站在运维的角度讲如何打造一个docker->mesos平台
摘要
大多数同学都是在技术角度来看待docker平台,但是对于如何快速、良好、正确、健康的使用docker/saas技术、运维维护却少有人提,到底搭建一个生产级的docker平台需要结合哪些情况综合考虑、规划?本文将从运维的角度出发,结合真实的案例来讲述如何快速打造一个docker平台。可能本文不是技术性的干货,但是提到的问题点或许都会成为平台路上的绊脚石。
Body
我们公司目前的状态
> 大概从15年9月份开始正式启动docker的mesos平台;目前的进度是业务级应用的测试正在收尾(压力测试)。运维这一块一直是我来负责,踩的坑比较多,所以会在运维的角度来谈下如何高效、快速的搭建docker平台。
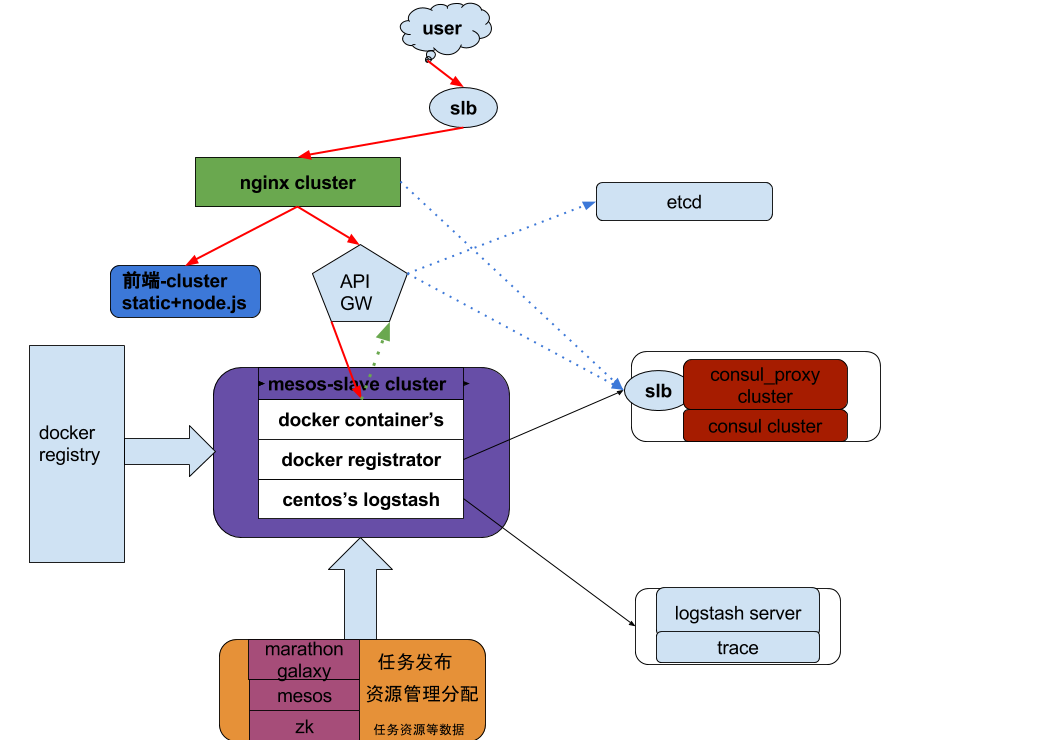
下面是目前我们用到的一些组件的架构图(细节的地方些许有些变动与不完善)。由于这套架构的每个组件基本都为开源,这里不做过多的细分、介绍。
为什么有这样的分享?
运维的角度不同,目前很多人都只关注技术本身,而非技术带来的价值;灾备方案等也很难完整的考虑,而且SRE/SLA等名词逐渐”火”了起来,所以我才思考打算分享这篇文档(某些地方写的还不是很完整,希望大家多多指出,给予谅解)。
第一章:准备工作-背景(成本)
为什么要把成本放在第一位?想必没有老板会出于新技术而采用新技术,在意的肯定是技术带来的价值,远景上来看肯定是存在金钱的问题的,要么赚钱、要么省钱、要么就是名气带来的价值。O(∩_∩)O~
当时打算大规模的使用docker平台的时候,你便需要考虑成本这一块的问题了:
- 业务
- 技术
- 人员
- 时间
都知道docker技术目前非常火,那么真的适不适合自己的公司,换句话说要说服自己的老板来做大换血,来做这种投入、方案;以上的四个是关联级的关系:
适不适合目前的业务?优点在哪里?技术方案到底如何选型?到底投入多少人?投入多少时间成本?
其中每一条都几乎与钱有莫大的关系。
业务
这里需要做好业务上的分析,使用PAAS平台很大一部分都是从资源使用率出发的,我们公司也不例外。比如我们公司现在的部署结构存在非常大的浪费(单用户独享多实例),从而造成每种实例可能达到上千个(这里本来我很想用一张图诠释我们业务的复杂度,最后放弃了,我们的业务我估计得用快10张PPT。囧),使用docker资源管理平台
①是可以趁机将业务做划分,多用户共享实例,将实例横向化,从而减小业务的复杂度,而这点我们这里诟病非常深!
②是可以充分的利用资源。理论上成功之后,好处是非常之多:主机资源上的成本1年最起码能省下200W左右,业务部署结构不再那么复杂,运维、发布成本不再那么复杂、繁琐、可控性更高。
技术
技术方案理应也是从业务部署角度出发,现阶段是成熟的开源方便并“没有”,如何平稳的将现有的模式过渡到docker平台之上便十分困难。
现有的比较成熟、适合线上生产环境的个人认为是mesos。也可能是个人了解的有限:目前还没了解哪些公司在成熟有效的使用k8s、swarm等一些别的平台方案。
我们这里采用mesos最大的一个出发点是docker采用host模式,避免了网络部分的技术投入。毕竟做网桥之类的方案,性能很快的出现各种瓶颈,毕竟很多方案都在试验阶段,之前阿里等也做过一些类似的分享,大家可以找来看一看。
技术方案综合对比的文章dockone社区很多,这里就不做具体的介绍了。
除下方案,其他的方案就需要慎重考虑了,比较大的几点是运维方案,监控方案:这里涉及到扩容、异常响应等等。
人员
由于mesos-docker平台涉及的技术栈很广,人员到底要扩编到多少人,每个人的职责分工是什么?容易遇到的问题就是:
- 不清楚每个组件需要投入多少人
- 人员离职
- 一些人搞完一些组件,然后就无事了。
- other
同时由于mesos这一套组件,编写的语言有多种,这里又要结合技术方案来选型,是否要针对特别的一些组件做二次开发等等,都需要考虑进去。而且一般上对这类人员的技能等要求也比较高, 招人难度 和成本也可想而知。
时间
这点应该是上边几个点都要考虑的,然后对比出成本。比如按照时间规划,这样来做是否达到了最初省钱的想法,这里是要有一个 对比数据图 。毕竟我们的目的是通过技术来减小成本。
时间这一点需要附加的是要做好充分的规划,由于业务等外部因素很可能会对你本身的人员计划造成”动荡”。
第二章:规范
从事运维工作几年,见过很多这种情况,不管是什么工具、软件,看个demo就拿出来用了,甚至还会做技术推广。然后最后这个东西出现一些功能、性能的问题的时候,把包袱丢给了运维or其他。
所以在对技术方案做完大致路线后,第二件事就必须来做出相应的规范:
- 软件版本
- 升级、优化方案
- 异常处理职责
1、软件版本
例如mesos这一套,涉及到的组件有mesos/marathon/zookeeper/consul/etcd/registrator/nginx/docker/logstash/docker-registry等等,这里这里区分类别来讨论。
开源未做二次开发类:
比如mesos/zk/marathon/consul/nginx等,这些社区都会做比较规范的版本升级、迭代等,这类一般上功能都较为固定,”很少”需要做二次开发;
开源需要做二次开发类:
比如logstash等(里面有一些我们特殊的组件),这里基本上每个公司都有自己的版本控制方案;
以上2种为比较广的一些方案,我这里更希望提到一些docker相关的。
因为这里的坑是最多的:
①. docker版本:
docker版本升级还是比较快的,但是到底要采用哪一种应该是要规范好的,这里应该比较容易,但是未固定版本容易造成蝴蝶效应;
②、docker安装:
版本确认好,就是安装了。我们的做法是对docker storage、registry等配置做了规范,然后将安装封rpm,统一由运维在主机初始化时装好;对于storage、网络初始化的干货文章很多,我这里就不细说,我们存储用的是”Device Mapper”。--如果不这样做,如果公司开发的小组很多,造成的结果将会”有一千个哈姆雷特”。运维成本可想而知。
③、docker镜像:
除了docker版本需要控制,镜像更需要控制。很多人习惯了docker pull ,但是结果是一千个人出现了一万种哈姆雷特,镜像中包含的问题也是多之又多。另外镜像中的软件版本更是情况复杂,easy start是简单了,后面的维护、监控就别提了,压根是没办法做的。
我们这里的做法是开发镜像统一为centos7,针对开发语言java,我们做了修改的jre与jdk环境,以及对镜像里面java内存的限制,以及一些常用工具的镜像。我们会有一套需求提交、交付的流程,这样就避免了开发到处的pull,什么问题都会出现的情况,出现的问题可以统一修复。
PS:很多人都会提出来有很多精简的镜像为什么不用?虽然容量小到几M,毕竟精简过,对镜像系统层的出来难度很大,如果在镜像上叠加,那么基础镜像一次小的切换将动辄”全身”做更换。然后我们在主机初始化阶段,会将基础镜像pull一次,这样的效果和精简镜像效果其实一样,每次都拉业务数据即可。
2、升级、优化方案
升级的前提是安装要规范,然后是出于什么目的要升级(千万不能盲目跟着开源版本走),然后PAAS组件升级走OA,其实很多都可以动态升级,这一点比较简单;
优化方案这里就比较杂了,难度也比较大。需要配合压力测试、监控来分析性能。里面涉及了很多组件的压测方案,这里就不一一列举了,这里与交付有着很大的关系。
PS:如果这里采用了一些yum源来安装,建议将初始化的流程改掉,切记不要直接从官方等源上直接安装,这些地方版本更新后会造成你本地版本不一。所以建议没有yum源的保存rpm包localinstall。
3、异常处理
监控:监控这里目的是发现“何时变慢”;
完善:这里的概念有点模糊,需要看场景来制定不同的方法策略;
PS:这里的方案会根据业务来制定,有点模糊
第三章:交付
交付实际上就是上线的拍门砖,但是目前的情况是从PAAS到SAAS都没有明确的交付指标,也是我们目前遇到的瓶颈:测试过程不理想、风险性无法评估、需要测试的组件太多,没有完整的测试方案等等,所以方案基本上都在拍脑袋,耗时耗力。
PS:交付其实 1. 看产品重要程度 ;2. 看业务复杂程度 ;3. 看产品上线时间诉求 ;4. other 这些都决定着交付指标。
第四章:技术推广
如果说上边的都会在做方案的时候都能想到,但是技术推广很少有人想到。特别是开发部门众多的公司。怎么样合理的将技术、规范等等推广到各部门是极具挑战性的。实际操作中很容易遇到” 写平台的看不起写业务代码的 ”、“ 我们很忙,暂时不需要这些 ”这种情况,造成沟通和技术推广的效果做的十分不好,费时费力。好处是现在的各种技术软文很多,不好的是hello world遍地都是,而且各有不同。如果先是出现了"哈姆雷特",再去做规范,是根本来不及的。所以一个类似技术、平台的推广、规范的部门十分必要,当然这里面的一些能预见性的情况需要提前上层制定好。 So: 技术推广没做好反而是管理者的锅。
总结
要做好docker平台,不单单是技术达到相应的指标,就像做汽车,发动机做好了,其他零部件也必须要跟上,不然车永远是没办法安心上路的。
但是由于时间、人力、成本等的把控,又需要快速的上线,就要权衡技术方案和运维方便的成本,将能预见的一些事情提前规划好,才能安稳的渡过上线高问题爆发期,让平台平稳的过渡到稳定、健康的状态。
毕竟, 技术永远都在为业务服务 。

问答过滤过一些,提问的同学多多谅解
Q:您好,请问一下你们的监控采用的是什么方案?发现“变慢”后的动作是自动的还是需要人工介入的呢?
A:1、我们PAAS上的SaaS业务的框架,由平台部统一提供,框架本身集成了健康检查(存活状态,响应时间);2、运维开发小组会针对于这些有一套监控;3、另外针对于变慢,我们有zabbix、日志收集、trace系统统一来做数据展示、分析、比对报警
Q:请问,你们环境的存储用的是本机存储还是分布式存储
A:由于我们的业务直接走的RDS,存在本地的只有日志,我们的日志是挂载本地,规范了存放的格式,统一收走来做日志分析、trace问题排查系统等
Q:请问 docker 你们是如何做鉴权的?即控制哪些人可以使用 docker registry 哪些又可执行 push 等操作?怎么实现的?谢谢!
A:1、首先鉴权分为业务层和PAAS层,业务层我们配套了框架及API GATEWAY/认证系统等来做业务上的鉴权;2、docker层的我们这里做的比较简单:我们的registry只做了简单的鉴权,由于我们只为内网服务,所以otheruser都具有pull权限,我们的push操作只有单独的几台机器、操作人员可以通过Jenkins操作(这里我们做了封装开发)。
Q:可以讲讲在centos 7跑JAVA的时候,对jre 和jdk 做了哪些修改嘛?跑JAVA应用按理说jre 就够用了么
A:理论上jre就够了,但是不排除一些其他需要javac等的嘛 O(∩_∩)O~;另外修改的最重要的算是内存细分的限制了(看业务要求,我们对单个容器使用的内存严格限制),以及一些第三方的APM性能监控插件
Q:对于Java应用,如何设置datasource?我的意思的测试环境和生产,如果用同一个image
A:针对于不同的环境,我们在用封装过的Jenkins来打相应的镜像,也就是不同环境的镜像在build的时候的操作,其实不一样。针对于环境信息的配置放在etcd中。
Q:请问整个项目中的大概成本比例呢?如何定义各种成本?
A:这点比较难说,看公司的态度吧,比如百度和腾讯对于新技术的投入比例就远远不同。
Q:请问,使用host模式,你们目前怎么实现对端口的分配控制?
A:端口是由marathon随机分配的,不过可以针对端口段来做控制。一个机器可以开几千个端口,但是容器就开不了那么多啦。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

