可以在需要的时间和地点拿到准确、一致、完整和及时的数据。信息随需应变提供战略性的框架和解决方案,提供带有上下文、可供信任的信息来优化业务过程,提高生产力。IOD 的结果是什么?就是信息被有效利用,从而驱动企业的业务变革,即信息引领变革(Information-Led Transformation)。通过使用完整、及时、准确和一致的企业单一信息视图,企业高管们可以针对不同的情况及时采取措施,如通过实时准确的财务信息视图,CFO 可以获得核心财务比率以便评估业绩并采取必要的补救措施。为了成功实现企业信息单一视图,对其进行监管就非常重要。信息单一视图监管同样包含三个部分:委派数据管理员、管理数据质量和实施信息单一视图三部分。
回页首
IBM InfoSphere DataStage
InfoSphere DataStage 是一款功能强大的基于图形化的 ETL 工具,可以从各种不同的数据源(可以是 ODS,数据库/数据仓库/数据集市/MPP 数据库,Hadoop 平台等不同数据源)中抽取并转换数据,并将其加载到各种目标系统(可以是 ODS,数据库/数据仓库/数据集市/MPP 数据库,Hadoop 平台,各种应用程序等)中,可以大量节省信息集成所需的工作量,降低项目集成风险。DataStage 可以批量或实时地(和 CDC 结合)处理大容量数据,在每个作业中几乎可以和无限的异构数据源连接(连接器采用 Information Server 通用连接器)。
InfoSphere Datastage 具有以下特点:
- 完全图形化的设计工具,作业设计、开发、调试和维护非常容易;图形化的工作流,支持条件路径和错误处理,支持 Email 通知等;作业可重用性高;顺序开发,并行执行。
- 支持各种数据源连接,作业可以访问企业应用程序,关系数据库(如 DB2、Oracle、 Informix、Sybase、Microsoft SQL Server 以及 ODBC 等),ERP 或 CRM 数据库,数据仓库和文件集(SAS 数据集、XML、平面文件、Cobol 复合文件等),Hadoop 平台等。
- DataStage 实现了与 HDFS 和 GPFS-FPO 的全面集成,可以充分利用集群架构的优势将所有批量数据并行地写入同一文件。通过使用 DataStage 集成,各种 Hadoop 平台可以方便地实现与传统结构化数据源的数据交换。DataStage 除了改进与 HDFS 相关的集成,还新增了与通用 MapReduce 作业相关的集成,和各种 Hadoop 平台进行了紧密结合。
- 提供全面的内置函数库帮助实现数据流的无代码可视化设计,减少开发时间和学习难度,提高准确性和可靠性。
- 高性能可伸缩处理架构,充分支持并行处理且不需要更改设计,作业可运行于任意并行度,只需要变更配置文件(也就是增减并行度不需要修改编译作业),可线性扩展性能。
- 支持批处理或实时数据处理(通常需要和 InfoSphere Data Replication 配合)。
- 统一的元数据模型,支持 CWM 元数据模型,可以追踪管理 ETL 过程中的元数据及其变化。
- 支持团队开发和协作。
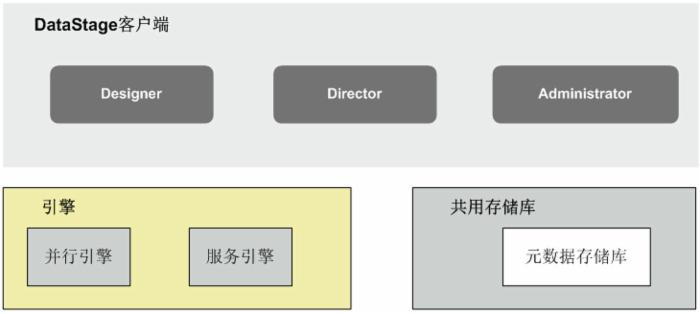
如图 3 所示,DataStage 由客户端工具,引擎和共用存储库组成,DataStage 和 QualityStage 共用图形化用户界面。DataStage 客户端工具又包括 DataStage and QualityStage Designer,DataStage and QualityStage Director 和 DataStage and QualityStage Administrator 三部分。Designer 是用来创建 DataStage 作业的图形用户界面,在 Designer 中每个作业可以指定数据源,目标数据源和所需转换等,通过编译作业最终生成可执行程序。Director 是用来检验、调度、运行和监视 DataStage 序列的界面,Administrator 是管理界面(比如设置用户,日志记录和创建项目等)。引擎部分包括并行引擎和服务引擎,并行引擎使用 Information Server 共用的并行引擎功能来执行 DataStage 并行作业,服务引擎包括 Information Server 共用的元数据服务和连接器等。共用存储库用来存储 DataStage 各阶段所需的元数据,包括项目元数据,操作性元数据和设计元数据等。
图 3. DataStage 体系结构图
直观易用的开发和维护环境
Datastage 提供了全面的图形化设计、管理和维护工具,帮助用户优化构建、升级和管理数据整合架构时的速度、灵活性和效率,丰富的功能组件减少了用户学习周期,简单化了管理和优化了开发资源的使用,减少了数据整合应用的开发和维护周期。
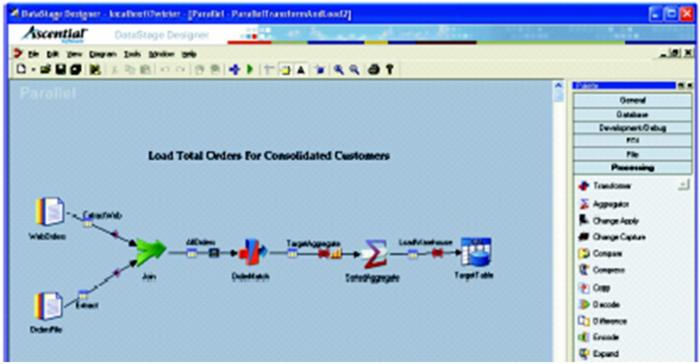
Datastage 任务设计采用数据流的概念,一个完整的数据流程(Datastage 作业)由一系列功能组件(Stage)组合而成,具体从数据源 Stage 开始,中间经过一系列的转换和清洗,最后加载到目标数据源。Datastage Designer 使用户可以灵活地以各种方式构建作业:从上到下、从下到上、从中间开始。一个完整的数据流图如图 4 所示:
图 4. Datastage 数据流图示例
Datastage 内嵌的扩展 Stage 提供了数据整合过程中 80%以上的最常用的处理逻辑,基于组件架构和扩展内嵌组件类库的 DataStage 支持组件的复用,方便用户整合第三方软件工具和遗留应用。DataStage 提供多种机制帮助用户建立自定义的 Stage:
- Wrapped --允许并行执行一个顺序程序。
- Build --允许自动并行执行自定义 Stage 的 C 语言表达式。
- Custom 提供了完整的 C++ API,来开发复杂和扩展的 Stage。
企业级实施和管理
DataStage 提供图形化的作业定序器,帮助用户指定作业的顺序,顺序中可以包含控制信息以便用户根据作业执行结果采取不同的行动。作业顺序支持 DataStage 作业、例行程序、执行命令(操作系统命令)、电子邮件通知、等待文件、运行异常获得、作业顺序的检查点、重新启动选项、环回阶段、用户表达式和变量、中止异常活动等活动类型。通过 DataStage 提供的资源预估功能,用户可以估算 ETL 任务过程中每个处理阶段所需的系统资源,比如 CPU、内存、磁盘等。通过 DataStage 提供的图形化监控工具,可以直接从设计的数据流图上得知 ETL 每个阶段运行情况,可以生成任务时间性和性能分析图,分解作业查看各 Stage 处理使用的时间,洞察时间线上的瓶颈。DataStage 提供基于 Web 浏览器的监控平台,用来显示当前服务器的运行状态,如 CPU 利用率、内存和磁盘使用情况以及 ETL 任务的运行状态等。
高扩展的体系结构,具备线性扩充能力
如图 5 所示,DataStage 体系结构具有高扩展性,通过管道并行(Pipeline parallelism)或分区并行(Partition parallelism)可以获得高吞吐量和性能,通过支持对称多处理(SMP)和大规模并行处理(MPP)等具备线性扩充能力。
- 管道并行: 举例说明,在具有三个以上处理器的系统上运行 Job 时,读取 stage 将在一个处理器上开始并将读取的数据填充管道(Pipeline),当管道中存在数据之后,转换 stage 会在另一个处理器上开始,处理数据并开始填充另一个管道,当另一个管道可用时,写入目标数据库的 stage 会在第三个处理器上开始并立即开始写操作。这样,三个 stage 会同时运行,而不是串行运行。
- 分区并行: 通过将数据分割到多个单独的集合(数据分区)中并行执行,充分利用多个处理器高效运行,每个处理器处理所有数据中的一个子集(数据分区),job 完成后可以将所有数据分区重新收集起来写入单一数据源。
图 5. Datastage 并行

回页首
IBM InfoSphere QualityStage
QualityStage 是一款功能强大的数据清洗工具,可以和 DataStage 无缝集成,通过使用数学概率算法匹配重复的数据记录,自动地把数据(比如客户地址、电话号码、传真、电子邮箱等)转换为经过检验的标准格式,可以消除现有数据源中的重复内容,从而确保数据的唯一性、准确性和一致性。通过可视化的用户界面,可以定义复杂的匹配和留存逻辑以确保干净、标准化和不重复的信息装入到目的端。QualityStage 使用和 DataStage 相同的基础设施导入导出数据、设计、部署和运行作业以及生成报告。
QualityStage 主要包括以下功能:
- 数据调查: 帮助了解数据质量和期望达到的数据清洗标准等,为数据标准化提供一些参考信息。
- 数据标准化: 帮助将名字、电话号码和地址等常用客户信息标准化,也可根据行业数据做定制,标准化行业数据信息。
- 数据匹配: 基于数据的标准化,数据被切割成统一格式的,多个小的信息单元,将小的信息单元用于匹配权重计算,将大大提高匹配概率和准确性。
- 数据留存: 将多条匹配或者说重复的数据,交叉组合形成最优的候选数据提供给用户,甚至可以补足一些缺失字段等。
比如我们需要对包含地址信息的字段进行清洗并重新生成新记录,匹配的原理就是将相似的数据根据地址字段分组,然后在数据分组内通过比较计算权重判断哪些数据可能重复,具体如图 6 所示:
图 6. 数据清洗示例

通过减少重复的客户记录并建立客户家庭档案等,企业可以显著提高客户识别能力并减少市场运营成本。比如某国电信公司,拥有总用户数 2 千万,不同系统的相同客户信息写法不一致,很多信息缺失或者录入错误。该电信公司后来通过使用 QualityStage 将各种信息,如姓名、生日、地址、电话、ID 等进行标准化,然后根据概率算法进行匹配并生成统一的客户视图。结果该电信公司每个月少发 30 万封信,从而每年节省了 200 万美金。
回页首
结束语
本文详细介绍了大数据治理统一流程参考模型的第十二步“(狭义)大数据监管”、第十三步“信息单一视图监管”、IBM 大数据产品 BigInsights 和 Streams 以及 IBM 大数据治理方面的产品 InfoSphere DataStage、InfoSphere QualityStage 等。在本系列文章的下一部分将重点介绍大数据治理统一流程参考模型第十四步“运营分析监管”、第十五步“预测分析监管”、第十六步“管理安全与隐私”、第十七步“监管信息生命周期”和第十八步“度量结果”,以及 IBM Cognos BI、SPSS Modeler、Guardium、Optim Data Growth Management 和 Optim Test Data Management 等内容。
回页首
参考文献
- 本章参考了 IBM 相关产品的信息中心、白皮书、方案建议书以及其他各种资料。
正文到此结束
- 本文标签: 敏捷 企业 web IBM cat NOSQL 管理 XML SQL Server apache Hadoop 负载均衡 产品 sql 大数据 App 微博 rmi 测试 家庭 互联网 安全 IDE CTO 开源 目录 定制 ip 数据库 政策 数据 时间 开发 linux 协议 mail Oracle apr 调试 需求 操作系统 编译 质量 银行 贷款 UI 软件 ldap db 噪音 HDFS 配置 代码 组织 自适应 服务器 db2 tar 集群 map API
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

