Teaching Machines to Read and Comprehend #PaperWeekly#
昨天的文章text comprehension系列的第一篇,是最近刚刚submit的文章,今天分享一篇去年的文章,也是一篇非常经典的文章。我记得Yoshua Bengio在Quora Session一个问题中推荐这篇文章。本文的题目是 Teaching Machines to Read and Comprehend ,作者是来自Google DeepMind的科学家 Karl Moritz Hermann ,是Oxford的博士后,两家机构的合作好多,很多文章都是一起写的。
本文的贡献主要有两点:一是提出了一种构建用于监督学习的阅读理解大型语料的方法,并开源在 Github 上,并且给出了两个大型语料,CNN和Daily Mail;二是提出了三种用于解决阅读理解任务的神经网络模型。
首先,聊一聊语料的构建方法。基本的思路是受启发于自动文摘任务,从两个大型的新闻网站中获取数据源,用abstractive的方法生成每篇新闻的summary,用新闻原文作为document,将summary中去掉一个entity作为query,被去掉的entity作为answer,从而得到阅读理解的数据三元组(document,query,answer)。这里存在一个问题,就是有的query并不需要联系到document,通过query中的上下文就可以predict出answer是什么,这也就失去了阅读理解的意义。因此,本文提出了用entity替换和重新排列的方法将数据打乱,防止上面现象的出现。这两个语料在成为了一个基本的数据集,后续的很多研究都是在数据集上进行训练、测试和对比。处理前和后的效果见下图:

接下来,介绍下本文的三个模型:
用神经网络来处理阅读理解的问题实质上是一个多分类的问题,通过构造一些上下文的表示,来预测词表中每个单词的概率,概率最大的那个就是所谓的答案。说起这一点,不禁想起了一个有趣的说法,任何nlp任务都可以用分类的思路来解决。
1、Deep LSTM Reader
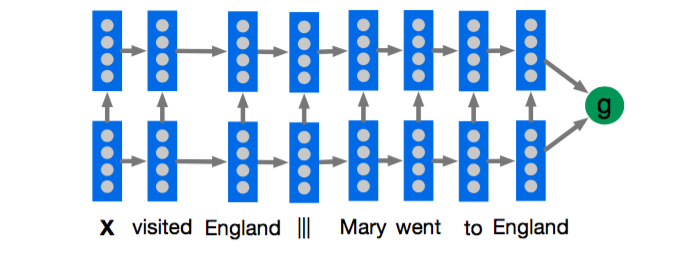
看上图,其实非常简单,就是用一个两层LSTM来encode query|||document或者document|||query,然后用得到的表示做分类。
2、Attentive Reader
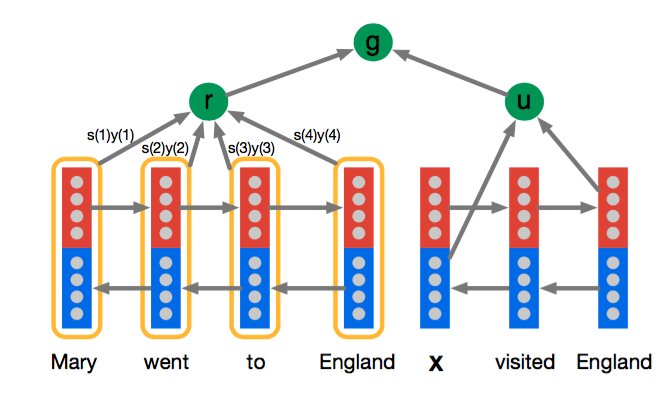
这个模型将document和query分开表示,其中query部分就是用了一个双向LSTM来encode,然后将两个方向上的last hidden state拼接作为query的表示,document这部分也是用一个双向的LSTM来encode,每个token的表示是用两个方向上的hidden state拼接而成,document的表示则是用document中所有token的加权平均来表示,这里的权重就是attention,权重越大表示回答query时对应的token的越重要。然后用document和query的表示做分类。
3、Impatient Reader
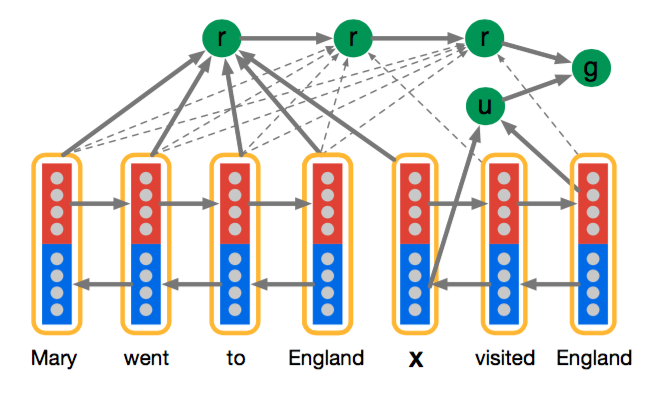
这个模型在Attentive Reader模型的基础上更细了一步,即每个query token都与document tokens有关联,而不是像之前的模型将整个query考虑为整体。感觉这个过程就好像是你读query中的每个token都需要找到document中对应相关的token。这个模型更加复杂一些,但效果不见得不好,从我们做阅读理解的实际体验来说,你不可能读问题中的每一个词之后,就去读一遍原文,这样效率太低了,而且原文很长的话,记忆的效果就不会很好了。
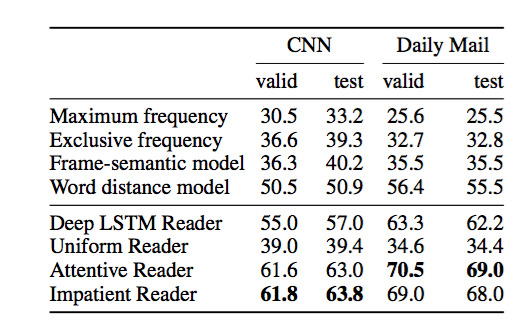
实验部分,作者选了几个baseline作为对比,其中有两个比较有意思,一是用document中出现最多的entity作为answer,二是用document中出现最多且在query中没有出现过的entity作为answer。这个和我们在实际答题遇到不会做的选择题时的应对策略有一点点异曲同工,所谓的不会就选最长的,或者最短的,这里选择的是出现最频繁的。
最终的结果,在CNN语料中,第三种模型Impatient Reader最优,Attentive Reader效果比Impatient Reader差不太多。在Daily Mail语料中,Attentive Reader最优,效果比Impatient Reader好了多一些,见下表:
开始在看语料构建方法的时候,我在想应该是用extractive的方法从原文中提取一句话作为query,但看到paper中用的是abstractive的方法。仔细想了一下,可能是因为extractive的方法经常会提取出一些带有指示代词的句子作为摘要,没有上下文,指示代词就会非常难以被理解,从而给后面的阅读理解任务带来了困难,而用abstractive的方法做的话就会得到质量更高的query。本文的最大贡献我认为是构建了该任务的大型语料,并且配套了三个神经网络模型作为baseline,以方便后面的研究者进行相关的研究,从很大地程度上推进了这个领域的发展。
工具推荐
RSarXiv 一个好用的arxiv cs paper推荐系统 网站地址 ios App下载:App Store 搜索rsarxiv即可获得
PaperWeekly,每周会分享N篇nlp领域好玩的paper,旨在用最少的话说明白paper的贡献。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

