网易视频云专家分享:Apache kylin简介
“Apache Kylin is an open source Distributed Analytics Engine from eBay Inc. that provides SQL interface and multi-dimensional analysis (OLAP) on Hadoop supporting extremely large datasets”。
Apache kylin(麒麟)是ebay中国团队开源的基于hadoop的olap系统, 支持SQL接口, 能处理超大数据集。 当前流行的SQL-on-Hadoop方案需要扫描部分或者全部数据来完成查询, 查询延迟很大, 而kylin在SQL-on-Hadoop基础之上, 通过预计算cube方式, 以空间换时间大幅降低查询延时, 从而弥补了现有方案的不足之处。项目开始于2013年9月, 2014年底已经成为apache孵化器项目, 项目在ebay公司已经有大量应用, 发展前景看好。
kylin主要特性
• 适用于海量数据的超快OLAP引擎, 降低百亿数据规模下的查询延时。
• ANSI SQL查询接口,支持大部分ANSI SQL查询功能。
• 交互式查询能力。 查询延时控制在亚秒级, 为hadoop提供交互式查询能力。
• MOLAP。 用户事先定义cube模型, 并使用kylin从原始数据集离线构建cube。
• BI工具无缝集成, 目前能够与tableau集成(使用ODBC)。
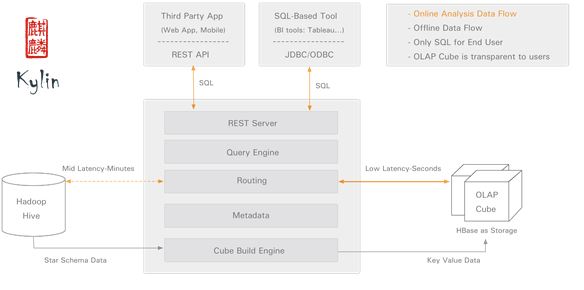
如下图所示, kylin构建于hadoop hive和hbase之上, 实现查询路由功能: 尽量通过hbase中预先计算的olap cube满足查询, 不能被hbase满足的查询则发送到hadoop hive。 hbase中的olap cube根据hive星型数据离线计算, 以空间换时间方式加速查询。 kylin查询加速对用户透明, 从用户角度来看, kylin的查询和hive没有太大区别。
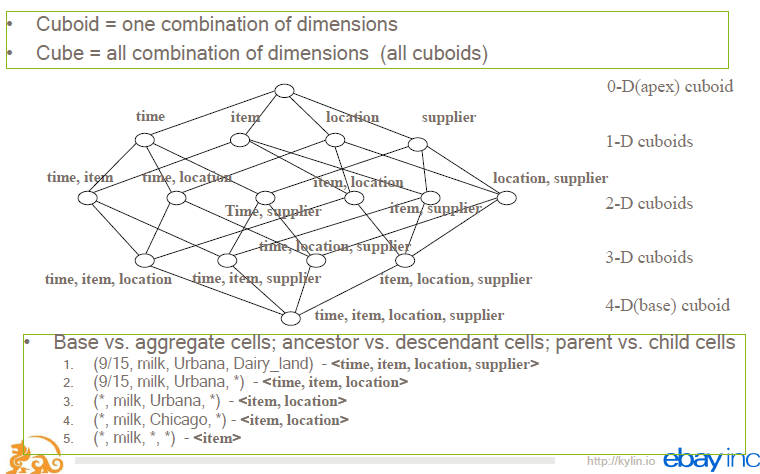
预先计算olap cube的目标是事先按照各个维度组合聚合度量, 将复杂的SQL查询转换为简单KV查询, 避免查询时扫描过多数据, 提升查询效率。 下图所示cube包含time, item, location, supplier四个维度, kylin生成的cube包含16个cubeoid, 每个cubeoid对应一个维度组合。 N维cube有2^N个cubeoid, 空间占用非常可观,当N超过一定量时,空间消耗无法接受。 kylin通过partial cube来降低维度组合数, 平衡存储空间和查询性能。 基本思路是将维度拆分为多个聚合组, 只在组内计算cube, 聚和组内查询效率较高, 跨组查询效率较差, 所以需根据业务场景定义聚合组。 此外, kylin也支持从cube中裁剪聚合效果较差的高cardinality属性, 降低存储开销。
cube计算非常耗时, 新数据进入系统时全量重构cube代价较高, 因此kylin设计了增量cube building技术加速离线cube计算效率。 其原理是保存基础cube,以及多个增量cube, 每个cube代表一段时间内的新数据, 新数据build成新cube, 尽量避免cube整体重建。 查询时访问多个cube进行数据聚合, cube个数越多查询性能越差, 所以系统根据一定策略merge小cube成为大cube降低查询代价。
总结
apache kylin是构建与hadoop hive, hbase之上的开源的olap系统, 且在kylin在eBay公司内部大量应用, 其中规模最大的用例有120多亿条记录, cube数据量超过14TB , 这种规模下90%的查询请求都能在5秒钟之内返回。 总体看起来kylin的前景比较好, 但是kylin项目创建的时间并不长, 相比Google Mesa, kylin在数据更新能力、 数据分区、元数据在线修改、 查询性能上仍然有不少优化空间。
参考
• Jiang Xu, Kylin: Hadoop OLAP Engine - Tech Deep Dive
• 韩卿(Luke Han), Apache Kylin Introduction
• kylin官网。 http://www.kylin.io/
• Kylin正式发布:面向大数据的终极OLAP引擎方案, http://www.csdn.net/article/2014-10-25/2822286
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

