自动化评估云数据中心的系统稳定性
概述
本文将要介绍如何应用自动化的方法和工具来有效地评估云数据中心的稳定性。如果从软件开发者的角度来看,我们可以对当前开发中的系统通过稳定性的测试来及时地做出设计方面的优化,保证系统今后上线运行的稳定;如果从软件测试者的角度来看,我们能够通过相关测试用例的设计和测试来尽早发现系统中潜在的稳定性问题;如果从云数据中心运维人员的角度来看,我们能够实时地监控系统中的各项性能数据指标,以便有效地制定相应的策略来更好地维护和优化云数据中心。文中将以 OpenStack 云数据中心为例,阐述云数据中心稳定性评估的一系列工具和方法,这些工具和方法同样也适用于其它云数据中心的评测。
云数据中心稳定性评估的内容
云数据中心的稳定性指标包含很多方面,本文主要围绕着系统性能的稳定性来做说明。主要包含以下几个方面:
-
云数据中心日常管理员操作的稳定性测试:包含 VMs 的批量创建和删除;Volumes 的批量创建和删除;VMs 和 Volumes 的批量快照,VMs 批量挂载和卸载 Volumes 等。
-
客户机 VM 的各项性能指标的测试:包含 VM 的 CPU 性能监控;Memory 性能监控;磁盘 IO 性能监控;网络的性能监控等。
-
各种边界性的性能测试:包括各种大并发测试;实时数据迁移的测试;OpenStack 的 HA 测试;OpenStack 和操作系统升级的测试等。
评估过程中所使用的方法和工具
图 1.OpenStack 云数据中心稳定性测试模型
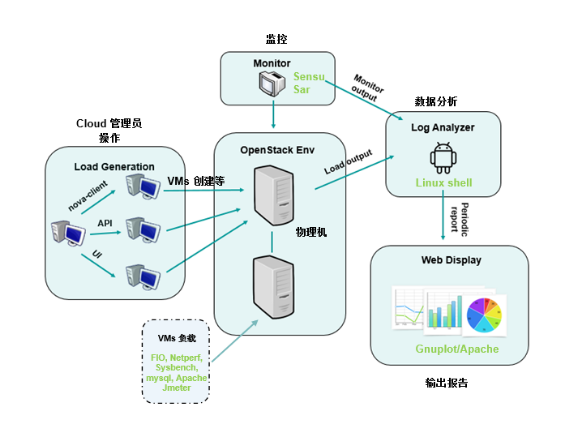
上图描述了对云数据中心稳定性评估所用到的主要思路。首先通过脚本调用 Nova-client, OpenStack API 或者是 Horizon UI 的方式对 OpenStack 的环境生成定时的批量负载(如:每半个小时批量的创建 10 个 VMs), 然后通过监控工具定时地抓取 OpenStack 的 Controller 节点和 Compute 节点的系统资源使用情况以及批量负载操作的成功率,最后通过脚本和工具自动化地将这些输出数据进行分析并定期生成科学的图形。云数据中心的运维人员可以通过这些周期生成的图表来对这段时间内的稳定性做出基本的判断,如果发现异常,也可以利用日志来对异常进行深入的分析。
同样,我们也可以对 OpenStack 环境中现有的客户机 VMs 进行监控和评估。通过一些系统负载工具来对 VMs 产生压力,然后对这些结果进行科学的分析来得到某段时间内的稳定性报告并通过图形的方式展现出来。
我们在评估稳定性的指标里也可以引入一些边界测试的用例。例如,可以通过大量的 OpenStack 操作 (如创建 VMs),来评估极限情况下云数据中心的负载能力;可以启停某些 HA 模块的服务来验证云数据中心的高可用性能力;可以实时地迁移某个 Compute 节点上的 VMs 到其他的节点上来判断云数据中心实时迁移的能力;可以对云数据中心的软硬件进行升级来衡量系统的可靠性的能力。
由于为了实现自动化的稳定性评估,在测试过程中需要使用大量的 shell 脚本和开源工具。这些脚本和工具主要用来自动化生成工作负载;自动化启动监控以及对监控结果的收集;自动化分析负载工具的输出报告或者日志;自动化生成图型以及在浏览器中展现出来。下面列出了稳定性评估中使用的主要工具:
Rally:Rally 是 OpenStack 的一个开源的子项目,用来测试 OpenStack 在并发下 API 的响应时间和请求成功率,从而测试出 OpenStack 规模和性能。在稳定性评估中用来产生大批量的 OpenStack 管理操作,如大批量创建或删除 VMs 等。
FIO:FIO 是个非常强大的 IO 性能测试工具。在稳定性评估中用来在客户机 VM 中模拟 IO 压力测试 OpenStack 的存储性能。
Sysbench:Sysbench 是一款开源的多线程性能测试工具,可以执行 CPU/内存/线程/IO/数据库等方面的性能测试。在稳定性评估中用来在客户机 VM 中测试 CPU,内存和 Mysql 数据库的性能。
Netperf:Netperf 是一个网络性能的测量工具,主要针对基于 TCP 或 UDP 的传输。在稳定性评估中用来在客户机 VM 中测试各种网络配置下的性能。
Apache webserver:Apache webserver 是开源的 Web 服务器软件。在稳定性评估中用来在客户机 VM 中测试客户端对 Web 服务器的请求和响应的性能,以及在生成稳定性报告后通过 Apache webserver 进行展现的作用。
Mysql:MySQL 是一个关系型数据库管理软件。在稳定性评估中用来在客户机 VM 中结合 Sysbench 来测试数据库的性能。
JMeter:JMeter 是 Apache 组织开发的基于 Java 的压力测试工具。在稳定性评估中用来在客户机 VM 中结合 Apache webserver 测试客户端对 web 服务器的请求和响应的性能。
Gnuplot/matplotlib:Gnuplot 和 matplotlib 都是开源的科学绘图工具。我们通过这些工具在稳定性评估中将稳定性的测试数据生成图形报告。
Sensu:是开源的监控框架。在稳定性评估中用来监控 OpenStack 的各节点性能。
Linux shell/OpenStack API/Crontab: 在稳定性评估中需要编写一些自动化执行的 shell 脚本来操作 OpenStack 和测试工具,然后通过 Crontab 来定时执行,对输出结果进行分析得到可生成图形报告的数据。
根据具体需求设计自动化框架来执行稳定性评估
在做稳定性评估之前,我们要根据具体的需求来设计评估用例。用例的设计应该尽量接近云数据中心实际生产运营中的场景,这样我们所模拟的工作负载才能更加真实地反映出系统上线的结果。例如我们可以通过考虑云数据中心在某一段时间内创建 VMs 的成功率和响应时间来判断 OpenStack 在运维中的稳定性。
当用例确定后,接下来我们需要设计自动化的脚本。在脚本里我们可能会调用到一些自动化的工具来执行你的用例,例如我们可以利用 Rally 或者 Nova-client 来创建和删除批量的 VMs,然后通过 Linux Crontab 工具在后台周期行地执行这个脚本。下面这段脚本是描述 OpenStack 将在每隔一小时的整点创建 10 台 VM。
***Crontab create 10 VMs every hour*** 0 */1 * * * /bin/bash /home/stest/createVMs.sh ***createVMs.sh*** #create 10 VMs every hour log_date=$(date +%Y%m%d) echo $(date +%Y%m%d-%H:%M:%S)_"create 10 vms on every hour clock" >>/root/stest/log/createVMs_$log_date.log for i in $(seq 1 10); do /usr/bin/nova boot --image <vm_image> --flavor <vm_flavor> sbtest-vm-${i} >>/root/stest/log/createVMs_$log_date.log & done 在创建这些 VMs 后,我们还需要判断这些 VMs 是否创建成功以及成功创建所需要的时间,这些指标都是我们需要生成最终报告的依据,收集这些数据的过程可以通过脚本来实现或者调用 Rally,Rally 可以自动生成这些结果。
这里再举一个例子。我们要评估客户机 VM 在相同子网不同 Compute 节点的网络传输性能的稳定性。在这项评估中,我们使用设计了 4 个用例,分别是 bulk TCP 测试、bulk UDP 测试、request/response DataBase simulation 测试、request/response HTTP simulation 测试,利用 netperf 工具,在 IP 地址为 192.168.32.2 的 client 主机向 IP 地址为 192.168.32.39 的 server 主机发送测试。其中 bulk TCP 测试、bulk UDP 测试分别由 client 主机向 server 主机批量传输 TCP、UDP 数据段,DataBase simulation 测试是发生在同一个 TCP 连接中的多个 request/response 交易过程,而 request/response HTTP simulation 测试是为每个 request/response 交易建立一个新的 TCP 连接。测试主机分别位于不同的 compute 节点上。下面的脚本描述了每隔 10 分钟,顺序进行上述测试:
***Crontab netperf test every 10 minutes*** */10 * * * * /bin/bash /home/stest/netperftest.sh ***netperftest.sh*** #!/bin/bash log_date=$(date +%Y%m%d) host_name=$(hostname) #bulk network throughput test between same subnets on different hosts(TCP) echo $(date +%Y%m%d-%H:%M:%S)_"netperf bulk TCP test" >> $vm_perflog_path/netperftest_"$host_name"_"$log_date".log $netperf_path/netperf -H 192.168.32.39 >> $vm_perflog_path/netperftest_"$host_name"_"$log_date".log #bulk network throughput test between same subnet on different hosts(UDP) #echo $(date +%Y%m%d-%H:%M:%S)_"netperf bulk UDP test" >> $vm_perflog_path/netperftest_"$host_name"_"$log_date".log #$netperf_path/netperf -H 192.168.32.39 -t UDP_STREAM -- -m 1426 >> $vm_perflog_path/netperftest_"$host_name"_"$log_date".log #request/response DB simulation test between same subnets on different host(TCP) #echo $(date +%Y%m%d-%H:%M:%S)_"netperf request-response DB simulation test" >> $vm_perflog_path/netperftest_"$host_name"_"$log_date".log #$netperf_path/netperf -t TCP_RR -H 192.168.32.39 -- -r 64,1024 >> $vm_perflog_path/netperftest_"$host_name"_"$log_date".log #request/response HTTP simulation test between same subnets on different host(TCP) #echo $(date +%Y%m%d-%H:%M:%S)_"netperf request-response HTTP simulation test" >> $vm_perflog_path/netperftest_"$host_name"_"$log_date".log #$netperf_path/netperf -t TCP_CRR -H 192.168.32.39 -- -r 64,1024 >> $vm_perflog_path/netperftest_"$host_name"_"$log_date".log
netperf 工具测试产生的结果全部保存在 netperftest_"$host_name"_"$log_date".log 文件中。
以此类推,我们可以根据需求来设计自动化脚本,例如利用 FIO 工具来测试云数据中心存储的稳定性;利用 Sysbench 结合 Mysql,Apache webserver 结合 Jmeter 来测试客户机 VM 的应用稳定性;利用 rally 工具来进行大规模的创建,删除 VMs 的并发测试等等。
如何自动化的生成稳定性评估报告
当我们得到了稳定性评估的数据后,接下来要通过脚本来对这些数据进行分析并生成可以形成图形的规则数据,再通过 Gnuplot 这个制图工具绘制成图。下面这段脚本描述了利用 Gnuplot 生成计算 OpenStack 创建 VMs 成功率的图形,其中文件 createvms_rate_date 里存储着当天每小时创建 10 个 VMs 的成功率的数据。
***createvms_rate_date*** TimeTotalPassed 20151120-00:10:011010 20151120-01:10:011010 20151120-02:10:011010 … ***gnuplot create VM rate chart*** gnuplot<<EOF set term svg set xdata time set timefmt '%H:%M:%S' set format x '%H' set title "create_vm_rate" set xlabel 'TIME(hour)' set ylabel 'Numbers of Passed' set xrang["00:00:00":"23:00:00"] set yrang[0:12] set output "/root/stest/chart/createvms_rate_date.svg" set style fill solid set style data boxes set boxwidth 0.8 relative plot "/root/stest/result/createvms_rate_date" using 1:3 title "passed" EOF
在得到了输出图形后,我们可以利用 Apache webserver 将图形展示在 html 的页面中, 然后通过 Crontab 在我们规定的周期内生成稳定性报告,例如定时地为每天、每周或每月创建 VMs 成功率的报告。
在网络测试中,bulk TCP 和 bulk UDP 测试需要的数据是吞吐量(Throughput,10^6 bit/s),其中 bulk UDP 测试中需要取出发送端和接收端的数据,request/response DataBase simulation 测试和 request/response HTTP simulation 测试需要的数据是传输率(Transfer rate per second)。下面两个文件分别保存了 bulk TCP 测试和 bulk UDP 测试生成图形报告所需要的数据:
***bulk_TCP_test_date*** 20151113-10:00:01 2016.08 20151113-10:10:01 2109.95 20151113-10:20:01 2265.50 … ***bulk_UDP_test_date*** 20151114-00:00:01 2507.88 961.12 20151114-00:10:01 2777.44 855.62 20151114-00:20:01 2655.93 817.37 …
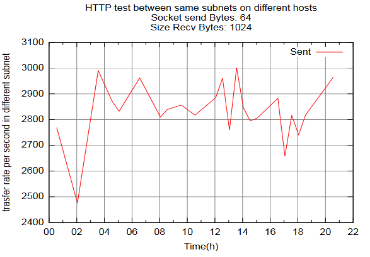
request/response DataBase simulation 测试和 request/response HTTP simulation 测试需要的数据形式和文件 bulk_TCP_test_date 中形式类似,这里不再赘述。利用上述形式的数据,我们就可以通过 gnuplot 生成图形。下图即是某天生成的 request/response HTTP simulation 测试的图像:
图 2. 模拟 HTTP 请求的网络吞吐率
为了观察数据的稳定性以及保证统计的准确性,我们引入了统计学中变异系数(Coefficient of Variation )的概念。变异系数的数学意义是标准差和平均值的比值,主要用于表示数据的波动情况,定义如下面公式:
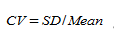
其中,SD 表示标准差,Mean 表示平均值。
从统计学角度来看,变异系数大于 15%表示取样数据不可信,而在我们当前的测试中也可以将其认为是测试环境不稳定导致的结果。下图是若干天 request/response simulation HTTP 的测试结果,其中红色实线代表当天测得的最小值、最大值和平均值,绿色实线代表了计算的变异系数。
图 3. 某段时间内模拟 HTTP 请求的网络波动
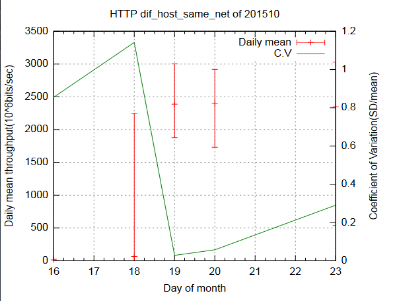
可以看到,部分测试结果很不稳定,对于这一点分析将在后面具体叙述。
通过稳定性报告如何进一步分析和优化
在我们得到自动生成的稳定性评估报告后,接下来我们可以进一步的根据结果来分析和优化系统的稳定性。在这里我们会分析两个例子,第一个例子是关于 Apache webserver 的优化。在我们测试过程中发现我们的 Apache webserver 对 http get 的吞吐率始终达不到预期的标准,我们的 VM 配置是 16core,64GB RAM,但 Jmeter 测试得到 TPS(每秒交易数)只有几百多。通过分析我们发现 Apache webserver 的 max clients 配置的太低,以及 linux open files 过低导致 TPS 上不去,我们将做出如下的优化。
修改 open files 的数值永久生效,编辑文件/etc/security/limits.conf. 在这个文件后加上:
*softnofile10240 *hardnofile10240
修改 max clients,编辑文件/etc/apache2/apache2.conf:
<IfModule mpm_worker_module> MinSpareThreads 350 MaxSpareThreads 700 MaxClients 7000 </IfModule>
经过如上改动后重启 VM 确保改动生效,再通过 Jmeter 测试发现 TPS 已经可以稳定地保持在 2700 左右。
另一个例子是关于网络的优化。除了上面提到的 HTTP 测试中的不稳定现象,我们还发现在其他使用 TCP 协议的测试中都或多或少的出现了测试结果不稳定现象。在我们测试环境中,VM 之间的带宽是 1Gbit/sec,而实际测试中,部分时间点的测试结果远达不到这个数据。经过分析,我们认为是 socket 接收缓冲区过小导致了这一结果。我们在 VM、宿主机上分别运行下面命令来增大 socket 接收缓冲区:
sysctl -w net.core.rmem_max=33554432 sysctl -w net.core.rmem_default=33554432
经过优化,重新测试发现数据稳定性大幅提高,根据基于 TCP 的测试的取样数据计算出的变异系数可以控制在 0.1 以内,性能也接近实际带宽。
测试:验证自动化评估流程的可行性
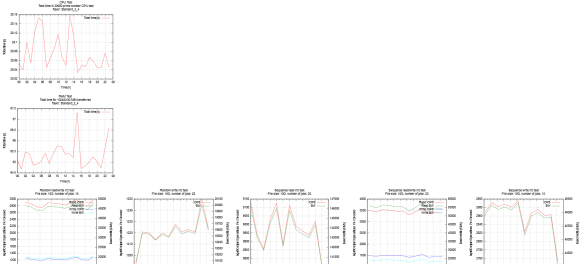
从我们对云数据中心稳定性需求的分析,测试用例的设计,脚本和工具的开发,测试报告的生成,到调优和验证。 以及这当中的每一个环节通过 Crontab 的自动化调度,来实现我们的自动化评估。下图是我们对某一天内客户机 VM 的 CPU,RAM 和 IO 的稳定性报告的截图。
图 4. 某天数据中心虚机的稳定性输出报告
结束语
在云数据中心涉及到的系统稳定性评估的内容会多种多样,这需要我们结合具体的评估需求来灵活设计相关的用例,有效地利用现有的开源工具达到我们的测试目的。读者可以结合本文中的一些方法和思路来自行设计相关的稳定性评估,提供能够反映出云数据中心真实运行状况的稳定性评估报告。
正文到此结束
- 本文标签: 2015 apache IBM 压力 多线程 组织 lib 删除 java tab 线程 API HTML client 云 测试 数据库 管理 JMeter Developer http mysql 协议 数据 UDP 开源 主机 linux 服务器 ip 开发者 TCP 开发 运营 自动生成 root shell UI 时间 操作系统 统计 ORM apache2 自动化 配置 需求 软件 core Security web db sql OpenStack 软件开发者 src
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

