LinkedIn 的Kafka 生态
Apache Kafka 是一个高度可扩展的消息系统,在LinkedIn 的中心数据管道中扮演着关键角色。LinkedIn 早在2010年就开发了Kafka,现在每天在1400个节点上处理超过1.4万亿条消息。Kafka 的 高稳定性 和 低延迟 ,使我们能够使用Kafka 支撑LinkedIn 的许多新的关键任务用例,包括在 Espresso 中使用基于Kafka 的副本取代MySQL 副本, Venice 以及支撑下一代的 Databus (正在开发中)。
随着Kafka 的使用率持续的快速增长,我们必须尽可能的解决一些重大问题,所以我们围绕Kafka 开发了一个完整的生态系统。本文中,我会总结我们的一些解决方案,能够对正在使用Kafka 的人有一些帮助,并强调几个活动预告,能让你学到更多。
(点击放大图像)
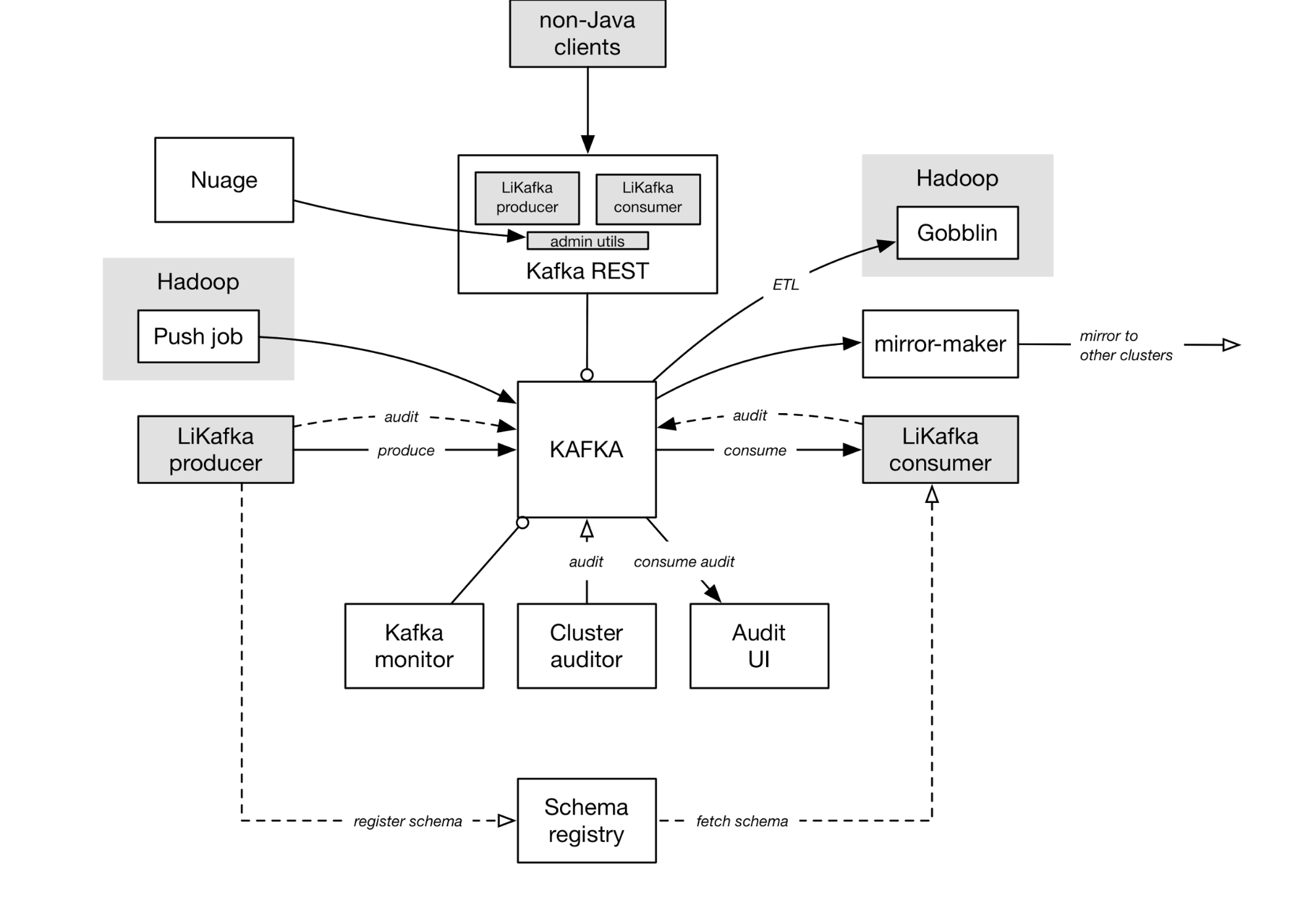
上图并不能完全反映LinkedIn 的各种数据管道和拓扑结构,但足以说明LinkedIn 的Kafka 部署的关键部分,以及他们是怎样相互作用。
Kafka 核心服务
Kafka 代理者
我们在每个数据中心,为了不同的目的运行了多个Kafka 代理者集群。在目前的开发环境中,有将近1400个代理者每周接收超过2PB 的数据。通常大约每个季度我们会复制Apache Kafka 的主干,裁剪出一个新的内部发行版。
Kafka 镜像制造者
镜像制造者让我们可以通过从源集群消费,然后生产到目的集群来制造副本。有许多镜像管道同时运行在数据中心内和跨数据中心。 Todd Palino 的文章 总结了我们怎样使用它来方便Kafka的不同组成。
模式注册中心
在LinkedIn,我们使用标准化的 Avro 作为我们数据管道的通用语言。所以每个生产者编码Avro 数据,注册Avro 模式到模式注册中心,并在每条序列化的消息中内置一个模式ID。消费者为了反序列化Avro 消息,从模式注册中心服务获取ID 对应的模式。虽然有多个模式注册中心实例跨越我们的数据中心,但有一个单一的(已复制)包含这些模式的数据库支持。
Kafka REST 代理
Kafka REST 是一个为非Java 客户端提供的HTTP 代理。我们的大多数Kafka 集群都有一个关联的REST 代理。Kafka REST也可以作为一个官方服务用于主题上的管理操作。
Nuage
Kafka 在大部分情况下是自助服务的:用户定义自己的事件模式,然后开始生产数据到主题中;Kafka 代理者使用默认配置和分区数自动创建主题;最后,任何一个消费者可以消费主题,使得Kafka 完全的开放访问。
随着Kafka 的使用率上升和新用例出现,在上述方式中显然存在很多限制。首先,一些主题需要定制配置,对Kafka SREs 有特殊的要求;其次,对于大多数用户,很难发现和检查自己主题的元数据(例如,比特率、审计完整性、模式历史等);最后,随着Kafka 加入各种各样的安全特性,一些主题所有者可能想要限制访问他们的主题,并且自己管理ACLs。
在LinkedIn, Nuage 作为在线数据基础设施资源的自助服务入口,我们最近和Nuage 团队一起工作,为Nuage 添加内置的Kafka 支持。这为用户管理自己的主题和关联元数据提供了便利。Nuage 委托CRUD 操作给Kafka REST,这样抽象了Kafka 管理工具的细微差别。
库
LiKafka 客户端库
LiKafka 生产者封装了开源的生产者,同样做了模式注册、Avro 编码、审计,并且 支持大消息 。审计事件计算10分钟内发送给每个主题的事件数。同样地,它的消费者封装了开源的消费者,并做了模式查找、Avro 解码和审计。
Kafka 推送作业
Kafka 推送作业用来从Hadoop 运送压缩数据到Kafka 中给在线服务消费。推送作业运行在我们的CORP 环境的Hadoop 集群中,生产数据到CORP 数据部署Kafka 集群中。一个镜像制造者复制这些数据到PROD 数据部署集群中。
Gobblin
Gobblin 是LinkedIn 的新集成框架, 替代 Camus 。它本质上是一个大型的Hadoop 作业,用来复制Kafka 中的所有数据到Hadoop 中进行离线处理。
监控服务
Kafka 监控
这是一个持续运行的用于Kafka 部署的测试集,用来验证新版本和监控目前的部署。目前我们监控基本但是重要的指标,比如端到端延时和数据丢失。未来我们想使用这个框架在测试集群中持续测试管理操作(比如分区再分配)的正确性,甚至利用错误注入框架,比如 Simoorg ,来确保我们即使在许多故障的情况下也能够满足可用性SALs。
Kafka 审计
在我们的审计跟踪基础设施中,有两个关键组件:
- Kafka 审计服务,消费并重新计算Kafka 集群中的所有数据,然后发送类似的审计事件到跟踪的生产者。这允许我们使Kafka 集群生产者计算的数量保持一致,并发现是否有数据丢失。
- Kafka 审计验证服务,持续监控数据完整性,并提供一个可视化的审计跟踪的用户界面。这个服务消费并插入审计事件到审计数据库中,当数据延迟或者丢失时发出警告。我们使用审计数据库来调查发生的警告,并精确定位数据在哪丢失。
(点击放大图像)
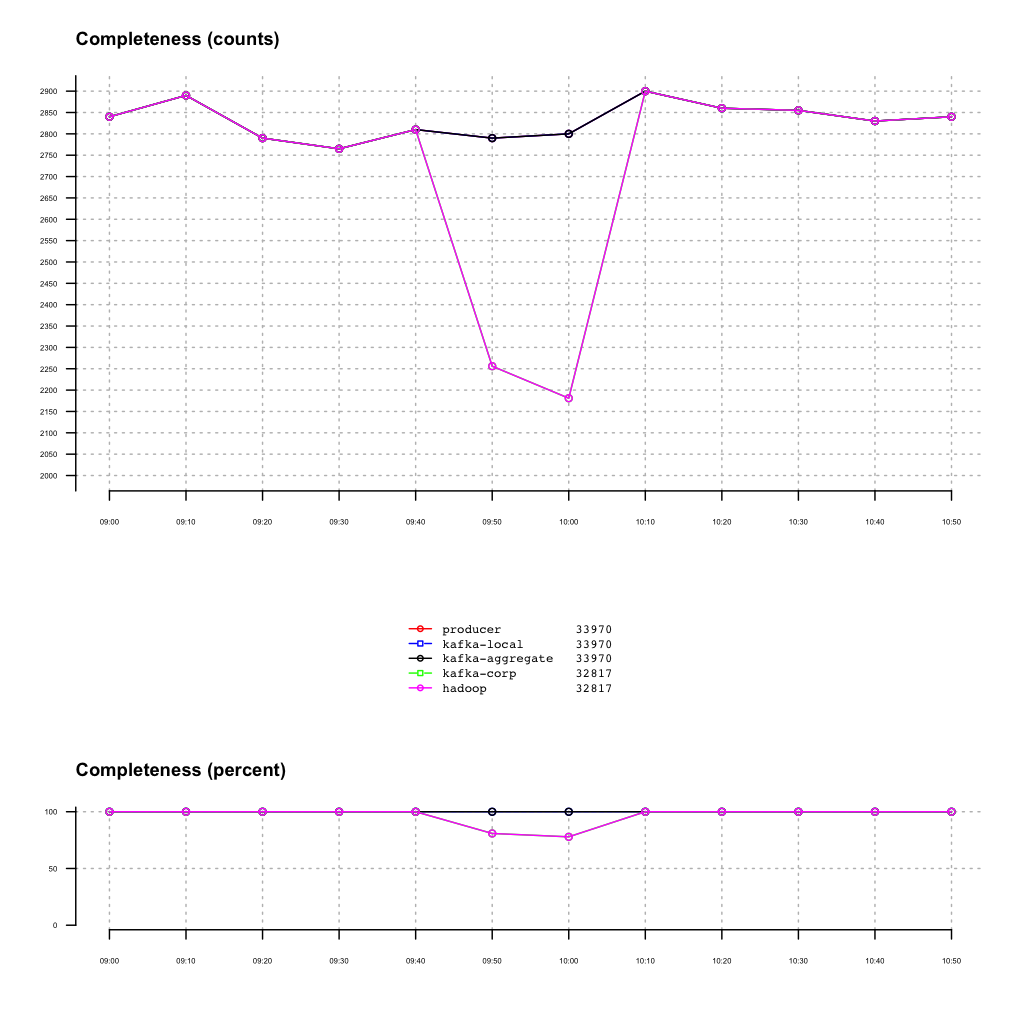
Burrow
Burrow 是一个优雅的解决监控Kafka 消费者健康这个棘手问题的方案,为消费者状态提供了一个完整的视图。它提供一个不需要指定阈值的消费者延迟检测服务,监控主题-分区粒度的所有消费者的提交偏移,并计算需要的消费者状态。
LinkedIn 的流处理
Samza 是LinkedIn 的流处理平台,让用户尽快的启动他们的流处理作业并在生产环境中运行。流处理领域一直很活跃,有许多类似的开源项目。不像其他的流处理系统专注于广泛的功能集,我们专注于让Samza可靠、高性能和可扩展。现在我们在很多生产环境中运行,所以我们可以将注意力转向扩大功能集。 早先的博客文章 深入研究了我们的生产环境场景,围绕相关性、分析、站点监控、安全等,以及我们正在研究的大量新功能。
活动预告
如果你有兴趣学习更多关于我们的Kafka 生态系统,我们怎样部署以及故障排除,我们的最新特性/用例,我们邀请你参加这些即将到来的演讲:
- 4.26: 利用Kafka 进行Espresso 数据库复制 @ Kafka summit :Espresso 是LinkedIn 的分布式文档存储,装载一些我们最重要的成员数据。 Tom Quiggle 将介绍为什么Espresso 从MySQL 的内置复制机制转向Kafka,以及Espresso 如何利用Kafka 作为复制流-一个测试Kafka 稳定性和可用性保证的用例。
- 4.26: 更多数据中心,更多问题 @ Kafka summit : Todd Palino 将讨论多数据中心和多层Kafka 集群的基本架构,和如何监控整个生态系统的实用技巧。
- 4.26: 2015年的LinkedIn 噩梦 @ Kafka summit : Joel Koshy 将深入2015年LinkedIn 在Kafka 生产环境上遇到的一些最困难和最重要的的问题。演讲会重温每一个故障和它的影响,以及检测、调查和修复的方法。
- 5.10: 构建自助服务的Kafka 系统 @ Apache: Big Data : Joel Koshy 将深入研究通过把安全、配额、RESTful API、和Nuage 整合到一起,让Kafka 成为一个真正的多租户服务。
- 5.9: 扩展流处理应用背后的秘密 @ Apache: Big Data : Navina Ramesh 讲描述Apache Samza 状态管理和容错的方法,并讨论如何有效的扩展无状态流处理应用。
- 6.28-30:Lambda-less 的流处理 @ Scale in LinkedIn @ Hadoop Summit : Yi Pan 和 Kartik Paramasivam 将通过在LinkedIn 实际使用的概述,突出Samza 作为实时流处理平台的主要优势。
我们希望在那里见到你!
感谢杜小芳对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

