Pandas 数据结构简介
前段时间我说过我会写一些关于 Pandas 的文章,但是我却一直没有跟进。然而,本周两位同事向我表达了他们对于 Pandas 的学习兴趣,因此我打算重新讨论这个话题。
因为我觉得这是一个庞大的任务,所以下面我将分成三个部分来全面地介绍 Pandas 库:
- Part 1:
Pandas数据结构简介,该部分主要介绍该库的两个基本数据结构—— Series 和 DataFrames。 - Part 2:
DataFrames的使用方法,该部分主要介绍如何使用 DataFrames 的筛选、过滤、合并、联合以及分组功能。 - Part 3: 利用
Pandas处理 MovieLens 数据集,该部分主要利用前两部分的内容来回答关于 MovieLens 收视率数据的几个基本分析的问题。
如果你想跟着文章的内容运行相应代码的话,你可以在 这里 下载到相关 CSV 数据和 MovieLens 数据。
本篇文章的目的在于通过比较 Pandas 与 SQL 之间的差异来介绍该库的基本用法。由于我的同事都非常熟悉 SQL 的语法,所以我觉得这是一个易于被读者所理解的写作方法。
如果你想要学习更多的 Pandas 知识,你可以阅读 Pandas 作者撰写的书籍《Python for Data Analysis》。
Pandas 是 Python中用于分析数据的常用开源库。Python 可以很好地预处理和加工数据,但是它无法很好地进行数据分析——通常情况下你会利用 R 或者 SQL 来分析数据。有了 Pandas 之后,我们可以利用 Python 快速地进行数据分析。
数据结构
Pandas 中引入了两种新的数据结构—— Series 和 DataFrame ,这两种数据结构都建立在 NumPy 的基础之上。
In [2]:
import pandas as pd import numpy as np import matplotlib.pyplot as plt pd.set_option("max_columns", 50) %matplotlib inline Series
Series是指一个类似于数组、列表或列变量的一维对象, Series 中每个条目都会被分配一个标签索引。默认情况下,每个条目都会收到一个从0到N之间的索引标签,其中N等于 Series 的长度减一。
In [3]:
# create a Series with an arbitrary list s = pd.Series([7, 'Heisenberg', 3.14, -1789710578, 'Happy Eating!']) s
Out[3]:
0 7 1 Heisenberg 2 3.14 3 -1789710578 4 Happy Eating! dtype: object
Series可以直接转换词典格式的数据,其中词典的键值对应 Series 中的索引值。
In [4]:
d = {'Chicago': 1000, 'New York': 1300, 'Portland': 900, 'San Francisco':1100, 'Austin': 450, 'Boston': None} cities = pd.Series(d) cities Out[4]:
Austin 450 Boston NaN Chicago 1000 New York 1300 Portland 900 San Francisco 1100 dtype: float64
你可以利用索引从 Series 中提取出特定的条目。
In [5]:
cities['Chicago']
Out[5]:
1000.0
In [6]:
cities[['Chicago', 'Portland', 'San Francisco']]
Out[6]:
Chicago 1000 Portland 900 San Francisco 1100 dtype: float64
或者你也可以利用布尔索引值来选取数据。
In [7]:
cities[cities < 1000]
Out[7]:
Austin 450 Portland 900 dtype: float64
第二种方法可能看起来有点奇怪,所以让我们更清楚地了解下它的逻辑—— cities < 1000 将返回一系列逻辑值,然后我们可以利用这些值从 Series 中提取出相应的条目。
In [8]:
less_than_1000 = cities < 1000 print(less_than_1000) print('/n') print(cities[less_than_1000]) Austin True Boston False Chicago False New York False Portland True San Francisco False dtype: bool Austin 450 Portland 900 dtype: float64
我们还可以更改 Series 中的数值。
In [9]:
# changing based on the index print('Old value', cities['Chicago']) cities['Chicago'] = 1400 print('New value', cities['Chicago']) ('Old value', 1000.0) ('New value', 1400.0) In [10]:
# changing values using boolean logic print(cities[cities < 1000]) print('/n') cities[cities < 1000] = 750 print(cities[cities < 1000]) Austin 450 Portland 900 dtype: float64 Austin 750 Portland 750 dtype: float64
如果你不确定 Series 中是否存在某个条目,你可以利用 Python 代码来检测。
In [11]:
print('Seattle' in cities) print('San Francisco' in cities) False True
我们还可以对 Series 进行数学运算和函数运算。
In [12]:
# divide city value by 3 cities / 3
Out[12]:
Austin 250.000000 Boston NaN Chicago 466.666667 New York 433.333333 Portland 250.000000 San Francisco 366.666667 dtype: float64
In [13]:
# square city values np.square(cities)
Out[13]:
Austin 562500 Boston NaN Chicago 1960000 New York 1690000 Portland 562500 San Francisco 1210000 dtype: float64
此外你还可以汇总两个 Series ,这会返回两个 Series 的并集,其中没有共同索引的条目将会返回 NULL/NaN。
In [14]:
print(cities[['Chicago', "New York", "Portland"]]) print('/n') print(cities[['Austin', 'New York']]) print('/n') print(cities[['Chicago', 'New York', 'Portland']] + cities[['Austin', 'New York']]) Chicago 1400 New York 1300 Portland 750 dtype: float64 Austin 750 New York 1300 dtype: float64 Austin NaN Chicago NaN New York 2600 Portland NaN dtype: float64
由于两个 Series 中没有同时包含Austin,Chicago和Portland,因此它们的返回值是 NULL/NaN。
我们可以利用 isnull 和 notnull 函数来检测 NULL 值。
In [15]:
# returns a boolean series indicating which values aren't NULL cities.notnull()
Out[15]:
Austin True Boston False Chicago True New York True Portland True San Francisco True dtype: bool
In [16]:
# use boolean logic to grab the NULL cities print(cities.isnull()) print('/n') print(cities[cities.isnull()]) Austin False Boston True Chicago False New York False Portland False San Francisco False dtype: bool Boston NaN dtype: float64
DataFrame
DataFrame是一种由列向量和行向量组成的数据结构,它类似于电子数据表、数据库表格和 R 语言中的 data.frame 对象。你也可以理解成 DataFrame 是由多个共享索引值的 Series 对象构成的。
本文的剩下篇幅中,我将主要介绍 DataFrame 的内容。
Reading Data
我们可以将 Python 中常用的数据结构(如词典列表)转换成 DataFrame ,其中通过控制 columns 的参数值可以调整变量的顺序。默认情况下, DataFrame 会按字母顺序对变量进行排序。
In [18]:
data = {'year': [2010, 2011, 2012, 2011, 2012, 2010, 2011, 2012], 'team': ['Bears', 'Bears', 'Bears', 'Packers', 'Packers', 'Lions', 'Lions', 'Lions'], 'wins': [11, 8, 10, 15, 11, 6, 10, 4], 'losses': [5, 8, 6, 1, 5, 10, 6, 12]} football = pd.DataFrame(data, columns=['year', 'team', 'wins', 'losses']) football Out[18]:
| year | team | wins | losses | |
|---|---|---|---|---|
| 0 | 2010 | Bears | 11 | 5 |
| 1 | 2011 | Bears | 8 | 8 |
| 2 | 2012 | Bears | 10 | 6 |
| 3 | 2011 | Packers | 15 | 1 |
| 4 | 2012 | Packers | 11 | 5 |
| 5 | 2010 | Lions | 6 | 10 |
| 6 | 2011 | Lions | 10 | 6 |
| 7 | 2012 | Lions | 4 | 12 |
更多情况下,我们需要将数据集读到 DataFrame 中,接下来我们将介绍几种常用的读取数据的方法。
CSV
我们可以利用 read.csv 函数来读取 CSV 文件,其中 read.csv 函数默认CSV数据集是以逗号分隔的,你可以通过 sep 参数来控制分隔符的类别。
In [19]:
%cd ~/Desktop/
/Users/zengphil/Desktop
In [20]:
# Source: baseball-reference.com/players/r/riverma01.shtml !head -n 5 mariano-rivera.csv
Year,Age,Tm,Lg,W,L,W-L%,ERA,G,GS,GF,CG,SHO,SV,IP,H,R,ER,HR,BB,IBB,SO,HBP,BK,WP,BF,ERA+,FIP,WHIP,H9,HR9,BB9,SO9,SO/W,Awards 1995,25,NYY,AL,5,3,.625,5.51,19,10,2,0,0,0,67.0,71,43,41,11,30,0,51,2,1,0,301,84,5.15,1.507,9.5,1.5,4.0,6.9,1.70, 1996,26,NYY,AL,8,3,.727,2.09,61,0,14,0,0,5,107.2,73,25,25,1,34,3,130,2,0,1,425,240,1.88,0.994,6.1,0.1,2.8,10.9,3.82,CYA-3MVP-12 1997 ★,27,NYY,AL,6,4,.600,1.88,66,0,56,0,0,43,71.2,65,17,15,5,20,6,68,0,0,2,301,239,2.96,1.186,8.2,0.6,2.5,8.5,3.40,ASMVP-25
In [23]:
from_csv = pd.read_csv('mariano-rivera.csv') from_csv.head() Out[23]:
| Year | Age | Tm | Lg | W | L | W-L% | ERA | G | GS | GF | CG | SHO | SV | IP | H | R | ER | HR | BB | IBB | SO | HBP | BK | WP | BF | ERA+ | FIP | WHIP | H9 | HR9 | BB9 | SO9 | SO/W | Awards | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1995 | 25 | NYY | AL | 5 | 3 | .625 | 5.51 | 19 | 10 | 2 | 0 | 0 | 0 | 67.0 | 71 | 43 | 41 | 11 | 30 | 0 | 51 | 2 | 1 | 0 | 301 | 84 | 5.15 | 1.507 | 9.5 | 1.5 | 4.0 | 6.9 | 1.70 | NaN |
| 1 | 1996 | 26 | NYY | AL | 8 | 3 | .727 | 2.09 | 61 | 0 | 14 | 0 | 0 | 5 | 107.2 | 73 | 25 | 25 | 1 | 34 | 3 | 130 | 2 | 0 | 1 | 425 | 240 | 1.88 | 0.994 | 6.1 | 0.1 | 2.8 | 10.9 | 3.82 | CYA-3MVP-12 |
| 2 | 1997 ★ | 27 | NYY | AL | 6 | 4 | .600 | 1.88 | 66 | 0 | 56 | 0 | 0 | 43 | 71.2 | 65 | 17 | 15 | 5 | 20 | 6 | 68 | 0 | 0 | 2 | 301 | 239 | 2.96 | 1.186 | 8.2 | 0.6 | 2.5 | 8.5 | 3.40 | ASMVP-25 |
| 3 | 1998 | 28 | NYY | AL | 3 | 0 | 1.000 | 1.91 | 54 | 0 | 49 | 0 | 0 | 36 | 61.1 | 48 | 13 | 13 | 3 | 17 | 1 | 36 | 1 | 0 | 0 | 246 | 233 | 3.48 | 1.060 | 7.0 | 0.4 | 2.5 | 5.3 | 2.12 | NaN |
| 4 | 1999 ★ | 29 | NYY | AL | 4 | 3 | .571 | 1.83 | 66 | 0 | 63 | 0 | 0 | 45 | 69.0 | 43 | 15 | 14 | 2 | 18 | 3 | 52 | 3 | 1 | 2 | 268 | 257 | 2.92 | 0.884 | 5.6 | 0.3 | 2.3 | 6.8 | 2.89 | ASCYA-3MVP-14 |
该函数默认将文件中的第一行设定为列变量的标题,我们还可以设定 header=None 来手动设定列标题。
In [25]:
# Source: pro-football-reference.com/players/M/MannPe00/touchdowns/passing/2012/ !head -n 6 peython-passing-TDS-2012.csv
Rk,G#,Date,Tm,,Opp,Result,Quarter,Dist,Scorer/Receiver,Score Before,Score After 1,1,2012-09-09,DEN,,PIT,W 31-19,3,71,Demaryius Thomas,Trail 7-13,Lead 14-13* 2,1,2012-09-09,DEN,,PIT,W 31-19,4,1,Jacob Tamme,Trail 14-19,Lead 22-19* 3,2,2012-09-17,DEN,@,ATL,L 21-27,2,17,Demaryius Thomas,Trail 0-20,Trail 7-20 4,3,2012-09-23,DEN,,HOU,L 25-31,4,38,Brandon Stokley,Trail 11-31,Trail 18-31
In [27]:
cols = ['num', 'game', 'date', 'team', 'home_away', 'opponent', 'result', 'quarter', 'distance', 'receiver', 'score_before', 'score_after'] no_headers = pd.read_csv('peython-passing-TDS-2012.csv', sep = ',', header=None, names=cols) no_headers.head() Out[27]:
| num | game | date | team | home_away | opponent | result | quarter | distance | receiver | score_before | score_after | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Rk | G# | Date | Tm | NaN | Opp | Result | Quarter | Dist | Scorer/Receiver | Score Before | Score After |
| 1 | 1 | 1 | 2012-09-09 | DEN | NaN | PIT | W 31-19 | 3 | 71 | Demaryius Thomas | Trail 7-13 | Lead 14-13* |
| 2 | 2 | 1 | 2012-09-09 | DEN | NaN | PIT | W 31-19 | 4 | 1 | Jacob Tamme | Trail 14-19 | Lead 22-19* |
| 3 | 3 | 2 | 2012-09-17 | DEN | @ | ATL | L 21-27 | 2 | 17 | Demaryius Thomas | Trail 0-20 | Trail 7-20 |
| 4 | 4 | 3 | 2012-09-23 | DEN | NaN | HOU | L 25-31 | 4 | 38 | Brandon Stokley | Trail 11-31 | Trail 18-31 |
Pandas 的 reader 系列函数中有许多可控参数,用于控制读取数据时的其他设定。
大家可以参阅 IO文档 来熟悉文件读取/写入功能。
Excel
你们讨厌 VBA 吗?我非常讨厌它,我相信你也会讨厌它的。幸运的是, pandas 允许我们读写 Excel 文件,所以我们可以利用Python处理完数据后再导出Excel文件,这样可以规避使用烦人的VBA来处理数据。
读取Excel文件需要安装 xlrd 库,我们可以利用 pip 工具来安装它( pip install xlrd )。
In [28]:
# this is the DataFrame we created from a dictionary earlier football.head()
Out[28]:
| year | team | wins | losses | |
|---|---|---|---|---|
| 0 | 2010 | Bears | 11 | 5 |
| 1 | 2011 | Bears | 8 | 8 |
| 2 | 2012 | Bears | 10 | 6 |
| 3 | 2011 | Packers | 15 | 1 |
| 4 | 2012 | Packers | 11 | 5 |
In [29]:
# since our index on the football DataFrame is meaningless, let's not write it football.to_excel('football.xlsx', index=False) In [32]:
!ls -l *.xlsx
-rw-r--r-- 1 zengphil staff 5588 4 23 10:56 football.xlsx
In [33]:
# delete the DataFrame del football
In [35]:
# read from Excel football = pd.read_excel('football.xlsx', 'Sheet1') football Out[35]:
| year | team | wins | losses | |
|---|---|---|---|---|
| 0 | 2010 | Bears | 11 | 5 |
| 1 | 2011 | Bears | 8 | 8 |
| 2 | 2012 | Bears | 10 | 6 |
| 3 | 2011 | Packers | 15 | 1 |
| 4 | 2012 | Packers | 11 | 5 |
| 5 | 2010 | Lions | 6 | 10 |
| 6 | 2011 | Lions | 10 | 6 |
| 7 | 2012 | Lions | 4 | 12 |
Database
Pandas 还可以直接从数据库中读写 DataFrame 文件,你只需要利用 pandas.io 模块中的 read_sql 或 to_sql 函数来创建一个连接数据库的对象即可。
需要注意的是, to_sql 直接调用 INSERT INTO 语句,因此数据的传输速度比较慢。如果你想将一个大型 DataFrame 写入数据库中,最好先导出CSV文件然后再导入数据库中。
In [38]:
from pandas.io import sql import sqlite3 conn = sqlite3.connect('/Users/zengphil/Downloads/Database') query = "SELECT * FROM towed WHERE make = 'FORD';" results = sql.read_sql(query, con = conn) results.head() Clipboard
相比于直接将查询结果插入 DataFrame 中,我更倾向于从剪贴板中读取数据。Python可以很好地处理剪贴板中的分隔符数据,你可以控制 sep 参数来设定数据分隔符。
Hank Aaron
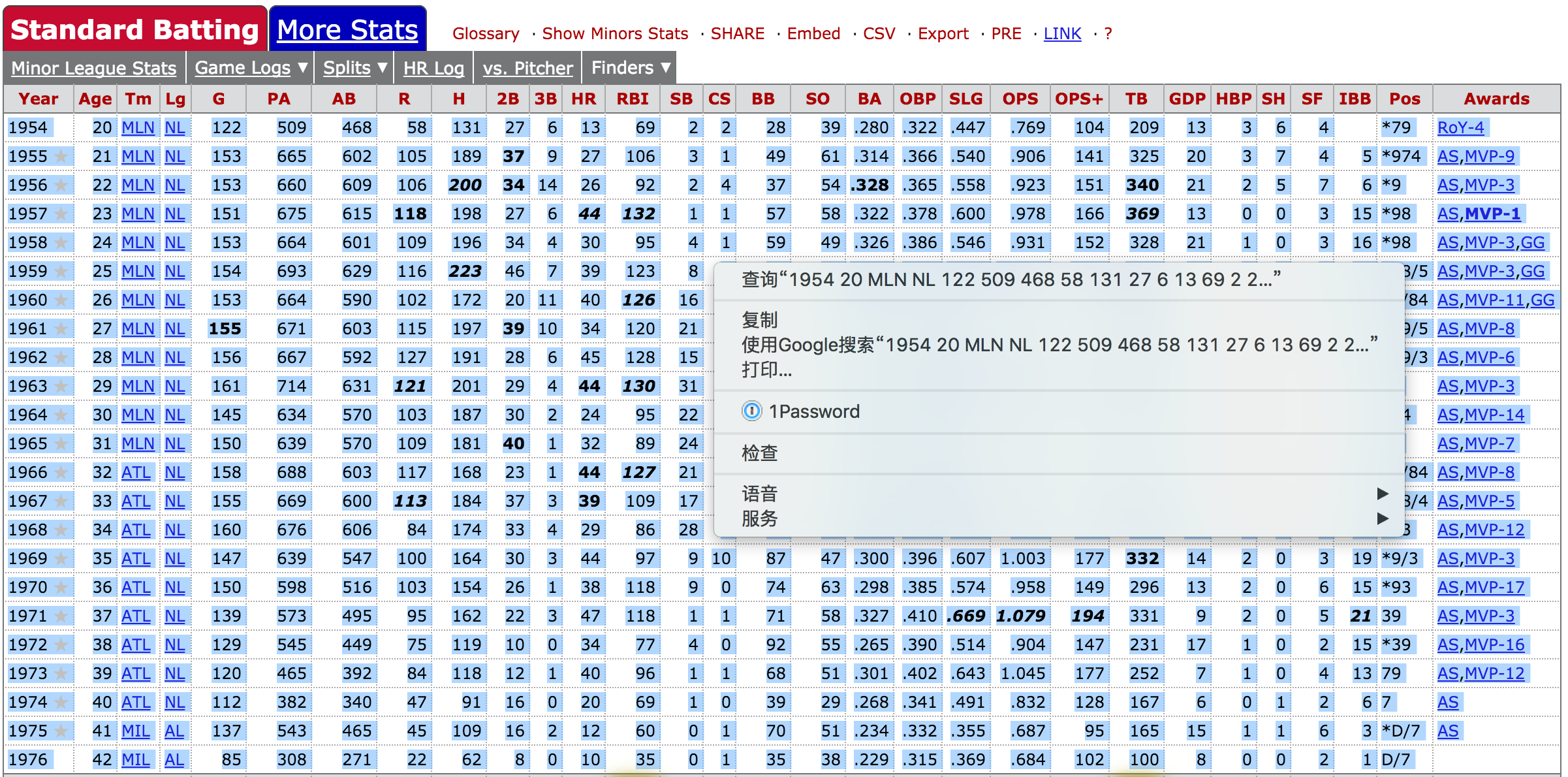
In [39]:
hank = pd.read_clipboard() hank.head()
Out[39]:
| 1954 | 20 | MLN | NL | 122 | 509 | 468 | 58 | 131 | 27 | 6 | 13 | 69 | 2 | 2.1 | 28 | 39 | .280 | .322 | .447 | .769 | 104 | 209 | 13.1 | 3 | 6.1 | 4 | Unnamed: 27 | *79 | RoY-4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1955 ★ | 21 | MLN | NL | 153 | 665 | 602 | 105 | 189 | 37 | 9 | 27 | 106 | 3 | 1 | 49 | 61 | 0.314 | 0.366 | 0.540 | 0.906 | 141 | 325 | 20 | 3 | 7 | 4 | 5 | *974 | AS,MVP-9 |
| 1 | 1956 ★ | 22 | MLN | NL | 153 | 660 | 609 | 106 | 200 | 34 | 14 | 26 | 92 | 2 | 4 | 37 | 54 | 0.328 | 0.365 | 0.558 | 0.923 | 151 | 340 | 21 | 2 | 5 | 7 | 6 | *9 | AS,MVP-3 |
| 2 | 1957 ★ | 23 | MLN | NL | 151 | 675 | 615 | 118 | 198 | 27 | 6 | 44 | 132 | 1 | 1 | 57 | 58 | 0.322 | 0.378 | 0.600 | 0.978 | 166 | 369 | 13 | 0 | 0 | 3 | 15 | *98 | AS,MVP-1 |
| 3 | 1958 ★ | 24 | MLN | NL | 153 | 664 | 601 | 109 | 196 | 34 | 4 | 30 | 95 | 4 | 1 | 59 | 49 | 0.326 | 0.386 | 0.546 | 0.931 | 152 | 328 | 21 | 1 | 0 | 3 | 16 | *98 | AS,MVP-3,GG |
| 4 | 1959 ★ | 25 | MLN | NL | 154 | 693 | 629 | 116 | 223 | 46 | 7 | 39 | 123 | 8 | 0 | 51 | 54 | 0.355 | 0.401 | 0.636 | 1.037 | 182 | 400 | 19 | 4 | 0 | 9 | 17 | *98/5 | AS,MVP-3,GG |
URL
此外,我们还可以利用 read_table 函数直接从 URL 链接中读取数据。
In [40]:
url = 'https://raw.github.com/gjreda/best-sandwiches/master/data/best-sandwiches-geocode.tsv' # fetch the text from the URL and read it into a DataFrame from_url = pd.read_table(url, sep='/t') from_url.head(3)
Out[40]:
| rank | sandwich | restaurant | description | price | address | city | phone | website | full_address | formatted_address | lat | lng | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | BLT | Old Oak Tap | The B is applewood smoked—nice and snapp... | $10 | 2109 W. Chicago Ave. | Chicago | 773-772-0406 | theoldoaktap.com | 2109 W. Chicago Ave., Chicago | 2109 West Chicago Avenue, Chicago, IL 60622, USA | 41.895734 | -87.679960 |
| 1 | 2 | Fried Bologna | Au Cheval | Thought your bologna-eating days had retired w... | $9 | 800 W. Randolph St. | Chicago | 312-929-4580 | aucheval.tumblr.com | 800 W. Randolph St., Chicago | 800 West Randolph Street, Chicago, IL 60607, USA | 41.884672 | -87.647754 |
| 2 | 3 | Woodland Mushroom | Xoco | Leave it to Rick Bayless and crew to come up w... | $9.50. | 445 N. Clark St. | Chicago | 312-334-3688 | rickbayless.com | 445 N. Clark St., Chicago | 445 North Clark Street, Chicago, IL 60654, USA | 41.890602 | -87.630925 |
Google Analytics
Pandas 还整合了 Google Analytics 的API接口,但是需要进行一些设置。本文没有介绍这些内容,你可以参阅 文章1 和 文章2 。
原文链接: http://gregreda.com/2013/10/26/intro-to-pandas-data-structures/
原文作者:Greg Reda
译者:Fibears
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

