网易视频云:面向时间序列的实时分析型数据库DRUID
DRUID是一个面向时间序列数据的实时分析型数据库。
系统设计目标:
1.快速的聚集和drill down能力。 任意维度组合查询希望在亚秒级返回。
2.多租户和高可用。
3.亚秒级data ingestion。
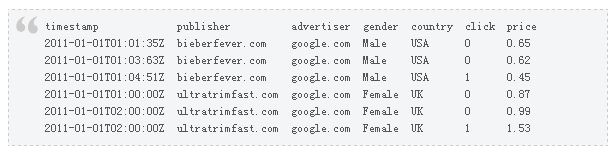
DRUID的数据如上图所示, 分为时间列(Timestmap),维度列(publisher advertiser gender country)和度量列(click price)。 度量列通常是数值类型, 按照某一时间间隔聚合之后存储, 而不存储原始数据, 好处是节省了存储空间, 缺点是查询能力受限。
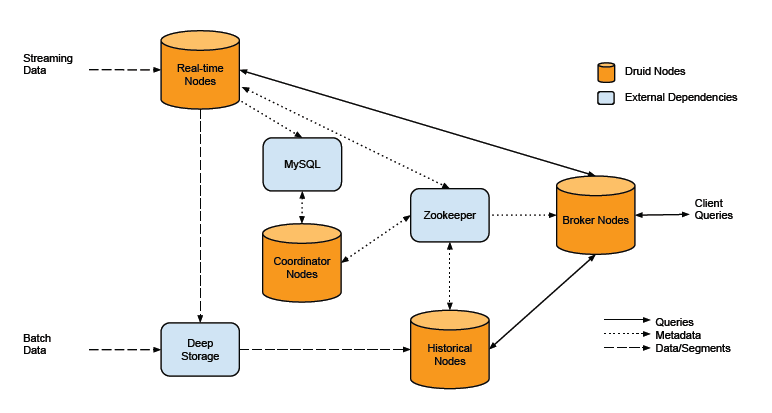
Real-time Nodes。 Real-Time Node从kafka消费数据, 数据实时存放到Real-Time Node内存缓存, 内存数据量超过阈值时(或者定期)时,写内存数据到外存形成外存索引。 内存数据加上多个外存索引, Real-Time Nodes以这种方式支持亚秒级数据可见性 。 Real-Time Node宕机会造成内存数据丢失, druid依赖kafka的数据回溯能力恢复数据: Real-time Node会记录外存索引对应的kafka位置, 启动之后从该位置继续消费数据, 重新生成内存数据。
Real-time node的容量和查询能力是有限的, 所以它会定期合并多个外存索引生成segment, segment对应一段时间范围内的进入druid的数据。 segment生成之后马上被上传到deep storage, 很快就会有Historical Nodes下载该segment,并替代Real-time Node提供查询服务。
Historcial Nodes。 负责从DeepStorage下载segment, 提供数据查询服务, Historical Nodes从Zookeeper获取加载、删除segment等基本指令, 它们之间相互不通讯。 Historical Nodes可分为多个tier, 比如热数据放在一个tier, 冷数据放到另外一个tier,以达到冷热数据分开处理的目的。
Broker Nodes。 查询代理节点。 接收用户查询, 根据Zookeeper上的元数据信息定位查询涉及的segment, 汇总各实时节点和历史节点查询结果, 返回给用户, 并负责查询的缓存。
Deep Storage。 存储segment, 但是不负责查询, Historical nodes从deep storage拉取segment。
Coordinator Nodes, 是全局协调者, 负责把segment分配给HIstorical Node以保证load balance, 负责指定segment副本个数, segment删除策略等。

druid的查询以HTTP/JSON形式提供, 查询能力较为有限, 首先它不提供SQL, 其次也不提供Join。
上图是一个查询的例子, 对应到SQL是: select count(*) from wikipedia where date >= 2013-01-01 and date < 2013-01-08 group by date。 值得一提的是, druid支持数据仓库中常见的位图索引。如果page维度上建有位图索引, 可以大大减少查询扫描的行数。
druid的设计目标之一是多租户,多租户的解决思路是给查询分类, 优先执行耗时较短的探索性查询。 看起来druid在多租户方面没有做太多工作, 没有起码的资源隔离。
总结
Druid是一个面向时间序列数据的开源分布式实时分析型数据库,基于列存和位图索引提供良好的查询性能, 不过列存和位图索引都是常见技术, 查询的性能取决于实现好差。 应用场景较为单一,且无法和hadoop生态有效结合是druid的致命弱点。
参考文献
DRUID: a realtime Analytical Data Store
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

