机器学习笔记2--单变量线性回归
继续是 机器学习课程 的笔记,这节介绍的是单变量线性回归算法,线性回归算法也是一个比较基础的算法。
模型表达
首先是以房屋交易问题为例,假设我们回归问题的训练集如下表所示:
|Size in $feet^2$ (x) | Price(/$) in 1000’s (y)|
| :—–: | :—-: |
|2104 |462 |
|1416 |232 |
|1534 |315 |
|852 |178 |
|… |… |
此外我们将使用以下变量来描述这个回归问题:
- m 代表训练集中实例的数量
- x 代表特征/输入变量
- y 代表目标变量/输出变量
- (x,y) 代表训练集中的实例
- ($x^i,y^i$) 代表第i个观察实例
- h 代表学习算法的解决方案或函数,也成为假设(hypothesis)
下面是一个典型的机器学习过程:
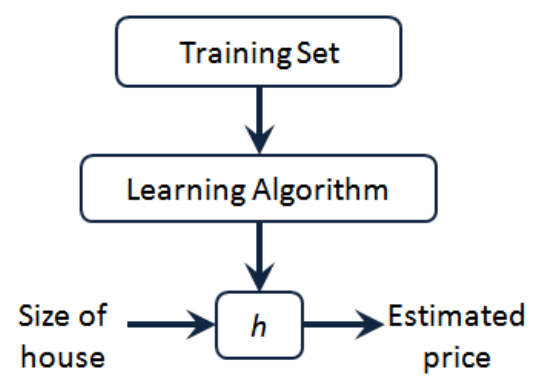
所以对于房价预测问题,我们是在训练集上执行学习算法,学习到一个假设 h ,然后将要预测的房屋的尺寸作为输入变量输入给 h ,而输出结果就是该房屋的交易价格。
这里的 h 也就是一个模型,是一个从输入变量 x 都输出变量 y 的函数映射。它的一种可能的表达式为:
$$
h_/theta = /theta_0 + /theta_1 x
$$
这个表达式只含有一个特征/输入变量,因此这样的问题叫作 单变量线性回归问题 .
代价函数
当我们得到一个模型后,就必须选择合适的参数$/theta_0$和$/theta_1$.在房价问题中,对应的就是直线的斜率和在y轴上的截距。
我们选择的参数决定了我们得到的直线相对于我们的训练集的准确程度,模型所预测的值与训练集中实际值之间的差距就是 建模误差 (modeling error),如下图所示:
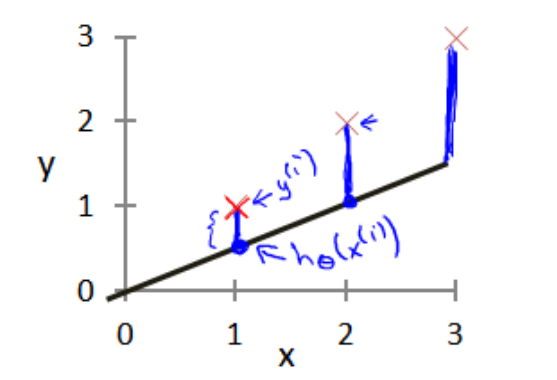
上图中,$h_/theta (x^i)$是对第i个输入变量的预测输出值,而$y^i$则是对应的真实值。
因此我们的目标是选择出可以使得建模误差的平方和能够最小的模型参数,也就是min($h_/theta (x^i)$ -$y^i$)。
这里就使用一个代价函数$J(/theta_0,/theta 1) = {1/over {2m}} /sum {i=1}^m (h_/theta(x^i) - y^i)^2$
这里的代价函数也叫做平方误差代价函数,这是最常用的解决回归问题的方法。当然还有其他代价函数,这将在后面提及。
梯度下降
梯度下降是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数$J(/theta_0,/theta_1)$的最小值。
思想过程
梯度下降算法的思想如下:
首先,我们有一个代价函数,假设是$J(/theta_0,/theta 1)$,我们的目标是$min {/theta_0,/theta_1}J(/theta_0,/theta_1)$。
接下来的做法是:
- 首先是随机选择一个参数的组合$(/theta_0,/theta_1)$,视频中说一般是设$/theta_0 = 0,/theta_1 = 0$;
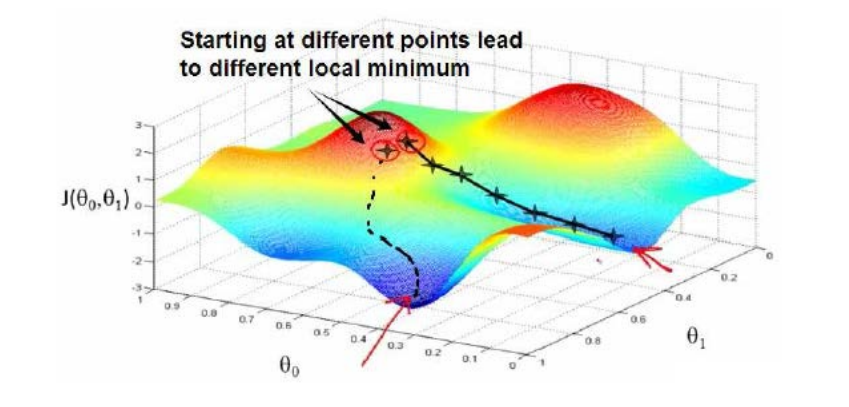
- 然后是不断改变$(/theta_0,/theta_1)$,并计算代价函数,直到一个 局部最小值 。之所以是 局部最小值 ,是因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是 全局最小值 ,选择不同的初始参数组合,可能会找到不同的局部最小值。
下图是视频中给出的梯度下降法是如何工作的:
算法公式
下面给出梯度下降算法的公式:
repeat until convergence{
$$
/theta_j := /theta_j - /alpha /frac{/partial}{/partial /theta_j} J(/theta_0,/theta_1)/quad (for/quad j=0 /quad and/quad j=1)
$$
}
也就是在梯度下降中,不断重复上述公式直到收敛,也就是找到$/color{red}{局部最小值}$。其中符号 := 是赋值符号的意思。
公式中的$/alpha$称为 学习率(learning rate) ,它决定了我们沿着能让代价函数下降程度最大的方向向下迈进的步子有多大。
在梯度下降中,还涉及都一个参数更新的问题,即更新$(/theta_0,/theta_1)$,一般我们的做法是 同步更新 :
$$
temp_0 := /theta_0 - /alpha /frac{/partial}{/partial /theta_0} J(/theta_0,/theta_1) /
temp_1 := /theta_1 - /alpha /frac{/partial}{/partial /theta_1} J(/theta_0,/theta_1) /
/theta_0 := temp_0 /
/theta_1 := temp_1
$$
算法详解
在上述公式中$/frac{/partial}{/partial /theta_j} J(/theta_0,/theta_1)$是一个偏导数,其含义就是函数$J(/theta_0,/theta_1)$的斜率,假设我们要求的代价函数$J(/theta_0,/theta_1)$如下图所示,初始点是图中的红色的点,那么由于在该点上的切线斜率是一个正数,而学习率也是正数,所以更新后的$/theta_1$会减小,也就是会向左移动,并靠近局部最小值。
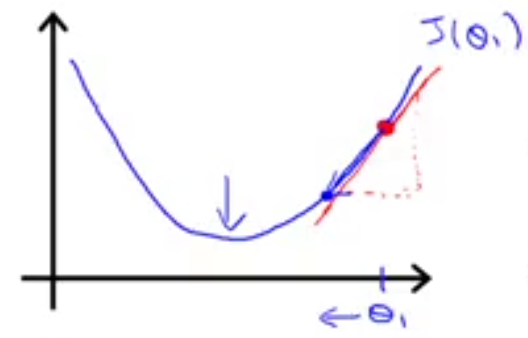
当然,如果起始点是在上述曲线左侧,其切线斜率则是负值,那么会导致/theta_1$逐渐变大,同样也是靠近局部最小值。
公式中的学习率$/alpha$是决定找到局部最小值的快慢,同时也决定了能否找到局部最小值,因为如果取值过大,就可能错过局部最小值,并且可能会导致无法收;但是取值过小,学习的速度就会比较慢。
视频中也提到一个问题,如果初始点就是一个局部最小点,那么由于局部最小值的切线斜率是0,那么会导致参数不变,因为其实已经在局部最小值了。此外,即使学习率$/alpha$是一个固定值,梯度下降法也是可以收敛到一个局部最小值,原因是在接近局部最小值时,$/frac{/partial}{/partial /theta_j} J(/theta_0,/theta_1)$会自动变得更小,然后就可以慢慢接近局部最小值,而不需要改变学习率。
应用于线性回归
根据前面内容,我们有梯度下降算法公式:
repeat until convergence{
$$
/theta_j := /theta_j - /alpha /frac{/partial}{/partial /theta_j} J(/theta_0,/theta_1)/quad (for/quad j=0 /quad and/quad j=1)
$$
}
以及线性回归模型
$$
h_/theta(x) = /theta_0 + /theta_1 x /
J(/theta_0,/theta 1) = /frac{1}{2m}/sum {i=1}^m (h_/theta(x^i) - y^i)^2
$$
这里的关键就是求解代价函数的导数,即:
$/frac{/partial}{/partial /theta_j} J(/theta_0,/theta_1) = /frac{/partial}{/partial /theta j} - /frac{1}{2m}/sum {i=1}^m (h_/theta(x^i) - y^i)^2$
进一步,可以得到:
$$
j=0: /frac{/partial}{/partial /theta_0} J(/theta_0,/theta 1) = /frac{1}{m}/sum {i=1}^m (h_/theta(x^i) - y^i)^2/
j=1: /frac{/partial}{/partial /theta_1} J(/theta_0,/theta 1) = /frac{1}{m}/sum {i=1}^m ((h_/theta(x^i) - y^i)^2 /cdot x^i)
$$
由此,我们的算法可以改写成:
repeat until convergence{
$$
/theta_0 := /theta 0 - /alpha /frac{1}{m}/sum {i=1}^m (h_/theta(x^i) - y^i)^2/ /
/theta_1 := /theta 1 - /alpha /frac{1}{m}/sum {i=1}^m ((h_/theta(x^i) - y^i)^2 /cdot x^i)
$$
}
最后,在我们给出的梯度下降算法公式实际上是一个叫 批量梯度下降(batch gradient descent) ,即它在每次梯度下降中都是使用整个训练集的数据,所以公式中是带有$/sum_{i=1}^m$,当然也存在其他梯度下降法,在每次梯度下降时考虑部分数据。
小结
这里就介绍完单变量的线性回归方法,对于这个线性回归算法,我的理解是,因为正如开头介绍的经典的机器学习过程,是使用一个学习算法在给定的数据集上学习得到一个模型,然后使用该模型对新的数据进行预测,得到一个预测的结果,所以对于线性回归也是要求解其模型,其实就是我们非常熟悉的直线方程$h_/theta = /theta_0 + /theta_1 x$,就是让我们计算得到的直线方程尽可能逼近实际的直线方程,而衡量的标准就是使用代价函数,而在线性回归中,非常常用的是平方和误差函数$J(/theta_0,/theta 1) = {1/over {2m}} /sum {i=1}^m (h_/theta(x^i) - y^i)^2$,那么这就把问题变成求解最小的代价函数,也就是求解一对参数$/theta_0,/theta_1$使得$minJ(/theta_0,/theta_1)$,而要得到这对参数,我们就是使用梯度下降方法。梯度下降法也是一个非常常用的方法,包括在神经网络中都会使用到。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

