Apache Flink fault tolerance源码剖析(六)
上篇文章我们分析了基于检查点的用户状态的保存机制——状态终端。这篇文章我们来分析 barrier (中文常译为栅栏或者屏障,为了避免引入名称争议,此处仍用英文表示)。检查点的 barrier 是提供 exactly once 一致性保证的主要保证机制。这篇文章我们会就此展开分析。
这篇文章我们侧重于核心代码分析,原理我们在这个系列的第一篇文章《Flink数据流的Fault Tolerance机制》
一致性保证
Flink的一致性保证也依赖于检查点机制。在利用检查点进行恢复时,数据流会进行 重放 ( replay )。对于有状态的 operation 以及 function ,Flink定义了检查点支持的两种模式( CheckpointingMode ):
- EXACTLY_ONCE
- AT_LEAST_ONCE
在定义该枚举时,还对这两个枚举值进行了详细的解释:
EXACTLY_ONCE
这种模式意味着系统将以如下语义对 operator 和 udf ( user defined function )进行快照:在恢复时,每条记录将在 operator 状态中只被 重现/重放 一次。
例如,如果有一个用户在一个流中应用统计元素个数的函数,该统计结果将总是跟流中的元素的真实个数一致,不管是失败还是恢复。
需要注意的是,这并不意味着每个数据 流过 streaming data flow 仅仅一次。它表示的是在恢复进行时, operators/functions 的状态被恢复(通过检查点关联的状态),使得被恢复的数据流在其状态最后一次修改之后(最新的检查点)被恰好获取一次。
并且,这里的 EXACTLY_ONCE 模式也并不保证Flink在跟外部系统交互时的行为也满足 EXACTLY_ONCE 的一致性保证(Flink只保证自己的 operator 以及 function 的状态)。虽然,通常要求在两个系统之间都达到一致性保证,但我们可以通过实现连接器来达到这样的要求(比如Apache Kafka的 offset 可以实现这个需求)。
这种模式可以支撑高吞吐,取决于数据流图以及操作,这种模式可能会增加记录处理的延迟,因为 operator 需要 对齐 他们的输入流,来保证创建一个一致的快照点。对于没有进行重新分区的简单数据流,这些延迟的增加是可以忽略不计的,而对于进行了重新分区的简单数据流,延迟的平均值很小,但最慢的记录通常有一个明显的延迟。
AT_LEAST_ONCE
这个模式意味着系统将以一种更简单地方式来对 operator 和 udf 的状态进行快照:在失败后进行恢复时,在 operator 的状态中,一些记录可能会被重放多次。
例如,如果有一个用户函数用来统计流中的元素个数,在失败后恢复时,统计值将等于或者大于流中元素的真实值。
这种模式对延迟产生的影响很小,通常应用于接收低延迟并且容忍重复消息的场景。
barrier定义
checkpoint barriers 用来在流拓扑中对齐检查点。
单个数据流视角, barrier 示意:

分布式多 input channel 视角, barrier 示意图:
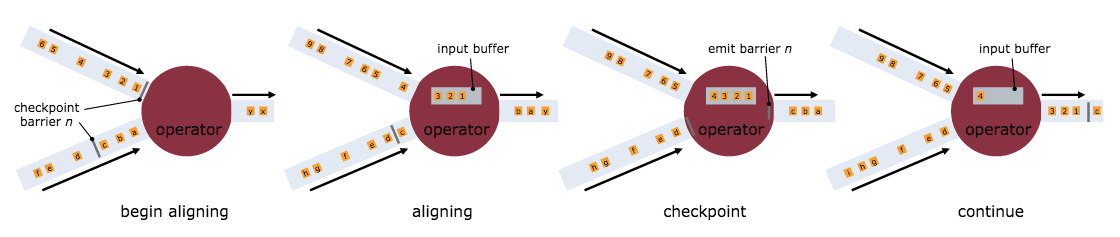
该图演示的是多barrier aligning(对齐),但只有 EXACTLY_ONCE 一致性时才会要求这一点
JobManager 将指示 source 发射 barriers 。当某个 operator 从其输入中接收到一个 CheckpointBarrier ,它将会意识到当前正处于前一个检查点和后一个检查点之间。一旦某 operator 从它的所有 input channel 中接收到 checkpoint barrier 。那么它将意识到该检查点已经完成了。它可以触发 operator 特殊的检查点行为并将该 barrier 广播给下游的 operator 。
checkpoint barrier 的ID是严格单调增长的。
CheckpointBarrier 在Flink中被看做一个运行时事件(继承自 RuntimeEvent 类)以区分普通的数据流数据( buffer ),Flink中的运行时事件必须支持序列化并且可以在 TaskManager 之间互相通信。 CheckpointBarrier 只有两个属性: id 以及 timestamp 。
barrier处理器
CheckpointBarrierHandler 定义了响应来自 input channel 中的 barrier 的处理机制,它是提供一致性保证的核心。
Flink给出了两个实现,分别是: 元素阻塞缓存机制 以及 barrier跟踪机制 。
两个关键接口方法:
- getNextNonBlocked :返回
operator可能消费的下一个BufferOrEvent。这个调用会导致 阻塞 直到获取到下一个BufferOrEvent,如果流已经完成,那么就返回null。 - registerCheckpointEventHandler : 注册一个事件回调,用来在检查点成功完成时执行。
BarrierBuffer
BarrierBuffer 用于提供 EXACTLY_ONCE 一致性保证,其行为是:它将以 barrier 阻塞输入直到所有的输入都接收到基于某个检查点的 barrier ,也就是上面所说的 对齐 。
为了避免背压输入流(这可能导致分布式的死锁), BarrierBuffer 将从被阻塞的 channel 中持续地接收 buffer 并在内部存储它们,直到阻塞被解除。
getNextNonBlocked
getNextNonBlocked 方法用于获取待 operator 处理的下一条( 非阻塞 )的记录。该方法以多种机制阻塞当前调用上下文,直到获取到下一个非阻塞的记录。
这里理解这个非阻塞非常重要,两种类型的记录是所谓的非阻塞的记录,一种是来自于上流未被标记为 blocked channel 输出的数据记录;另一种是,从已被阻塞了的缓冲区队列中激活了的缓冲区中提取出的数据记录。
这里以多种机制相结合来造成对当前调用的阻塞,直到获取到满足上面提及的非阻塞的记录,多种机制分别是:
- while(true)重复调用
- inputGate.getNextBufferOrEvent方法本身的阻塞调用
- 以及递归调用当前方法
还需要理解这里的返回值 BufferOrEvent ,因为 barrier 混入在数据流中,所以获取到的数据可能是正常的数据流 Buffer ,也可能是某种特殊的 Event ,比如这里的 barrier
分析一下 getNextNonBlocked 方法的实现
public BufferOrEvent getNextNonBlocked() throws IOException, InterruptedException {
while (true) {
// process buffered BufferOrEvents before grabbing new ones
//获得下一个待缓存的buffer或者barrier事件
BufferOrEvent next;
//如果当前的缓冲区为null,则从输入端获得
if (currentBuffered == null) {
next = inputGate.getNextBufferOrEvent();
}
//如果缓冲区不为空,则从缓冲区中获得数据
else {
next = currentBuffered.getNext();
//如果获得的数据为null,则表示缓冲区中已经没有更多地数据了
if (next == null) {
//清空当前缓冲区,获取已经新的缓冲区并打开它
completeBufferedSequence();
//递归调用,处理下一条数据
return getNextNonBlocked();
}
}
//获取到一条记录,不为null
if (next != null) {
//如果获取到得记录所在的channel已经处于阻塞状态,则该记录会被加入缓冲区
if (isBlocked(next.getChannelIndex())) {
// if the channel is blocked we, we just store the BufferOrEvent
bufferSpiller.add(next);
}
//如果该记录是一个正常的记录,而不是一个barrier(事件),则直接返回
else if (next.isBuffer()) {
return next;
}
//如果是一个barrier
else if (next.getEvent().getClass() == CheckpointBarrier.class) {
//并且当前流还未处于结束状态,则处理该barrier
if (!endOfStream) {
// process barriers only if there is a chance of the checkpoint completing
processBarrier((CheckpointBarrier) next.getEvent(), next.getChannelIndex());
}
}
else {
//如果它是一个事件,表示当前已到达分区末尾
if (next.getEvent().getClass() == EndOfPartitionEvent.class) {
//以关闭的channel计数器加一
numClosedChannels++;
// no chance to complete this checkpoint
//此时已经没有机会完成该检查点,则解除阻塞
releaseBlocks();
}
//返回该事件
return next;
}
}
//next 为null 同时流结束标识为false
else if (!endOfStream) {
// end of stream. we feed the data that is still buffered
//置流结束标识为true
endOfStream = true;
//解除阻塞,这种情况下我们会看到,缓冲区的数据会被加入队列,并等待处理
releaseBlocks();
//继续获取下一个待处理的记录
return getNextNonBlocked();
}
else {
return null;
}
}
}
processBarrier
该方法用于处理 barrier ,也是分析的重点。
//获取接收到得barrier的ID
//接收到的barrier数目 > 0 ,说明当前正在处理某个检查点的过程中
if numBarriersReceived > 0
//当前检查点的某个后续的barrierId
if barrierId == currentCheckpointId
//处理barrier
onBarrier(channelIndex);
//barrierId > 当前检查点Id
else if barrierId > currentCheckpointId
//当前的检查点已经没有机会完成了,则解除阻塞
releaseBlocks();
//跳过当前检查点,直接进入该barrier对应的检查点
currentCheckpointId = barrierId;
//处理barrier
onBarrier(channelIndex);
else
//忽略终止的检查点的barrier,barrierId < currentCheckpointId
return;
//接收到的barrier数目等于0且barrierId > currentCheckpointId
else if (barrierId > currentCheckpointId)
//说明这是一个新检查点的初始barrier
currentCheckpointId = barrierId;
onBarrier(channelIndex);
//忽略之前(跳过的)检查点的未处理的barrier
else
return;
另一段处理接收到所有 barrier 的逻辑:
//接收到barriers的数目 + 关闭的channel的数目 = 输入channel的总数目
if (numBarriersReceived + numClosedChannels == totalNumberOfInputChannels)
//触发检查点处理器回调事件
checkpointHandler.onEvent(receivedBarrier);
releaseBlocks(); //解除阻塞
onBarrier
将 barrier 关联的 channel 标识为阻塞状态同时将 barrier 计数器加一。代码:
private void onBarrier(int channelIndex) throws IOException {
if (!blockedChannels[channelIndex]) {
blockedChannels[channelIndex] = true;
numBarriersReceived++;
if (LOG.isDebugEnabled()) {
LOG.debug("Received barrier from channel " + channelIndex);
}
}
else {
throw new IOException("Stream corrupt: Repeated barrier for same checkpoint and input stream");
}
}
releaseBlocks
解除所有 channel 的阻塞,并确保刚刚写入的数据( buffer )被消费。
首先是重置状态标识:
for (int i = 0; i < blockedChannels.length; i++) {
////将所有channel的阻塞标识置为false
blockedChannels[i] = false;
}
////将接收到的barrier累加值重置为0
numBarriersReceived = 0;
接下来,
//如果当前的缓冲区中的数据为空
if (currentBuffered == null) {
// common case: no more buffered data
//初始化新的缓冲区读写器
currentBuffered = bufferSpiller.rollOver();
//打开缓冲区读写器
if (currentBuffered != null) {
currentBuffered.open();
}
}
else {
// uncommon case: buffered data pending
// push back the pending data, if we have any
// since we did not fully drain the previous sequence, we need to allocate a new buffer for this one
//缓冲区中还有数据,则初始化一块新的存储空间来存储新的缓冲数据
BufferSpiller.SpilledBufferOrEventSequence bufferedNow = bufferSpiller.rollOverWithNewBuffer();
if (bufferedNow != null) {
//打开新的缓冲区读写器
bufferedNow.open();
//将当前没有处理完的数据加入队列中
queuedBuffered.addFirst(currentBuffered);
//将新开辟的缓冲区读写器置为新的当前缓冲区
currentBuffered = bufferedNow;
}
}
BarrierTracker
BarrierTracker 会对各个 input channel 接收到的检查点的 barrier 进行跟踪。一旦它观察到某个检查点的所有 barrier 都已经到达,它将会通知监听器检查点已完成,以触发相应地回调处理。
不像 BarrierBuffer , BarrierTracker 不阻塞已经发送了 barrier 的 input channel ,所以它不能提供 exactly-once 的一致性保证。但是它可以提供 at least once 的一致性保证。
这里不阻塞 input channel ,也就说明不采用对齐机制,因此本检查点的数据会及时被处理,并且因此下一个检查点的数据可能会在该检查点还没有完成时就已经到来。所以,在恢复时只能提供 AT_LEAST_ONCE 保证。
getNextNonBlocked
还是来重点观察 getNextNonBlocked 方法:
public BufferOrEvent getNextNonBlocked() throws IOException, InterruptedException {
while (true) {
//从输入中获得数据,该操作将导致阻塞,直到获得一条记录
BufferOrEvent next = inputGate.getNextBufferOrEvent();
//null表示没有数据了
if (next == null) {
return null;
}
//这是跟BarrierBuffer的关键差别,只要它不是一个barrier,就直接返回
//不管BufferOrEvent对应的channel是否已处于阻塞状态,这里不存在缓存数据的做法,直接返回
else if (next.isBuffer() || next.getEvent().getClass() != CheckpointBarrier.class) {
return next;
}
else {
//如果是barrier,则进入barrier的处理逻辑
processBarrier((CheckpointBarrier) next.getEvent());
}
}
}
processBarrier
处理 barrier 依赖于一个内部数据结构 CheckpointBarrierCount ,该类用来对某个检查点的 barrier 做统计。
private void processBarrier(CheckpointBarrier receivedBarrier) {
// fast path for single channel trackers
//首先判断特殊情况:当前operator是否只有一个input channel
//如果是,那么就省略了统计的步骤,直接触发barrier handler回调
if (totalNumberOfInputChannels == 1) {
if (checkpointHandler != null) {
checkpointHandler.onEvent(receivedBarrier);
}
return;
}
// general path for multiple input channels
//判断通常状态:当前operator存在多个input channel
final long barrierId = receivedBarrier.getId();
// find the checkpoint barrier in the queue of bending barriers
//所有未完成的检查点都存储在一个队列里,需要找到当前barrier对应的检查点
CheckpointBarrierCount cbc = null;
int pos = 0; //对应的检查点在队列中对应的位置
for (CheckpointBarrierCount next : pendingCheckpoints) {
//如果找到则跳出循环
if (next.checkpointId == barrierId) {
cbc = next;
break;
}
//没找到位置加一
pos++;
}
//最终找到了对应的未完成的检查点
if (cbc != null) {
// add one to the count to that barrier and check for completion
//将barrier计数器加一
int numBarriersNew = cbc.incrementBarrierCount();
//如果barrier计数器等于input channel的总数
if (numBarriersNew == totalNumberOfInputChannels) {
// checkpoint can be triggered
// first, remove this checkpoint and all all prior pending
// checkpoints (which are now subsumed)
//移除pos之前的所有检查点(检查点在队列中得先后顺序跟检查点的时序是一致的)
for (int i = 0; i <= pos; i++) {
pendingCheckpoints.pollFirst();
}
// notify the listener
//触发检查点处理器事件
if (checkpointHandler != null) {
checkpointHandler.onEvent(receivedBarrier);
}
}
}
//如果没有找到对应的检查点,则说明该barrier有可能是新检查点的第一个barrier
else {
// first barrier for that checkpoint ID
// add it only if it is newer than the latest checkpoint.
// if it is not newer than the latest checkpoint ID, then there cannot be a
// successful checkpoint for that ID anyways
//如果是比当前最新的检查点编号还大,则说明是新检查点
if (barrierId > latestPendingCheckpointID) {
latestPendingCheckpointID = barrierId;
//添加进队列到末尾
pendingCheckpoints.addLast(new CheckpointBarrierCount(barrierId));
// make sure we do not track too many checkpoints
//如果超出阈值,则移除最老的检查点
if (pendingCheckpoints.size() > MAX_CHECKPOINTS_TO_TRACK) {
pendingCheckpoints.pollFirst();
}
}
}
}
小结
本篇文章剖析了Flink在 fault tolerance 时采用 checkpoint barrier 来实现多种一致性保证机制的核心代码进行了分析。
微信扫码关注公众号:Apache_Flink

QQ扫码关注QQ群:Apache Flink学习交流群(123414680)
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

