「云智慧微课堂」移动创业公司的IT性能优化实例讲解
本期主讲:
汤金城,多年从事移动互联网相关运维工作,带领团队维护数百台服务器,拥有丰富的故障排查和性能优化实战经验,擅长业务拆分,高可用架构设计。
 大家好,我叫汤金城,今天和大家分享一下我在公司业务方面故障排查遇到的一些坑,以及进行性能调优的解决方法。记得刚来公司接手业务的时候,IT架构乱的一塌糊涂,前任留下来很多坑:服务器资源紧张,初期架构没考虑扩展性等等,不过对于初创企业来说这些问题都是正常的。
大家好,我叫汤金城,今天和大家分享一下我在公司业务方面故障排查遇到的一些坑,以及进行性能调优的解决方法。记得刚来公司接手业务的时候,IT架构乱的一塌糊涂,前任留下来很多坑:服务器资源紧张,初期架构没考虑扩展性等等,不过对于初创企业来说这些问题都是正常的。
故障的及时发现与实时分析
首先来讲下公司初期的一个需求,因为公司对业务很重视,所以领导需要第一时间了解故障原因是什么以及怎样做才能预防故障的再次发生。前期我考虑的就是监控日志,通过实时分析日志发现问题,开始我们使用的是一款python写的开源工具ganglia-logtailer,相当于对log进行tail实时获取并截取想要的信息进行监控,但是一段时间后发现这种工具的效率不高,并且数据并不是很准确。
然后就用了ELK,采用Logstash进行数据采集,存入redis,再由logstash从redis获取数据,中间进行一个过滤以及分析,存入到elasticsearch,通过kibana进行数据展示,同时logstash还可以对获取的数据进行监控以及邮件报警。
通过上面这种方式,确实能对后端服务器、存储等设备的故障和系统信息进行统计,但很多业务故障并不单纯是内部IT系统问题造成的,我们经常发现前端出现掉流量,掉访问的现象,而后端运行完全正常,通过这种内部监控是找不出原因的,这时候就需要考虑一些外部原因了。
下面给大家看一些故障排查案例:
实例1:服务器计算时长
有一段时间,每到晚上业务最高峰网站访问都会变慢,从内网并没看出什么明显访问异常,那时候刚上了监控宝,于是就部署上了监控外部分析,白天都很正常,一到晚上业务高峰期报警就增多了。监控宝的分析做的还不错,是基于curl来做的监控,curl本身就可以打印出相关连接时间 ,监控宝的响应时间报告包括一下参数:
DNS域名解析时间:访问网站的第一步就是DNS解析,如果这个时间消耗长,就得看看是不是DNS解析商那块出了问题;
建立连接:TCP三次握手建立连接的时间,如果5秒内无法建立连接,就会报无法连接服务器;
服务器计算:监控服务器的处理能力;
内容下载:网页内容下载到本地的时长;
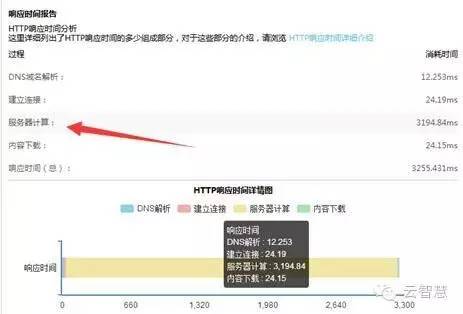 通过以上报警可以看出访问消耗在服务器计算能力上,那么很明显还是服务端的问题,于是又对服务器进行了一次检查,这次着重检查了服务器配置,结果发现被入口的nginx给坑了,nginx有个worker_connections参数,早期服务器没什么访问量的时候设置的比较低,只设置了8000,难怪每到晚上estab连接数最高就到32000左右,从未看到飙到32000以上,于是将worker_connections调到对应的数,这个问题就解决了,后面访问量自然就涨上去了,相比以前访问峰值PV涨了足足45%。
通过以上报警可以看出访问消耗在服务器计算能力上,那么很明显还是服务端的问题,于是又对服务器进行了一次检查,这次着重检查了服务器配置,结果发现被入口的nginx给坑了,nginx有个worker_connections参数,早期服务器没什么访问量的时候设置的比较低,只设置了8000,难怪每到晚上estab连接数最高就到32000左右,从未看到飙到32000以上,于是将worker_connections调到对应的数,这个问题就解决了,后面访问量自然就涨上去了,相比以前访问峰值PV涨了足足45%。
实例2:移动用户无法访问网站
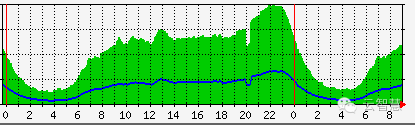 上面是4月21日交换机的入口出口图,在20点整的时候出现一个流量的掉坑,根据这张图可以很明显的看到流量在进来的时候就已经减少了,这个时候内部监控系统却没发现有其他异常,下面再看下nginx的入口出口图:
上面是4月21日交换机的入口出口图,在20点整的时候出现一个流量的掉坑,根据这张图可以很明显的看到流量在进来的时候就已经减少了,这个时候内部监控系统却没发现有其他异常,下面再看下nginx的入口出口图:
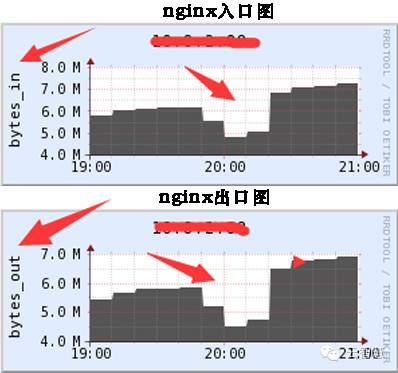 可以很明显的看到流量进来就减少了,造成出去的流量减少,那么问题肯定出在外部。
可以很明显的看到流量进来就减少了,造成出去的流量减少,那么问题肯定出在外部。
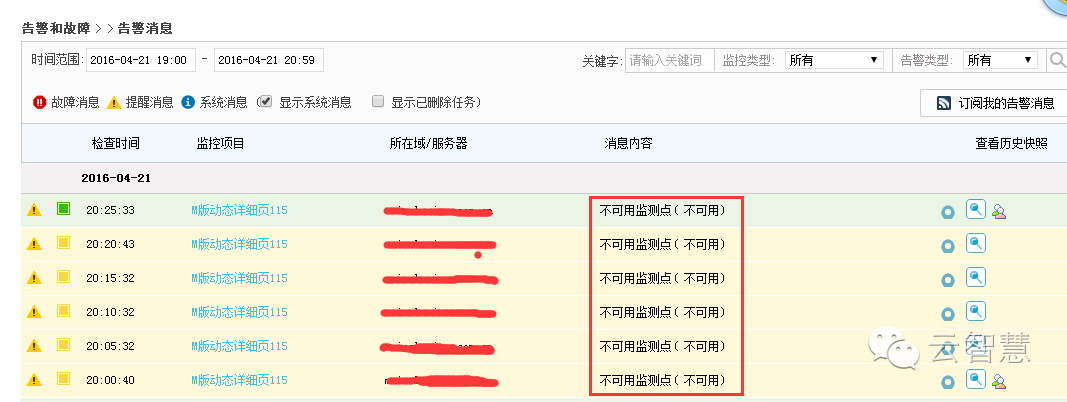
这是监控宝的告警信息,可以很明显的看到4月21日20点之后,持续25分钟的移动用户节点无法访问。
 这时候就不是我们的问题,而是机房的事了,马上打电话给机房反馈情况,机房帮我们做了路由优化之后故障得到解决,整个过程持续了将近20分钟。
这时候就不是我们的问题,而是机房的事了,马上打电话给机房反馈情况,机房帮我们做了路由优化之后故障得到解决,整个过程持续了将近20分钟。
性能的优化
在我看来,性能优化和监控是分不开的,现在关于优化的配置非常多,适合自己的才是最好的。我通常会在修改配置后,先进行压力测试,然后观察内部监控、外部监控的性能表现进行调整。这里给大家推荐一些常用的系统参数:
net.ipv4.tcp_fin_timeout = 30
net.core.somaxconn = 8196
net.ipv4.tcp_max_syn_backlog = 8196
net.ipv4.ip_local_port_range = 1024 65000
再强调一次,因为每个公司的业务场景都不一样,只有了解了自己业务的真实需求才能针对性的进行性能调优,千万不要盲目对照别人的参数去调整配置,以上参数对我们的业务来说是最优的,但可能在某些业务场景下反而会影响性能。所以建议大家先留一份原有参数的备份,如果调试有问题可以回滚。
下面给大家分享几篇干货,都是关于time_wait tcp listen backlog这些受争议的参数,大家可以参考,然后自己做调整,记得先对照参数备份原有参数,另外有些参数sysctl -p后生效时间可能要2到5分钟。
http://mp.weixin.qq.com/s?__biz=MzA3MzYwNjQ3NA==&mid=403319808&idx=1&sn=ddae082f5b844d040b9ab23c9c0eb778&scene=23&srcid=0311SD5dPUGnPq7sTqzC2vHn#rd
http://mp.weixin.qq.com/s?__biz=MzA3MzYwNjQ3NA==&mid=403232978&idx=1&sn=4ed396ac1999add1c866419bd62b0e75&scene=23&srcid=0307e64zzFVkDViC4iDlvIbD#rd
http://dngood.blog.51cto.com/446195/988968
http://blog.hellosa.org/2011/04/21/tcp-kernel-nat.html
http://www.udpwork.com/item/6909.html
http://blog.csdn.net/largetalk/article/details/16863689
https://www.douban.com/note/178129553/
http://mp.weixin.qq.com/s?__biz=MjM5NzUwNDA5MA==&mid=201005717&idx=1&sn=74036633114ee6212e57ee4576dbfcbc&3rd=MzA3MDU4NTYzMw==&scene=6#rd
http://www.cnxct.com/something-about-phpfpm-s-backlog/
还有更多的干货这里就不方便贴出了,有需要的可以找我要。以上就是今天的分享,如有不足之处请大家多多包涵。
问:你现在外部监控是怎么做的?
答:目前外部监控我们通过监控宝监控了静态页面和动态页面,静态页面监控我的缓存服务器,动态页面监控的后端服务器。我们主要是URL监控,如果你们API使用比较多,也可以用监控宝进行API监控。此外,监控宝也提供内部系统监控的,采用agent方式对系统所关注的应用组件性能做监控,并不比zabbix差,而且还支持电话报警。
问:请问运维和领导沟通有什么技巧吗?
答:直接晒数据最有力,领导喜欢看数据报告,要把各个方面的性能图和数据给他看,然后给他挑刺,用数据说话抵得上千言万语。不过这需要做到全面的监控,才可能获取有说服力的完整数据,特别是随着业务的增长,以前遗留下的一些问题在量小的时候并不怎么明显,访问压力大了才会爆发出来,这时候如果有前后的对比分析,就可以让领导为业务增长买单。
问:那数据用什么样的方式呈现比较好?
答:当然是图表,监控宝提供一些基础数据的图表,如果希望根据自己的业务定制图表,可以使用ganglia集群监控,搭建方便,模块多,图形非常适合分析排查故障。
问:那能不能稍微总结下,对一个初创公司来说,有哪些工作是从一开始就必须要做的?
答:压测和监控是构建弹性、高可用IT架构的基础,云智慧的监控宝、透视宝和压测宝正好从不同的角度解决这个性能问题,而且SaaS模式也比较适合初创企业,大家可以试试。
加入监控与性能优化分享群
请关注以下二维码

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

