完形填空的机器实现
完形填空一直是各大英语考试的常见题型,读一篇短文,填20个空。那么如果是机器来做完形填空,该如何来定义问题,提出模型呢?本周开始将会介绍一系列文本理解的模型。本文分享的题目是 Gated-Attention Readers for Text Comprehension ,最早于6月5日submit于arxiv上,作者是CMU的Graduate Research Assistant Bhuwan Dhingra 。
首先,介绍一下对完形填空问题的定义。问题可以表述为一个三元组(d,q,a),这里d是指原文document,q是指完形填空的问题query(这里需要注意一点的是,与我们英语考试中的完形填空不同,更像是只用一个单词来回答的阅读理解),a是问题的答案。这个答案是来自一个固定大小的词汇表A中的一个词。即:给定一个文档-问题对(d,q),从A中找到最合适的答案a。
本文精彩的部分有两个,一个是related work写的非常漂亮,另一个是提出了一种新的注意力模型GA(Gate-Attention) Reader,并且取得了领先的结果。
后续的文本理解系列的文章将会从related work中产生,包括以下几篇:
[1] Teaching machines to read and comprehend
[2] A multiplicative model for learning distributed text-based attribute representations
[3] Dynamic entity representations with max-pooling improves machine reading
[4] Text understanding with the attention sum reader network
[5] The goldilocks principle: Reading children’s books with explicit memory representations
[6] A Thorough Examination of the CNN/Daily Mail Reading Comprehension Task
下面来介绍本文的模型,结合下图来看:
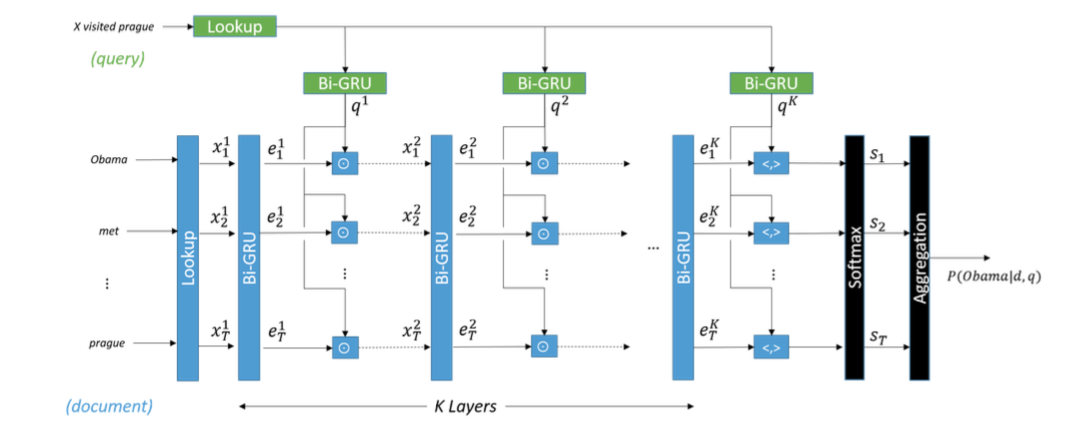
step 1 document和query通过一个Lookup层,使得每个词都表示成一个低维向量。
step 2 将document中的词向量通过一个双向GRU,将两个方向的state做拼接获得该词的新表示。同时也将query通过一个双向GRU,用两个方向上的last hidden state作为query的表示。
step 3 将document中每个词的新表示与query的新表示逐元素相乘得到下一个GRU层的输入。
step 4 重复step 2和3,直到通过设定的K层,在第K层时,document的每个词向量与query向量做内积,得到一个最终的向量。
step 5 将该向量输入到softmax层中,做概率归一化。
step 6 因为document中有重复出现的词,聚合之后得到最终的分类结果,即确定应该填哪个词。
模型的计算流程还是很好理解的,下面给出一些可视化的attention结果。

图中高亮的部分是针对问题时的最后一层注意力所关注的地方。
注意力模型是一个非常热门的研究领域,很多专家都看好其在今后各大nlp任务中的应用前景,不同版本、不同结构、不同层次的注意力模型丰富了模型,也提升了效果。注意力的本质就是说你关注的输出与你的输入中的哪个元素关系更加紧密,即输出的部分应该更加注意哪个输入细节,在做完形填空、阅读理解的时候,我们也会有这样的感受,就是题目的答案往往就在某一句话或某几句话当中,并不需要回答每个问题都从全文中找一遍答案,而是定位到关键句上。这里的定位就是注意力,剩下的问题就是研究如何更加准确地定义、建模注意力,是用普通的前馈神经网络,还是用GRU,还是用分层模型都需要针对具体问题的特点。
后续的几篇文章将会继续介绍文本理解,敬请关注。
工具推荐
RSarXiv 一个好用的arxiv cs paper推荐系统 网站地址 ios App下载:App Store 搜索rsarxiv即可获得
PaperWeekly,每周会分享N篇nlp领域好玩的paper,旨在用最少的话说明白paper的贡献。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

