构建新一代容器云计算Big Data Platform最佳实践
随着云时代的到来,大数据也吸引了越来越多多关注。而Spark做为大数据处理的佼佼者,越来越受到人们的关注。正是由于Spark技术的出现,使得在云计算上构建超大规模的大数据平台成为了可能。
Spark诞生于伯克利大学AMPLab,是现今大数据领域里最为活跃,最为热门,最为高效的大数据通用计算平台。Spark是基于MapReduce算法实现的一个分布式计算框架,Spark继承了Hadoop的MapReduce的所有优点,但是比Hadoop更为高效。
Spark成功使用Spark SQL/Spark Streaming/MLlib/GraphX近乎完美的解决了大数据中的Batch Processing、Streaming Processing、Ad-hoc Query三大核心问题。并且Spark的四大子框架和库之间可以无缝地共享数据和操作,这样的优势使得Spark在当今大数据计算领域中,处于无可匹敌的领先地位,也让Spark成为了大数据处理首选的计算平台。

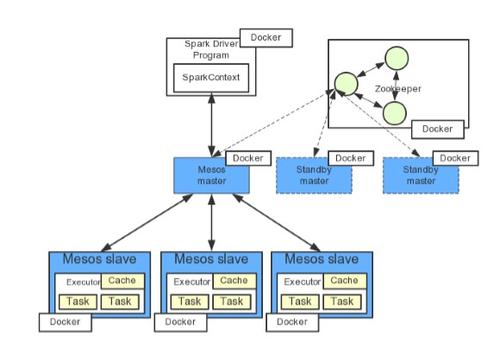
为了适应国内云计算IaaS基础架构的需要,我们对Spark提出了更多苛刻的要求。首先,我们希望能自动化部署Spark集群到IaaS上并自动扩展计算节点。其次,我希望能维护所有的计算集群资源能像使用一台主机上的体验一样。再次,对于Spark的部署,希望能脱离主机的环境限制,按照业务需要自动扩展Spark集群环境,做到真正的动态,可扩展,有弹性的大数据计算平台。事实上对于这些问题,业界已经提供了非常优秀的开源项目Apache Mesos来支持资源调度,让我们得以开展实施我们的计划。但即使是这样,对于资源的隔离仍然不是很理想。因为对于高性能的机器,Spark不一定能完全占用完所有资源。为了能充分利用Spark的计算资源,我们最好是把大容量的机器划分为类似2G CPU/4G RAM大小的基础样机,使用Docker容器把Mesos/Spark包装起来,就可以很好的解决这个隔离需求。所以经过我们的实战需要,我们在最后终于有了非常确定的架构蓝图,也就是使用Mesos构建出一整套云计算分布式平台,在此基础之上我们再启用Spark引擎,让弹性分布式数据集(resilient distributed dataset,RDD)可以自由的穿梭在每个Mesos Slave节点。那么这里就要介绍一下Mesos这个优秀的框架了。
Mesos诞生于UC Berkeley的一个研究项目,现已成为Apache中顶级项目,当前业界知名企业已经开始使用Mesos管理集群资源,比如Twitter、AirBnb、爱奇艺等。
Mesos采用master/slave结构,并且Mesos采用Zookeeper来解决分布式中最常见的单点故障问题,通常我们将master设置为三份,通过zookeeper来选举真正的master,做到高可靠性。master仅仅保存了mesos应用程序(通常称之为framework,包括四大类型,分别为Long Running Services,Big Data Processing,Batch Scheduling和Data Storage)和slave的一些状态,这些状态很容易通过framework和slave重新注册而进行重构。
Mesos中主要包含四个服务(实际上是一个socket server),分别是Mesos Master, Mesos Slave, SchedulerProcess和ExecutorProcess。各个服务之间通过Protocal Buffer消息进行通信 ,每个服务内部注册了若干种Protocal Buffer消息处理器,一旦接收到某种消息,则会调用相应的消息处理器进行处理。
实战
我们将以三个节点为例子,通过Docker来安装部署Mesos集群,并且调用Docker来部署Mesos的Framework(Marathon,Chronos,Spark)
注:所有的Dokcer image都可以通过registry.dataman.io下载。
| 角色/IP | 192.168.100.30 | 192.168.100.31 | 192.168.100.32 |
| zookeeper | √ | √ | √ |
| mesos-master | √ | √ | √ |
| meoss-slave | √ | √ | √ |
| marathon | √ | √ | √ |
| spark-driver | √ |
安装 Mesos
想要在物理机上快速部署Mesos集群,我们必须先在物理机上安装Docker,详细的安装过程我们可以通过查看Docker官网文档来进行,这里不做详细叙述。
- 启动zookeeper
docker run --net=host registry.dataman.io/zookeeper /bin/bash /usr/local/share/zookeeper/start.sh -h=192.168.100.25:1,192.168.100.27:2,192.168.100.28:3
-h为预先分配好的zookeeper的IP+ID,格式为ip1:id1[,ip2:id2[,ip3:id3]]
更多zookeeper启动参数可以参照 https://zookeeper.apache.org/doc/r3.3.3/zookeeperAdmin.html#sc_configuration
- 启动mesos-master
docker run --net=host registry.dataman.io/mesos-master --zk=zk://192.168.100.30:2181,192.168.100.31:2181,192.168.100.32:2181/dataman --cluster=DataManCloud --quorum=2 --work_dir=/tmp --hostname=`ifconfig eth0 | awk '/inet addr/{print substr($2,6)}'` --quorum=VALUE 这是复制节点的法定数量。这个数量必须大于master/2的数量。
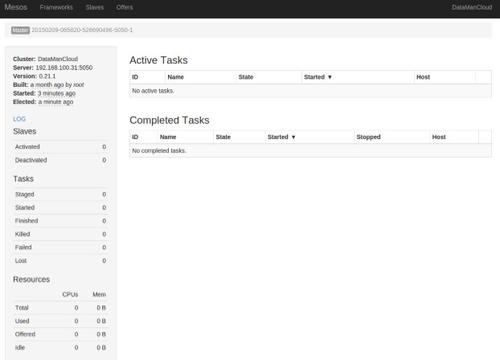
- 启动mesos-slave
docker run --net=host registry.dataman.io/mesos-slave --master=zk://192.168.100.30:2181,192.168.100.31:2181,192.168.100.32:2181/dataman --hostname=`ifconfig eth0 | awk '/inet addr/{print substr($2,6)}'` 安装 Marathon
一旦我们通过Docker将Mesos集群安装成功后,安装Marathon将变得很简单。- 启动marathon
docker run --net=host registry.dataman.io/marathon:v0.7.6 --ha --master zk://192.168.100.30:2181,192.168.100.31:2181,192.168.100.32:2181/dataman --zk_hosts 192.168.100.30:2181,192.168.100.31:2181,192.168.100.32:2181 --hostname `ifconfig eth0 | awk '/inet addr/{print substr($2,6)}'` 在浏览器中输入192.168.100.30:8080可以看到Marathon的App管理界面如下图 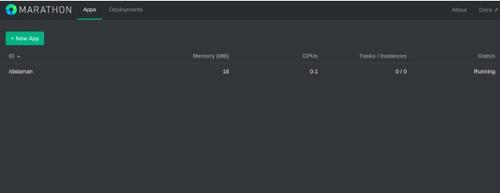
- 运行HelloWorld
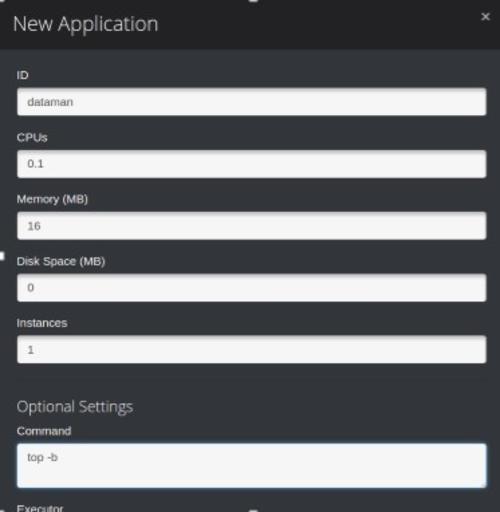
- 点击Marathon左上角的New App按钮
- 在ID里面输入App ID,例如:dataman
- 在Command输入框中输入要运行的命令,例如:top -b
- 其他配置使用默认配置,然后点击Create按钮创建第一个App
可以在Marathon的管理界面上看到dataman为running状态,证明该App正在运行。
安装 Chronos
接下来我们安装分布式定时任务管理器Chronos
- 启动chronos
docker run --net=host registry.dataman.io/chronos /usr/local/bin/chronos --master zk://192.168.100.30:2181,192.168.100.31:2181,192.168.100.32:2181/dataman --zk_hosts 192.168.100.30:2181,192.168.100.31:2181,192.168.100.32:2181 --http_port 8081'`在浏览器中输入192.168.100.30:8081可以看到Chronos的Job管理页面
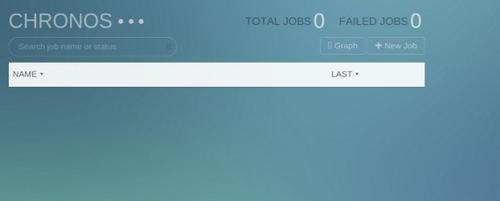
- 运行HelloWorld
- 点击Chronos管理页面右上角的New Job按钮
- 在NAME中输入Job的ID,例如:dataman
- 在COMMAND中输入Job的命令,例如:pwd
- 其他配置使用默认配置,点击Create按钮
- 点击Force Run,运行Job
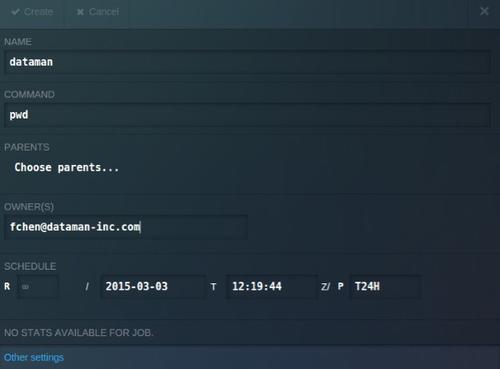
可以在Chronos中管理界面中看到dataman为绿色的success状态。
run spark-job
docker run --rm -e "MASTER=mesos://zk://192.168.100.30:2181,192.168.100.31:2181,192.168.100.32:2181/dataman" --net=host registry.dataman.io/spark-on-dataman /bin/bash -c "nginx && wget http://www.datman.io/download/examples.jar && /usr/local/share/spark/bin/spark-submit --class org.apache.spark.examples.SparkPi --conf spark.executor.uri=http://192.168.100.30/spark-on-dataman.tgz /usr/local/share/examples.jar 2"
运行结果如下图所示:
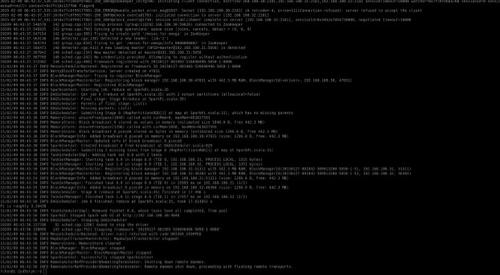
在上述的实战中,我们通过简单的辅助shell脚本,利用Docker快速的构建起了一套Mesos集群,并且成功部署了三个Mesos Framework(Marathon,Chronos,Spark),成功通过测试。
总结
Mesos作为分布式的计算平台,帮助我们快速的搭建出高可靠的大数据基础平台,由于社区的活跃度非常高,我们的工具链可以很容易的搭建出来。当然,Mesos只是一个资源调度系统,并不是一套完整的大数据处理平台,我们需要在这个平台基础之上做出定制的大数据框架才能满足用户的需求。所以,我们在定制大数据框架的过程中,遇到了一个小问题,分享给大家,欢迎大家反馈交流:
1.Spark无法使用IP进行通信,github上的issue: https://github.com/apache/spark/pull/3893 在最新的1.3.0版本中,可以通过配置SPARK_LOCAL_HOSTNAME的值为IP来解决该问题。
2.Spark运行时候生成的动态链接库.so文件无法在Spark Job跑完之后动态删除,造成了Mesos Slave硬盘爆满。这个问题,github上还没有相关的issue,我们会尝试修复它,并patch上去。最后我们采用定时自动重启Mesos Slave系统来解决这个问题。
3.还有一个问题就是Marathon的应用运行时容器无法在运行结束后干净的被清除,也没有相关工具能删除干净这类问题,并且这个问题github上也并没有相关的issue。我们现在采用手动的方式来删除已经停止的容器。
4.在chronos-2.0.1版本的时候,chronos的docker job无法启动,原因为chronos的job路径带有冒号,无法mount到docker container上,github上的issue如下: https://github.com/mesos/chronos/issues/250
通过Mesos这套框架的使用,我们已经获得了很可靠的资源管理平台,所以也帮助我们在此平台之上可以构建大数据计算平台建立了信心。所以,我们可以这么说:Mesos是我们构建新一代容器云计算Big Data Platform的最佳实践首选工具,推荐给大家。(作者:陈福/审校:刘亚琼)
作者介绍: 数人科技Core Developer,陈福, 研究方向:Spark,Mesos,Docker,Machine Learning。
正文到此结束
热门推荐










相关文章

近期评论
-
Traveling from China to Turkey becomes more manageable once you apply for the Turkey Visa for Chinese Citizens online. This process is designed to streamline entry requirements and reduce travel stress. Chinese citizens can fill out the form easily, upload the needed documents, and complete the process from home. Once the visa is approved, it's emailed directly, making it easy to carry and show when needed. The system supports efficient travel planning and helps travelers focus on the excitement of their trip. Whether you're exploring local markets or relaxing at beach resorts, secure your visa ensures everything starts on the right path.
-
已加上
-
-
??? 我的链接居然被你干掉了?
-
666 666
-
666
-
-
-
朋友,翻页到11页,及以后,会出现OOM,无法访问
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

