如何用 Python 实现 Web 抓取?
【编者按】本文作者为 Blog Bowl 联合创始人 Shaumik Daityari,主要介绍 Web 抓取技术的基本实现原理和方法。文章系国内ITOM 管理平台 OneAPM 编译呈现,以下为正文。

随着电子商务的蓬勃发展,笔者近年越来越着迷于比价应用。我在网络上(甚至线下)的每次购买,都是在各大电商网站深入调研后的结果。
笔者常用的比价应用包括:RedLaser, ShopSavvy 以及 BuyHatke。这些应用有效提高了价格透明度,进而为消费者节省了可观的时间。
但是,你是否想过,这些应用如何得到那些重要数据?通常,它们会借助 Web 抓取 技术来完成该任务。
Web 抓取的定义
Web 抓取是抽取网络数据的过程。只要借助合适的工具,任何你能看到的数据都可以进行抽取。在本文中,我们将重点介绍自动化抽取过程的程序,帮助你在较短时间内收集大量数据。除了笔者前文提到的用例,抓取技术的用途还包括:SEO 追踪、工作追踪、新闻分析以及笔者的最爱——社交媒体的情感分析!
一点提醒
在开启 Web 抓取的探险之前,请确保自己了解相关的法律问题。许多网站在其服务条款中明确禁止对其内容进行抓取。例如, Medium 网站就写道:“遵照网站 robots.txt 文件中的规定进行的爬取操作(Crawling)是可接受的,但是我们禁止抓取(Scraping)操作。”对不允许抓取的网站进行抓取可能会使你进入他们的黑名单!与任何工具一样,Web 抓取也可能用于复制网站内容之类的不良目的。此外,由 Web 抓取引起的法律诉讼也不在少数。
设置代码
在充分了解小心行事的必要之后,让我们开始学习 Web 抓取。其实,Web 抓取可以通过任何编程语言实现,在不久之前,我们 使用 Node 实现过 。在本文中,考虑到其简洁性与丰富的包支持,我们将使用Python 实现抓取程序。
Web 抓取的基本过程
当你打开网络中的某个站点时,就会下载其 HTML 代码,由你的 web 浏览器对其进行分析与展示。该 HTML 代码包含了你所看到的所有信息。因此,通过分析 HTML 代码就能得到所需信息(比如价格)。你可以使用正则表达式在数据海洋中搜索你需要的信息,也可以使用函数库来解释 HTML,同样也能得到需要数据。
在 Python 中,我们将使用一个名为 靓汤(Beautiful Soup) 的模块对 HTML 数据进行分析。你可以借助 pip 之类的安装程序安装之,运行如下代码即可:
pip install beautifulsoup4
或者,你也可以根据源码进行构建。在该模块的 文档说明页 ,可以看到详细的安装步骤。
安装完成之后,我们大致会遵循以下步骤实现 web 抓取:
-
向 URL 发送请求
-
接收响应
-
分析响应以寻找所需数据
作为演示,我们将使用笔者的博客 http://dada.theblogbowl.in/. 作为目标 URL。
前两个步骤相对简单,可以这样完成:
from urllib import urlopen#Sending the http requestwebpage = urlopen('http://my_website.com/').read() 接下来,将响应传给之前安装的模块:
from bs4 import BeautifulSoup#making the soup! yummy ;)soup = BeautifulSoup(webpage, "html5lib")
请注意,此处我们选择了 html5lib 作为解析器。根据 BeautifulSoup 的文档 ,你也可以为其选择不同的解析器。
解析 HTML
在将 HTML 传给 BeautifulSoup 之后,我们可以尝试一些指令。譬如,检查 HTML 标记代码是否正确,可以验证该页面的标题(在 Python 解释器中):
>>> soup.title<title>Transcendental Tech Talk</title>>>> soup.title.text u'Transcendental Tech Talk' >>>
接下来,开始抽取页面中的特定元素。譬如,我想抽取博客中文章标题的列表。为此,我需要分析 HTML 的结构,这一点可以借助 Chrome 检查器完成。其他浏览器也提供了类似的工具。
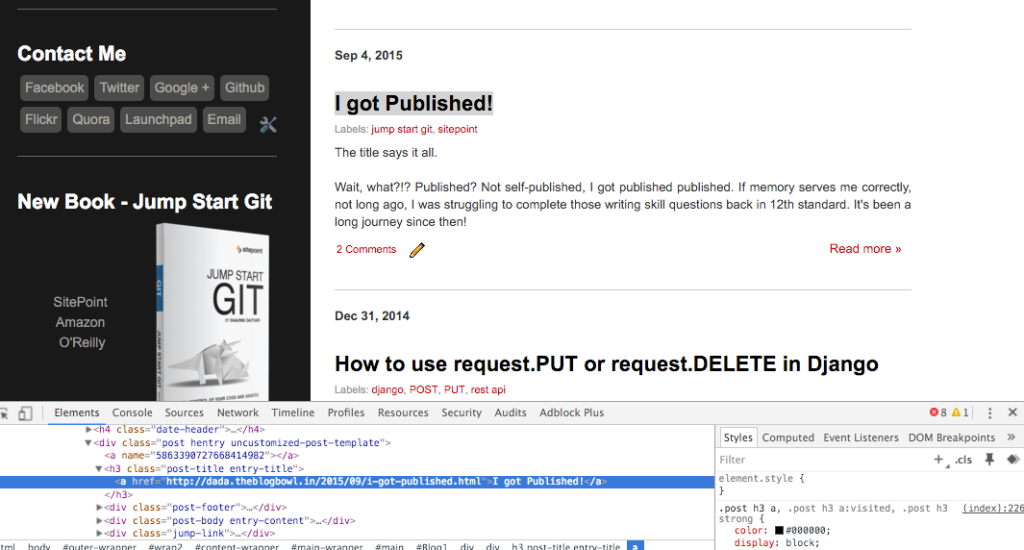 使用 Chrome 检查器检查某个页面的 HTML 结构
使用 Chrome 检查器检查某个页面的 HTML 结构
如你所见,所有文章标题都带有 h3 标签与两个类属性: post-title 与 entry-title 类。因此,用 post-title 类搜索所有 h3 元素就能得到该页的文章标题列表。在此例中,我们使用 BeautifulSoup 提供的 find_all 函数,并通过 class_ 参数确定所需的类:
>>> titles = soup.find_all('h3', class_ = 'post-title') #Getting all titles>>> titles[0].textu'/nKolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips/n'>>> 只通过 post-title 类进行条目搜索应该可以得到相同的结果:
>>> titles = soup.find_all(class_ = 'post-title') #Getting all items with class post-title>>> titles[0].textu'/nKolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips/n'>>>
如果你想进一步了解条目所指的链接,可以运行下面的代码:
>>> for title in titles:... # Each title is in the form of <h3 ...><a href=...>Post Title<a/></h3>... print title.find("a").get("href")...http://dada.theblogbowl.in/2015/09/kolkata-bergerxp-indiblogger-meet.html http://dada.theblogbowl.in/2015/09/i-got-published.html http://dada.theblogbowl.in/2014/12/how-to-use-requestput-or-requestdelete.html http://dada.theblogbowl.in/2014/12/zico-isl-and-atk.html...>>> BeautifulSoup 内置了许多方法,可以帮助你玩转 HTML。其中一些方法列举如下:
>>> titles[0].contents [u'/n', <a href="http://dada.theblogbowl.in/2015/09/kolkata-bergerxp-indiblogger-meet.html">Kolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips</a>, u'/n']>>>
请注意,你也可以使用 children 属性,不过它有点像 生成器 :
>>> titles[0].parent<div class="post hentry uncustomized-post-template">/n<a name="6501973351448547458"></a>/n<h3 class="post-title entry-title">/n<a href="http://dada.theblogbowl.in/2015/09/kolkata-bergerxp-indiblogger-meet.html">Kolkata #BergerXP IndiBlogger ... >>>
你也可以使用正则表达式搜索 CSS 类,对此, 本文档有详细的介绍 。
使用 Mechanize 模拟登录
目前为止,我们做的只是下载一个页面进而分析其内容。然而,web 开发者可能屏蔽了非浏览器发出的请求,或者有些网站内容只能在登录之后读取。那么,我们该如何处理这些情况呢?
对于第一种情况,我们需要在向页面发送请求时模拟一个浏览器。每个 HTTP 请求都包含一些相关的数据头(header),其中包含了访客浏览器、操作系统以及屏幕大小之类的信息。我们可以改变这些数据头,伪装为浏览器发送请求。
至于第二种情况,为了访问带有访客限制的内容,我们需要登录该网站,使用 cookie 保持会话。下面,让我们来看看在伪装成浏览器的同时,如何完成这一点。
我们将借助 cookielib 模块使用 cookie 管理会话。此外,我们还将用到 mechanize ,后者可以使用 pip 之类的安装程序进行安装。
我们会通过 Blog Bowl 这个页面进行登录,并访问 通知页面 。下面的代码通过行内注释进行了解释:
import mechanize import cookielib from urllib import urlopen from bs4 import BeautifulSoup# Cookie Jarcj = cookielib.LWPCookieJar() browser = mechanize.Browser() browser.set_cookiejar(cj) browser.set_handle_robots(False) browser.set_handle_redirect(True)# Solving issue #1 by emulating a browser by adding HTTP headersbrowser.addheaders = [('User-agent', 'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.1) Gecko/2008071615 Fedora/3.0.1-1.fc9 Firefox/3.0.1')]# Open Login Pagebrowser.open("http://theblogbowl.in/login/")# Select Login form (1st form of the page)browser.select_form(nr = 0)# Alternate syntax - browser.select_form(name = "form_name")# The first <input> tag of the form is a CSRF token# Setting the 2nd and 3rd tags to email and passwordbrowser.form.set_value("email@example.com", nr=1) browser.form.set_value("password", nr=2)# Logging inresponse = browser.submit()# Opening new page after loginsoup = BeautifulSoup(browser.open('http://theblogbowl.in/notifications/').read(), "html5lib") 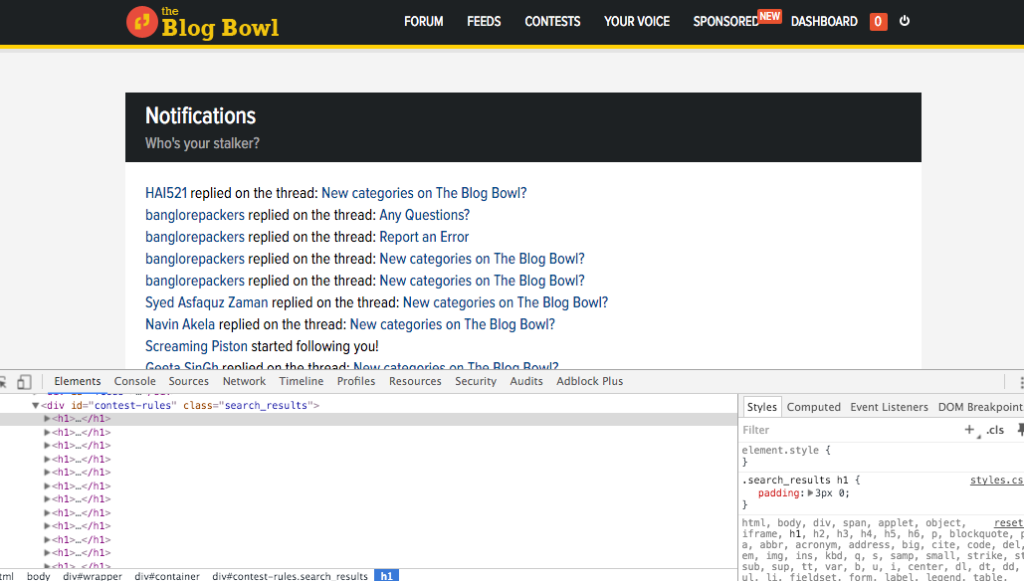 通知页面的结构
通知页面的结构
# Print notificationsprint soup.find(class_ = "search_results").text
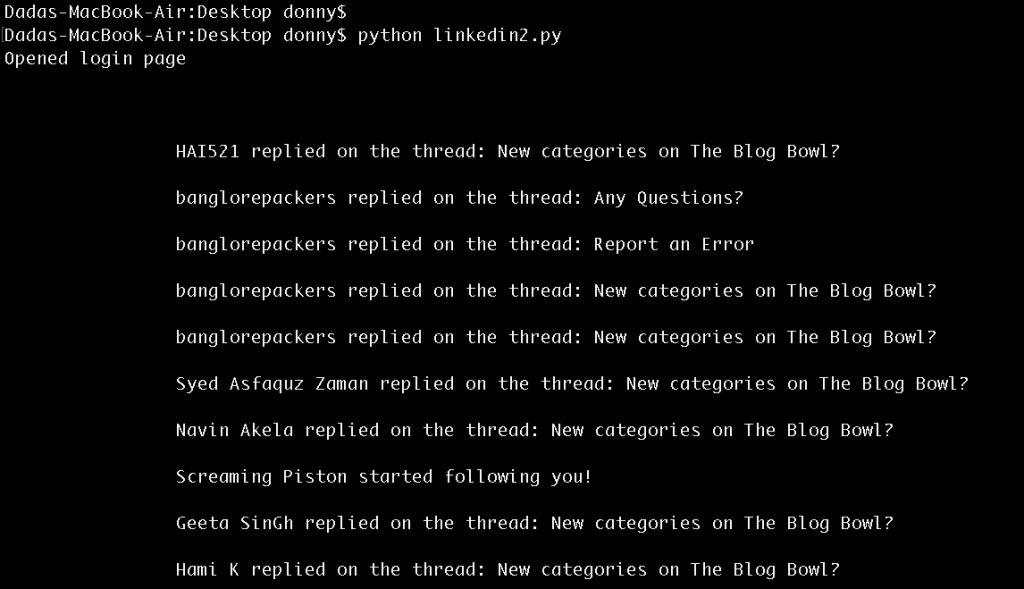 登录进通知页面后的结果
登录进通知页面后的结果
结语
许多开发者会告诉你:你在网络上看到的任何信息都可以被抓取。通过这篇文章,你学会了如何轻松抽取登录后才能看到的内容。此外,如果你的 IP 遭到了屏蔽,你可以掩盖自己的 IP 地址(或选用其他地址)。同时,为了看起来像是人类在访问,你应该在请求之间保留一定的时间间隔。
随着人们对数据的需求不断增长,web 抓取(不论原因好坏)技术在未来的应用只会更加广泛。也因此,理解其原理是相当重要的,不管你是为了有效利用该技术,还是为了免受其坑害。
OneAPM 能帮您查看Python 应用程序的方方面面,不仅能够监控终端的用户体验,还能监控服务器性能,同时还支持追踪数据库、第三方 API 和 Web 服务器的各种问题。想阅读更多技术文章,请访问OneAPM 官方技术博客。
原文地址: https://www.sitepoint.com/web-scraping-for-beginners/
正文到此结束
- 本文标签: 正则表达式 自动化 网站 API HTML 电商网站 python linux db cat 管理 创始人 开发 Word node 数据库 CSS 注释 操作系统 博客 源码 find 数据 时间 参数 http ORM 编译 开发者 需求 Chrome src Logging 服务器 https UI 代码 value lib 2015 站点 ip 安装 HTML5 Select example 下载 web mail 标题 电子商务 解析 线下 文章
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

