网易视频云:Tachyon超光速文件系统
Tachyon文件系统诞生于著名的berkeley AMPLab(amplab.cs.berkeley.edu), 单词Tachyon意为超光速粒子, 彰显文件系统的卓越性能, 该项目近期获得硅谷风投A16Z 750万美元A轮投资。 系出名门, 名字霸气, 受到投资者青睐, Tachyon到底是怎么样一个文件系统?
“Tachyon is a memory-centric distributed storage system enabling reliable data sharing at memory-speed across cluster frameworks, such as Spark and MapReduce. ”
从Tachyon项目的介绍可以看到, tachyon解决Spark/MapReduce框架数据共享的性能问题。 大数据业务一般是一个任务流, 任务流由一组相互依赖的任务组成, 一个任务的输出往往是另外一组任务的输入, 任务间数据共享是一个强需求。 最常见的数据共享方式是HDFS, 这种方式性能低下, 主要问题有: (1) HDD或者是SSD带宽都比较有限, (2) HDFS三副本写入性能损失较大, (3) 文件可能被多次缓存, 浪费内存。 Tachyon的目标就是解决数据共享的性能问题, 解决方法也很极端 —— 内存单副本。 当然简单的内存单副本会导致数据丢失, Tachyon采用lineage数据恢复技术保证数据可靠性。 根据相关论文的测试数据, Tachyon的写性能是HDFS的110倍, 任务流执行时间降低到1/4。
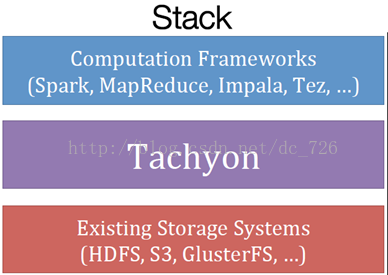
如上图所示, tachyon介于存储系统和计算框架之间, 缓存计算任务读写的文件, 目前Tachyon支持HDFS, S3和GlusterFS这几个后端文件系统。 引入Tachyon后, Spark/MapReduce任务程序不需要修改, 但是Spark、MapReduce框架自身要做一个200~300行代码的小Patch, 因为计算框架在产生输出之前, 必须先将数据lineage关系告知Tachyon, Tachyon记录lineage信息到磁盘, 用于实现数据的故障恢复。
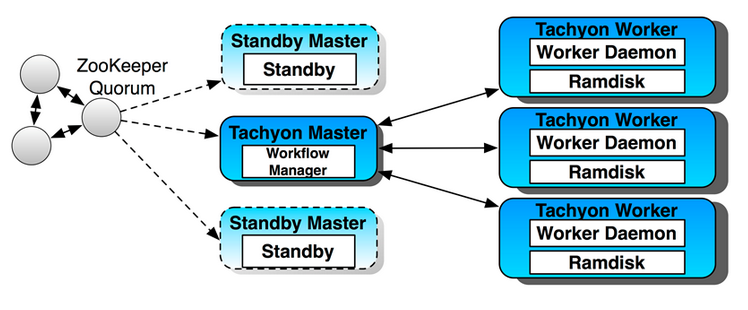
如上图所示, Tachyon文件系统的架构非常类似HDFS, 全局有一个Master管理元数据, Woker负责数据读写, 文件数据存储到在Ramdisk中。
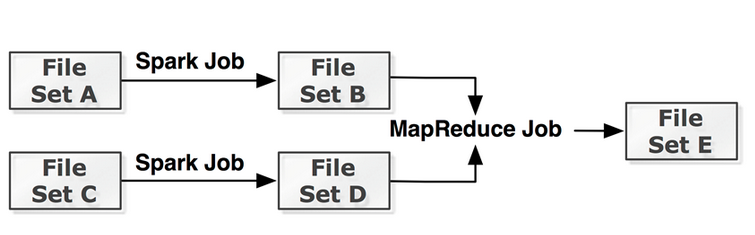
与Spark类似, Tachyon基于lineage的故障恢复保证数据可靠性。 数据恢复基本思路也很简单, 记录生成文件的任务以及输入数据, 文件丢失时重新调用任务再次恢复数据。 为了控制数据恢复时间, Tachyon在后台异步执行检查点操作, 即把某些内存文件写入到后端HDFS文件系统。 内存文件量比较大, 很难全部写入磁盘, 而且大量临时文件根本也无需写入磁盘, 所以挑选哪些内存文件写入磁盘需要精心设计, Tachyon的解决方法是Edge算法, 其核心思想是挑选DAG的叶子节点,以及访问最多的一批文件写入磁盘。
小结
Tachyon是一个分布式内存文件系统, 通过内存单副本技术提高Spark/MapReduce框架数据共享性能, 通过lineage恢复确保数据可靠性, 适用于有较多复杂任务流, 存储IO压力较大的大数据计算业务。
参考文献
• http://tachyon-project.org/
• Tachyon: Reliable, memory speed storage for cluster computing frameworks
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

