网易视频云:不同执行计划下Mysql多表更新结果不一致的现象
前阵子时间偶然的情况下公司里的前辈们在代码注释中留下一条有趣的SQL引发了我的兴趣, 在机缘巧合下又发现是否建立索引,建立什么样的索引会导致更新语句的结果不一致。
接下来重现这个问题:
首先 在mysql中来建立两张表 t1, t2 两张表都有两个int 字段 a和b,为两张表各自插入一条记录(10, 20)
然后有以下这样的更新语句:
update t1, t2 set t1.b = 300, t2.b = t1.b where t2.a = t1.a and t1.a = 10;
一般认为这条更新语句能够将t1表和t2表中的记录同时更改为(10, 300), 而事实结果是不是这样的呢?
我们选用了mysql-5.1.49版本进行,并按照以下情形建表进行测试:
1. create table t1 (a int, b int);
create table t2 (a int, b int);
- create table t1 (a int, b int, primary key(a));
create table t2 (a int, b int, primary key(a)); - create table t1 (a int, b int);
create index idx on t1(a);
create table t2 (a int, b int);
create index idx on t2(a);
结果1的结果: t2 表的数据没变,只有t1被更新成了(10, 300)。
这是怎么回事呢?
首先来看查询计划, 由于5.1版本不支持update语句的explain,因此我们根据 where后的条件,改写成select 语句:
explain select * from t1, t2 where t2.a = t1.a and t1.a = 10;
更新记录存放在上层的table->record 中,其中record[1] 为更新前项,record[0] 为更新后项, 于是乎问题就在于更新t2表时,record[0] 是怎么赋值的
在存储引擎的接口层打上断点,可以初步分析以上三种情形下的执行步骤:
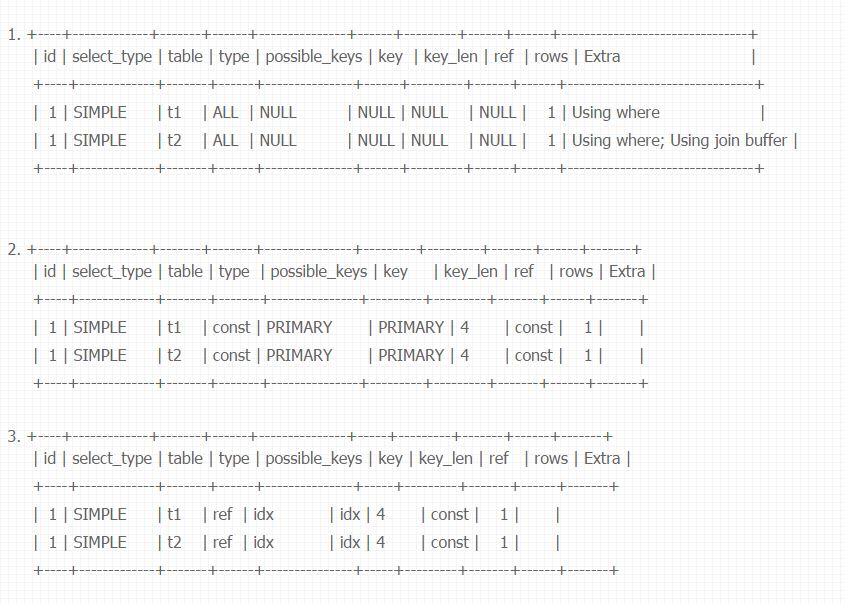
来分析case 1的执行逻辑:
1. 做t1 的全表扫描
2. 做t2的全表扫描
3. 将满足条件的t1的rowId传给上层
4. 将满足条件的t2的rowId传给上层
5. 全表扫描内表t2,没有符合条件的记录
6. 全表扫描外表t1, 没有记录了
7. 根据t1的rowId 进行postionScan
8. 更新t1 将其更新为(10. 300)
9. 根据t2的rowId进行positionScan
10. 更新t2,将其更新为(10,20)
来分析case 2的执行逻辑:
1. 做t1的索引扫描,扫描获取a,b 两列
2. 做t2的索引扫描,扫描a,b 两列
3. 更新t1表 将其更新为(10,300)
4. 根据之前join返回的ref值(rowid),对t2表做position scan
5. 更新t2表的记录,将其更新为(10,300)
来分析 case 3的执行逻辑:
join 选择 t1 为外表 t2为内表做nestloop查询
1. 做t1的索引扫描,扫描取a,b 两列的值
2. 做t2的索引扫描,扫描a,b两列的值
3. 更新 t1表的记录,将其更新为(10, 300)
4. 将满足条件的t2 的rowId 传给上层的ref
5. 继续走索引扫描查询内表t2 ,看有没有符合条件的记录,发现没有
6. 再走索引扫描查询外表t1,也没有记录
7. 根据之前返回的ref值(符合join条件的rowId),对t2表做position scan
8. 跟新t2表的记录,将其更新为(10,300)
情况1的执行计划较情况2,3有较大的不同, 而情况2和情况3相比,两张表各省略了一次索引扫描(因为主键索引是唯一索引,不需要额外的去查看是否达到查询边界)。
接下来看mysql上层是如何处理这样的查询语句的。
sql语句经过yacc解析层后, mysql会将更新后项加入一个values_for_table数组, 在本例中,数组的第一个元素,即t1表的更新后项,为一个值为1的Item_int对象, 而第二个元素,t2的更新后项,为一个指向t1表record[0] 第二个属性的指针。
在multi_update::initialize_tables方法中判断出我的主表t1是否能在join过程中直接更新掉。而此处就是导致结果不同的关键。
相关代码如下:
if (safe_update_on_fly(thd, join->join_tab, table_ref, all_tables))
{
table->mark_columns_needed_for_update();
table_to_update= table; // Update table on the fly
continue;
}
safe_update_on_fly() 方法是判断是否这张表中的一行需要读两次进行更新,如果不需要的话,直接可以在join里就更新掉。
根据代码注释的说明来看,可以直接在join里更新的条件如下:
1. 没有列在set中又需要读,又需要写
2. 做tableScan,并且数据是单文件(MYISAM)或者我们不更新聚簇索引键
3. 做一个rangescan, 并且不更新查找键或者主键
4. table不是自相交
针对我们遇到的情况来跟踪代码:
case 1 因为join类型为 JT_ALL 所以判断在set语句中 属性b 又需要读,又需要写,因此,不能在join中直接更新主表
case 2 因为join 类型为 JT_CONST 所以认为一定可以在join中直接更新主表
case 3 因为join类型为JT_REF 所以判断属性键a是否被更新,因为没有被更新,因此可以在join中直接更新主表
(join 类型就是我们查询计划中的type)
对于不能直接在join中更新的表,mysl上层会为其建立一张对应的临时表来存储更新后项,因此:
case1 有两张临时表,而case2和case3 只有一张t2表对应的临时表。
从大体的路径上来说case 1是一类, case 2、3是一类,所以以下就按照case 1和case 3进行讨论
case 2:
case2 在实际更新时,即第3步之前做了如下的事情:
store_record(table,record[1]); // 将getNext获取到的记录record[0] 拷贝到更新前项 record[1]中
if (fill_record_n_invoke_before_triggers(thd, *fields_for_table[offset], // 将更新后项填充到 record[0]中
*values_for_table[offset], 0,
table->triggers,
TRG_EVENT_UPDATE))
可见在t2填充对应的tmp_table[1]之前,t1表已经完成了对table->record[0] 的设置。
之后t2表根据新的t1表table->record[0]的值创建临时表记录插入到tmp_table[1]中。这条记录已经是300了
行至第4步做rnd_pos时填充了record[0](此时为旧项)然后通过store_record(table, record[1]) 将record[0]中的内容拷贝到 record[1] 中, 而真正的更新后项record[0]是之后从临时表中拷贝过来的。 开被 通过muti_update 类中的一个copy_field 作为一个拷贝的桥梁,桥梁两端分别指向临时表tmp_table的字段和table->record[0] 字段。 然后对tmp_table 做一次全表扫描(tmp_table 是一张 heap引擎的数据表,临时存储一些数据)将取出来的值赋为tmp_table->record[0].
case 3 与case 2非常类似,不再做详细讨论
case1:
case1 在第4步之后,会进入上层的multi_update::send_data() 方法,此方法中首先将values_for_table[0]中的后项300,插入到临时表tmp_table[0]中, 将values_for_table[1]中记录的t1表table->record[0]的内容20 插入到临时表tmp_table[1]中。至此,两张表的更新后项已经确定,之后无论t1表的table->record[0]如何改变,都不会再影响到t2表的更新后项。行至第8步之前,开始进行实际更新时, t1将对应的临时表中记录和record[0]交换。 第10步之前只是将t2对应的临时表中记录和t2 的 table->record[0]交换,得到更新后项值为20。
结论: 个人认为,MYSQL在处理多表更新时在更新前去获取真正的更新后项才是一个靠谱的时机, 而不是在目前类似case1 那样早早的存一个过程值。
现在我们知道了结果不同的原因,那可以构造更多的用例:
更新语句为 update t1, t2 set t1.b = 300, t2.b = t1.b where t2.a = t1.a and t1.a = 10 and t1.b = 20;
- create table t1 (a int, b int);
create index idx on t1(a, b);
create table t2 (a int, b int);
create index idx on t2(a, b); - create table t1 (a int, b int, );
create unique index idx on t1(a, b);
create table t2 (a int, b int);
create unique index idx on t2(a, b);
case 4 和case 3的区别在于,表上的索引包含了属性b, 而且where条件里也多了b,
case 4和case 5 的区别在于,一个是普通二级索引,一个是主键索引
基于以上理论:
case 4 在safe_update_on_fly() 判断中因为是JT_REF, 但是,属性键包含b,b是在set语句中被更新的,不能在join中直接更新主表。
因此case4的结果和case1 一样,只有t1表被更新成了(10, 300)。
case 5 case 4 在safe_update_on_fly() 判断中因为是JT_EQ_REF ,和JT_CONST一样处理,可以在join中直接更新主表,因此case5的结果和case2,case3一样,两张表都被更新成了(10,300)
总结: 这是一个不同执行计划导致更新结果不同的例子,是否能在join语句中直接更新主表记录成了一道分水岭。经过简单的验证这样的不同结果在mysql-5.5.31 , 5.6.12中一样存在。这样的不一致的结果从数据库基础理论上看过来不太可接受, 用户的一条更新语句的结果不能取决于表上加着什么索引或者走什么样的执行计划。至于这是不是一个mysql server层必须要修正的BUG,就仁者见仁了。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

